TL;DR for operators
Patient records are not just long documents. They are timelines with consequences.
CliCARE, the framework proposed in the paper, attacks that problem by turning longitudinal cancer EHRs into patient-specific temporal knowledge graphs, then aligning those patient trajectories with clinical guideline knowledge graphs before asking an LLM to generate a clinical summary and recommendation.1 That sounds architectural because it is. The useful lesson is not that “AI can help doctors,” a phrase now so overused it should probably be placed in quarantine. The lesson is that clinical AI improves when the model is given a structured representation of disease progression and a normative map of what should happen next.
The paper tests CliCARE on two 2,000-patient cancer datasets: a private Chinese CancerEHR dataset from Liaoning Cancer Hospital and a processed English MIMIC-Cancer dataset derived from MIMIC-IV. The headline result is that CliCARE generally outperforms standard RAG, BriefContext, KG-enhanced RAG variants, and direct standard-RAG use of several major models. The gains are especially large on the more complex CancerEHR records, where standard retrieval is most likely to lose the plot.
For hospitals, oncology software vendors, and clinical AI teams, the operational takeaway is straightforward: do not start by buying a longer-context chatbot and calling it “decision support.” Build the workflow first. Extract patient timelines. Maintain guideline logic. Align patient states to guideline paths. Generate summaries and recommendations from that structured context. Then evaluate outputs with a rubric clinicians actually recognise.
The uncertainty is also clear. This is not a prospective clinical trial. It does not prove improved patient outcomes. It evaluates generated summaries and recommendations retrospectively, with an expert-validated LLM-as-judge protocol that correlates with oncologist ratings. Useful, but not the same thing as safely running inside a hospital.
The real bottleneck is not context length. It is clinical sequence.
A familiar story goes like this: EHRs are too long, so we need bigger context windows. Once the model can ingest the whole record, it will reason correctly. A comforting story. Also a little too neat, which is usually where trouble begins.
Cancer care is not a pile of facts. It is a sequence of diagnosis, staging, biomarkers, imaging, surgery, chemotherapy, recurrence, adverse events, changing treatment intent, and guideline-dependent next steps. Two notes can contain the same entities and imply different decisions depending on order. “Progression after treatment” is not the same as “treatment after progression.” Medicine, inconveniently, believes in time.
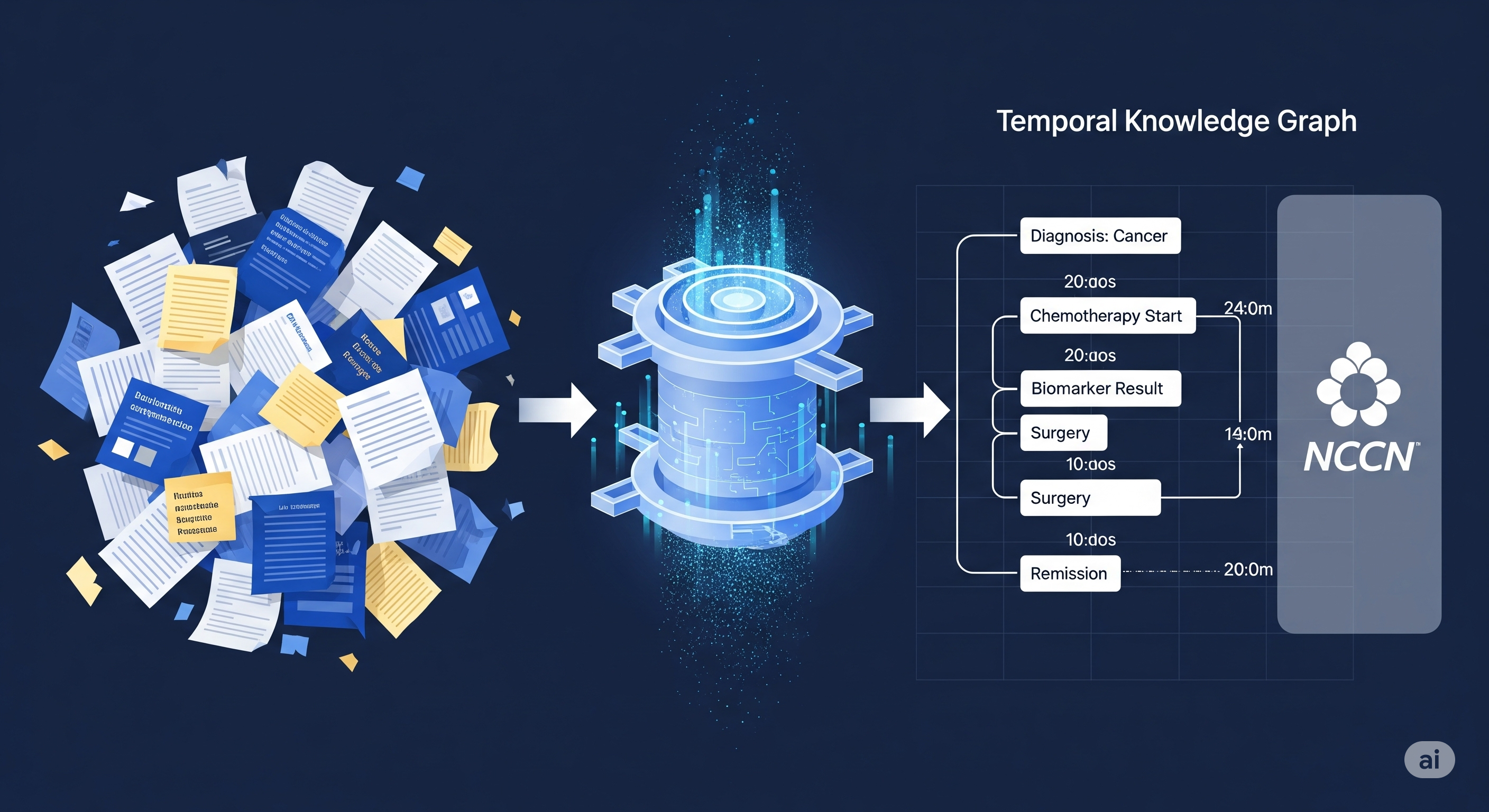
That is why CliCARE is better understood as a workflow architecture than as a model trick. It starts by compressing and structuring the record, not by blindly retrieving snippets. The paper’s pipeline separates the most recent clinical note from historical records, uses a Longformer-based extractive summarisation step for the historical material, and then extracts clinical events such as diagnostic confirmation, staging changes, treatment regimens, biomarker trends, and imaging assessments. Those events become a temporal knowledge graph, where patient facts are linked to standard biomedical concepts and anchored to time.
