From Chaos to Care: Structuring LLMs with Clinical Guidelines
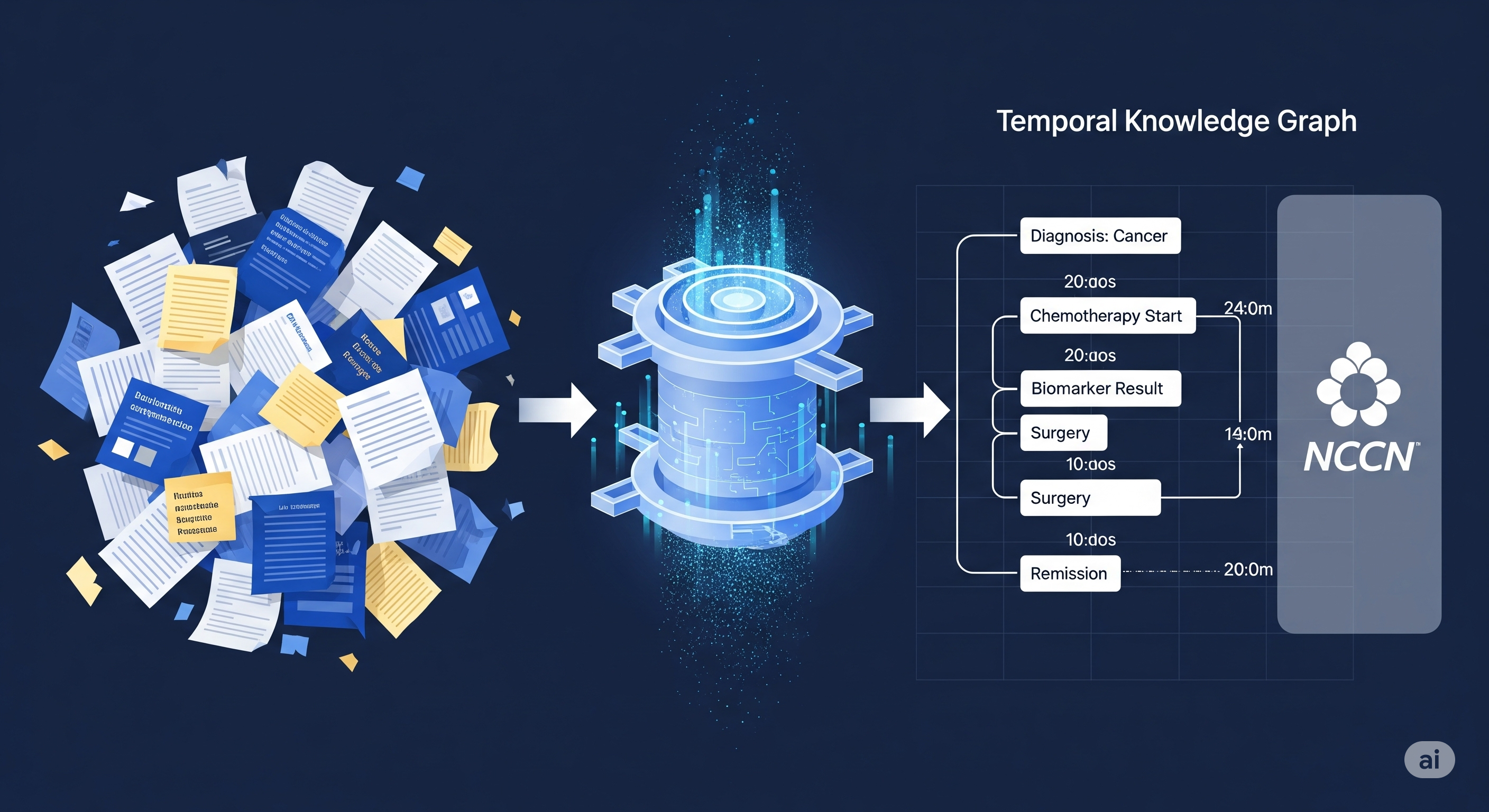
TL;DR for operators Patient records are not just long documents. They are timelines with consequences. CliCARE, the framework proposed in the paper, attacks that problem by turning longitudinal cancer EHRs into patient-specific temporal knowledge graphs, then aligning those patient trajectories with clinical guideline knowledge graphs before asking an LLM to generate a clinical summary and recommendation.1 That sounds architectural because it is. The useful lesson is not that “AI can help doctors,” a phrase now so overused it should probably be placed in quarantine. The lesson is that clinical AI improves when the model is given a structured representation of disease progression and a normative map of what should happen next. ...