TL;DR for operators
Enterprise RAG teams often treat retrieval quality as a graph-construction problem: extract more entities, more relationships, more summaries, and hope the answer appears somewhere in the resulting machinery. Clue-RAG suggests a more useful diagnosis: the failure is often not that the graph is too small, but that the system has chosen the wrong semantic unit for the job.1
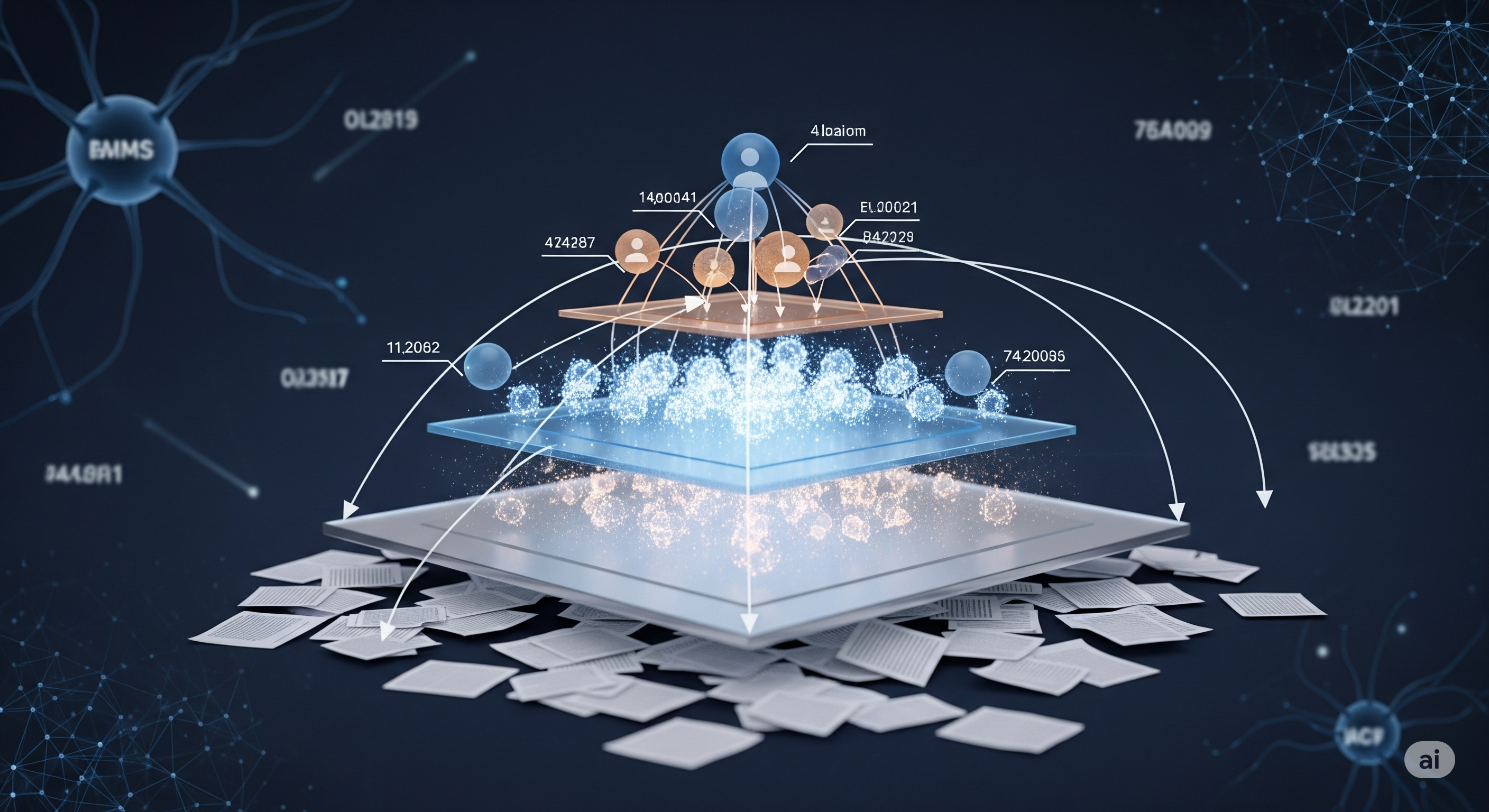
The paper introduces a graph-based RAG system built around three layers: original text chunks, atomic knowledge units, and entities. Chunks preserve source context. Knowledge units preserve individual facts. Entities give the system handles for traversal. The retrieval pipeline then moves across these layers rather than pretending one representation can do everything.
The headline numbers are strong. Across three multi-hop QA benchmarks and two LLM backends, Clue-RAG-1.0 reaches the best average F1 and accuracy among the compared systems. Against KETRAG, the paper reports a 21.53% improvement in average F1. Against SIRERAG, it reports a 5.75% improvement in average accuracy. The accepted planning figure still matters too: the authors report up to 99.33% higher Accuracy, 113.51% higher F1, and 72.58% lower indexing cost in their broader comparison framing. Good, but not magic; benchmark QA is not the same thing as a production legal, finance, or customer-support corpus with permissions, versioning, and humans angrily waiting in Slack.