This is the first important shift: the model is no longer asked to infer the patient journey from scattered text every time. The journey is made explicit.
The second shift is guideline alignment. CliCARE constructs a static guideline knowledge graph from clinical practice guidelines, representing normative concepts such as cancer type, clinical situation, and treatment. It then enumerates possible guideline paths and compares them with the patient trajectory. BERT-based semantic similarity produces candidate alignments. An LLM reranks those candidate paths for clinical plausibility. A bootstrapping expansion stage then extends high-confidence alignments to cover additional patient events.
In plain terms: the system asks not only “what happened to this patient?” but also “which guideline pathway does this history most resemble, and where does the current case sit inside that pathway?”
That is the mechanism. It matters more than the benchmark table.
Standard RAG retrieves fragments. CliCARE aligns processes.
Standard RAG is attractive because it is simple: index documents, retrieve relevant chunks, send them to a model, generate an answer. In many enterprise settings, that is a perfectly reasonable starting point. In oncology, it is often a polite way to create a well-cited mess.
A retrieved chunk might include the patient’s earlier treatment. Another chunk might include a later imaging result. A third might include a guideline passage. The LLM still has to reconstruct the sequence, infer the relationship among events, and determine whether the guideline condition applies. That is a lot to outsource to text adjacency.
KG-enhanced RAG improves the situation by retrieving graph structures or knowledge paths, but the paper argues that generic graph retrieval still struggles when the core issue is longitudinal dependency: how the patient’s disease and treatment course evolved over time.
CliCARE’s design is more demanding. It creates a patient temporal graph and a guideline graph, then aligns them. That alignment step is the difference between retrieval and clinical workflow modelling.
| Approach | What it gives the model | What can still go wrong |
|---|---|---|
| Standard RAG | Relevant text fragments from EHRs or guidelines | Missing temporal dependencies; fragmented evidence; hallucinated sequencing |
| KG-enhanced RAG | Structured knowledge paths or graph context | May still lack patient-specific longitudinal alignment |
| Long-context prompting | More raw text in the prompt | More room to search, not necessarily more clinical structure |
| CliCARE | Patient trajectory aligned to guideline pathway | Requires reliable extraction, maintained guidelines, and validated alignment |
The business translation is not subtle. If the clinical question depends on sequence and guideline state, retrieval alone is not governance. It is a supply chain for context. Governance begins when the organisation controls how facts are extracted, how they are ordered, how they map to standards, and how generated recommendations are checked.
Yes, this is more work than a chatbot wrapper. Hospitals tend to be like that.
What the paper directly tests
The experiments evaluate two generation tasks. The first is a retrospective clinical summary: can the system synthesise the patient’s history accurately and completely? The second is a prospective clinical recommendation: can it produce a clinically sound and actionable next-step recommendation?
The datasets are deliberately different. CancerEHR is a private Chinese dataset containing longitudinal records for 2,000 patients from Liaoning Cancer Hospital. The records include physicians’ orders, laboratory results, surgical notes, and other material; some span more than two decades and reach very long input lengths. The processed MIMIC-Cancer dataset is also built from 2,000 cancer patients, but from public English MIMIC-IV data, filtered and processed into patient-centric clinical narratives. The paper uses Chinese cancer guidelines for the Chinese dataset and international sources such as NCCN and ESMO for MIMIC-Cancer.
This setup is useful because it tests more than one language and record style. It is not enough to prove universal generalisation, but it is better than a single tidy benchmark pretending to be a hospital.
The baselines include standard RAG with open-source models, BriefContext, MedRAG, KG2RAG, GNN-RAG, and model comparisons involving Qwen-3-8B, Gemini 2.5 Pro, GPT-4.1, Deepseek-R1, Claude-4.0-Sonnet, Mistral variants, and BioMistral. The framework is tested both as a structured context method for strong generalist models and as a way to support smaller specialist models.
The evaluation is also part of the contribution. Instead of relying mainly on BLEU or ROUGE, the authors build an expert-validated LLM-as-judge protocol. The rubric scores outputs from 1 to 5 across factual accuracy, completeness and thoroughness, clinical soundness, and actionability and relevance. The judge is an ensemble of GPT-4.1, Claude 4.0 Sonnet, and Gemini 2.5 Pro, with randomised ordering to reduce positional bias. The authors validate this automated judge against three experienced oncologists on a sampled subset.
That last piece matters because medical generation is not a spelling contest. A recommendation can have excellent lexical overlap with a reference answer and still be clinically daft. Medicine remains annoyingly resistant to ROUGE worship.
The main evidence: structure helps most when the record is messiest
The strongest pattern in the paper is that CliCARE’s gains are largest on the more complex CancerEHR dataset.
For Qwen-3-8B on CancerEHR, standard RAG scores 1.485 for clinical summary and 1.527 for clinical recommendation. CliCARE raises those to 3.173 and 3.215. That is not a marginal polish. It is the difference between a weak, barely usable generation setup and something much closer to a clinically meaningful draft.
For Gemini 2.5 Pro on CancerEHR, standard RAG scores 2.735 and 2.818, while CliCARE reaches 4.976 and 4.965. BriefContext and MedRAG are already strong in that setting, but CliCARE still sits above them on the main CancerEHR scores reported in the paper.
The MIMIC-Cancer results are more nuanced. Gains still appear, but they are smaller. For GPT-4.1, CliCARE improves standard RAG from 4.419 to 4.737 on clinical summary, and from 4.429 to 4.676 on clinical recommendation. With Gemini 2.5 Pro, CliCARE improves over standard RAG on MIMIC-Cancer, but MedRAG slightly beats it on the clinical summary score in the baseline comparison table. This is not a scandal. It is a clue.
The clue is that structure is most valuable where raw context is most chaotic. When records are shorter, cleaner, or already easier for a model to process, the marginal gain from temporal graph construction and alignment can shrink. When records are long, multilingual, fragmented, and clinically dense, structure becomes less of a nice-to-have and more of a survival mechanism.
| Result category | What the paper shows | Operational interpretation | Boundary |
|---|---|---|---|
| CancerEHR main results | Large gains for CliCARE over standard RAG and graph-RAG baselines | Temporal structure and guideline alignment help most in complex longitudinal records | Private Chinese dataset; external replication needed |
| MIMIC-Cancer results | Smaller but generally positive gains over standard RAG | Cleaner or different record structures may reduce the visible uplift | Not every baseline is beaten on every metric |
| Strong generalist models | Gemini, GPT-4.1, Deepseek-R1 often benefit from CliCARE context | Better models still need better scaffolding | Model APIs create cost and privacy constraints |
| Smaller/open models | Qwen-3-8B gains sharply on CancerEHR | Structured pipelines may make local deployment more viable | Absolute performance can remain below frontier models |
This is the business-relevant result: CliCARE does not merely ask whether a bigger model is smarter. It asks whether the organisation can make the clinical problem easier for the model to reason over.
That is usually where real AI systems are won or lost.
The ablations show which parts are doing the work
The ablation study is not a second thesis. Its purpose is narrower: remove components and see whether the framework still holds.
The paper removes three parts: alignment expansion, LLM-based reranking, and TKG-based compression. On CancerEHR, removing any of them hurts performance, especially for the stronger Gemini setup. That supports the paper’s core mechanism claim: the full pipeline matters when records are complex.
The MIMIC-Cancer ablations are more interesting because they are less obedient. For Qwen-3-8B, removing TKG-based compression produces MIMIC-Cancer scores of 2.475 and 2.467, which are close to the full CliCARE scores of 2.575 and 2.544 and much better than removing expansion or reranking. The paper interprets this as evidence that aggressive compression can be counterproductive for shorter or simpler records.
That is an important operational warning. Data engineering can improve clinical reasoning, but it can also erase signal. Compression is not automatically virtuous because it appears in a pipeline diagram. A hospital deploying this kind of system would need monitoring by record length, tumour type, documentation quality, and clinical task. The correct compression setting for a 20-year oncology record may not be the correct setting for a compact ICU-derived cancer trajectory.
The length analysis reinforces this. Qwen-3-8B declines on the longest CancerEHR records, even within the CliCARE framework. Gemini 2.5 Pro remains more stable and performs strongly across record lengths, reaching its highest reported scores on the longest segments for both datasets. Structure helps, but model capacity still matters. Architecture does not abolish capability gaps; it manages them.
The appendix metrics are sanity checks, not clinical truth
The appendix reports BLEU and ROUGE results. This is useful, but mostly because it shows why those metrics should not drive clinical evaluation.
Some lexical metrics do not move in the same direction as the clinical judge scores. In the ablation table using NLP metrics, versions without alignment expansion or reranking can show stronger BLEU/ROUGE values than full CliCARE on CancerEHR, even though the clinical evaluation favours the complete framework. That is exactly the point. A response can resemble the reference text more closely while being less clinically sound under expert-oriented criteria.
For product teams, this distinction is not academic. If a vendor optimises the system for lexical overlap, it may produce answers that look familiar rather than answers that are safe, complete, and actionable. Familiarity is not validity. It is just déjà vu with a dashboard.
The paper’s LLM-as-judge protocol is an attempt to scale better evaluation. The reported Spearman correlations between the LLM judge average and mean physician scores are around 0.65 to 0.70 across the two datasets and two tasks. The authors interpret this as strong enough to use the automated judge for large-scale comparisons. That seems reasonable as a research protocol, provided we do not confuse it with regulatory-grade assurance.
An LLM judge validated against three oncologists is better than ROUGE alone. It is not a replacement for prospective clinical safety evaluation, local governance, audit trails, or post-deployment monitoring. The correct phrase is “useful proxy,” not “mission accomplished.” Small wording difference, large lawsuit difference.
What this means for clinical AI buyers
The paper’s practical message is not “choose CliCARE as a product.” It is “look for this class of workflow.”
A hospital or oncology platform evaluating clinical AI should ask four questions before being impressed by model branding.
First, does the system build a patient timeline, or does it merely retrieve chunks? In oncology, the difference is fundamental. A good system should know which events happened before or after treatment, not just which documents contain relevant words.
Second, does it map the patient state to guideline logic? Clinical guidelines are not ordinary documents. They are conditional pathways. If a system treats them as static text snippets, it may retrieve the right paragraph and still apply it to the wrong patient state.
Third, can the guideline layer be updated? CliCARE’s paper emphasises that the guideline knowledge graph can be expanded as new evidence and guidelines appear. That is not a minor implementation detail. In real clinical operations, stale guidelines are not technical debt. They are safety debt.
Fourth, how is the system evaluated? A demo answer that sounds fluent is cheap. A rubric covering factual accuracy, completeness, clinical soundness, and actionability is better. Correlation with clinician judgement is better still. Prospective monitoring in the deployment environment is the adult version.
| Buyer question | Good answer | Red flag |
|---|---|---|
| How do you handle long EHRs? | Patient-centric temporal extraction and structured chronology | “We use a very long context window” |
| How do you use guidelines? | Formal guideline graph or equivalent pathway logic | “We retrieve relevant guideline PDFs” |
| How do clinicians validate output? | Expert rubric, sampled review, bias-controlled evaluation | “Doctors liked the demo” |
| How do you update medical knowledge? | Versioned guideline maintenance and auditability | “The model knows medicine” |
| What does the system recommend? | Evidence-linked summary and next-step suggestions for clinician review | Autonomous treatment decisions |
The last row deserves emphasis. CliCARE generates decision support, not autonomous care. The user of the system is an oncologist. The output is a summary and recommendation to support expert workflow. Any vendor quietly sliding from “support” to “replacement” should be escorted back to procurement, preferably with supervision.
The business value is workflow leverage, not chatbot theatre
The commercial opportunity here is not a magical doctor-in-a-box. It is workflow leverage in high-friction clinical settings.
Oncology teams spend serious cognitive labour reconstructing patient history from fragmented records. If a system can produce a faithful, guideline-grounded draft summary and plausible next-step recommendation, the value is not only time saved. It is reduced review burden, better continuity, more consistent documentation, and potentially stronger multidisciplinary coordination.
For software vendors, this points toward a layered product architecture:
- Data consolidation layer: patient-centric ingestion from hospital systems, lab reports, imaging summaries, orders, and notes.
- Temporal structuring layer: event extraction, entity linking, timestamp handling, and disease trajectory modelling.
- Guideline layer: maintained clinical pathway knowledge graphs with version control.
- Alignment layer: mapping patient trajectories to guideline states and candidate pathways.
- Generation layer: summary and recommendation drafting with evidence links.
- Evaluation layer: clinician rubric, automated judge proxy, sampling review, and audit logs.
This is less glamorous than a single prompt. It is also closer to what hospitals can actually govern.
There is a second implication for deployment economics. The paper suggests that structured context can improve smaller models, especially Qwen-3-8B on the complex CancerEHR dataset. That matters because healthcare organisations often face cost, latency, and privacy constraints with closed frontier APIs. If structuring allows a locally deployed model to perform acceptably for some tasks, the ROI calculation changes.
But the evidence does not say small models are now universally enough. The strongest absolute results often involve powerful generalist models. The right reading is more restrained: structure can make local or specialist models more viable, while strong generalist models still benefit from the same scaffolding.
Where the result stops
The paper is useful because it is specific. Its limitations are specific too.
It is oncology-focused. The framework may transfer to other specialties, but the guideline-pathway logic is especially natural in cancer care, where staging, biomarkers, treatment lines, and progression create structured decision pathways. Applying the same method to emergency medicine, psychiatry, or primary care would require different ontologies, guideline representations, and evaluation rubrics.
It is retrospective. The paper evaluates generated summaries and recommendations against expert-authored labels and clinician ratings. That is valuable, but it does not show that clinicians using CliCARE make better decisions, save measurable time, reduce adverse events, or improve patient outcomes.
One dataset is private. CancerEHR is clinically important because it captures messy real-world longitudinal data, but its non-public status limits independent replication. The MIMIC-Cancer dataset helps with generalisability, yet MIMIC-derived data has its own institutional and documentation patterns.
The evaluation proxy is promising but not final. Spearman correlations around 0.65 to 0.70 between the LLM judge and mean physician scores support scalable research evaluation. They do not eliminate the need for human review, local calibration, safety cases, and regulatory scrutiny.
The pipeline also depends on extraction quality. If event extraction misses a biomarker result, misorders a treatment line, or links an entity incorrectly, the aligned guideline path may be wrong. Structured errors can be more dangerous than unstructured ambiguity because they look clean.
That is the quiet danger of knowledge graphs in medicine: the graph can make uncertainty look official.
The broader lesson: clinical AI needs scaffolding before autonomy
CliCARE is best read as a rebuttal to lazy long-context thinking. More tokens help. The appendix context-length experiment suggests longer context can improve performance. But context length is not clinical reasoning. It is capacity. Without structure, the model still has to infer chronology, relevance, guideline state, and next-step logic from a swamp of text.
The paper’s more durable contribution is the architecture: convert patient histories into temporal structure, align them with prescriptive guidelines, generate clinician-facing outputs, and validate with a clinically meaningful rubric. The strongest results appear where that architecture is most needed: complex longitudinal cancer records.
For operators, the next move is not to wait for a model with an even more heroic context window. It is to build the boring machinery around the model: timelines, ontologies, guideline versions, alignment checks, review workflows, and evaluation protocols.
Medicine does not need an LLM that sounds like an oncologist after reading 20,000 tokens. It needs systems that help oncologists see the patient journey clearly, apply guidelines responsibly, and catch the model when it gets clever in the wrong direction.
That is less cinematic than autonomous AI. It is also far more useful.
Cognaptus: Automate the Present, Incubate the Future.
-
Dongchen Li, Jitao Liang, Wei Li, Xiaoyu Wang, Longbing Cao, and Kun Yu, “CliCARE: Grounding Large Language Models in Clinical Guidelines for Decision Support over Longitudinal Cancer Electronic Health Records,” arXiv:2507.22533. ↩︎