The most operationally interesting part is not the full-token version. It is Clue-RAG-0.5 and Clue-RAG-0.0. The 0.5 variant processes only half the indexing token budget with an LLM and still achieves 94.95%–100.51% of the full-token version’s performance in the hybrid extraction experiment. The 0.0 variant uses no LLM during indexing and still beats or matches strong baselines on average. Translation: the retrieval architecture itself is doing real work. The LLM is not merely wearing a hard hat while the graph does nothing.
For business use, the lesson is clear: stop measuring RAG maturity only by the sophistication of your graph extraction prompt. Measure whether your retrieval system preserves the right granularity, controls ambiguity, uses the query during traversal, and knows when more context becomes noise.
The usual GraphRAG bargain is expensive and slightly leaky
Graph-based RAG has an attractive promise. Instead of retrieving chunks by embedding similarity and dumping them into a prompt, the system can organise a corpus around entities, relations, communities, trees, or other structured forms. That should help with multi-hop questions, where the answer requires connecting evidence across documents.
The problem is that the graph is not the document.
A knowledge graph built from text usually extracts only part of the original information. It may capture that one entity relates to another, while missing a comparison, a qualifier, a temporal detail, or a descriptive clause that matters later. In the paper’s framing, existing graph-based methods suffer from incompleteness: nodes and edges omit useful information that does not fit cleanly into triples or graph attributes.
This is not a small engineering annoyance. It changes the failure mode. If a relevant fact never enters the graph, graph traversal cannot retrieve it. The system can be impressively structured and still blind in a very organised way.
The second problem is semantic misalignment during retrieval. Many graph RAG systems use the query to find a starting point, then let graph expansion retrieve connected material. That sounds reasonable until the expansion drifts. The first hop may be query-relevant; later material may be graph-neighbour-relevant but answer-irrelevant. The graph has followed its own social life.
Clue-RAG’s contribution is to attack both problems mechanically. It does not merely say “build a better graph.” It changes what the graph contains and how the query controls movement through it.
Knowledge units are the missing middle layer
Clue-RAG’s index, called Clue-Index, is a multi-partite graph with three node types:
| Layer | What it stores | Why it exists |
|---|---|---|
| Text chunks | Original passages from the corpus | Preserve source context for final answer generation |
| Knowledge units | Atomic statements extracted from chunks | Preserve granular facts that triples may drop |
| Entities | Named entities extracted from knowledge units | Provide anchors for retrieval and graph traversal |
This is a useful design because each layer compensates for a weakness in the others.
Chunks are rich but coarse. They contain context, but they are noisy retrieval targets when the question needs one specific fact.
Entities are precise but thin. They help traversal, but they do not contain enough meaning by themselves.
Knowledge units sit between them. They are intended to express single, interpretable facts, such as “Jesús Aranguren won two Copa del Rey trophies with Athletic Bilbao,” rather than leaving the system to infer that detail from a chunk or reduce it to a brittle triple. The paper’s appendix prompt explicitly pushes the LLM to simplify compound sentences, separate entity descriptions, resolve pronouns, and output independent factual units. That prompt detail matters. It reveals what the authors are really optimising for: not literary elegance, but retrieval-ready semantic atoms.
This is also where the reader misconception needs correction. Clue-RAG is not arguing that the next stage of GraphRAG is simply a bigger, more LLM-generated graph. It is arguing that a graph built only from entities and relationships is often the wrong abstraction. The intermediate knowledge unit keeps more of the text’s factual content available without forcing every useful detail into a formal edge.
That is a very practical insight. Many enterprise documents are full of exceptions, thresholds, definitions, process clauses, and procedural conditions. “Vendor X is approved” is one thing. “Vendor X is approved only for projects under $250,000 unless regional procurement signs off” is the part that gets people fired. A triple-first representation is not always kind to such nuance.
The hybrid extraction strategy is a cost-control mechanism, not a decorative optimisation
Extracting high-quality knowledge units with an LLM is expensive. Doing it across every chunk in an enterprise corpus would be the kind of architecture diagram that looks elegant until finance sees the indexing bill.
Clue-RAG therefore introduces hybrid extraction. Some chunks are processed by an LLM to produce context-disambiguated knowledge units. Other chunks are handled by lightweight NLP tools, mainly sentence segmentation. Entities are then extracted with spaCy NER.
The selection logic is important. The authors treat contextual ambiguity as the reason to spend LLM tokens. If two chunks are semantically similar, sentence-level units from those chunks may look similar while meaning different things. The paper illustrates this with two extracted sentences whose cosine similarity is high under simple NLP extraction, while LLM-extracted units become more context-specific and less confusable.
Since there is no oracle that tells the system exactly which chunks are ambiguity-prone, Clue-RAG uses similarity as a proxy and frames chunk selection as a 0-1 knapsack problem. Each chunk has a value, representing relevance or ambiguity signal, and a weight, represented by token length. The system selects chunks for LLM processing under a token budget.
The paper tests random selection, cosine-based selection, and BLEU-based selection for the 50% token-budget version. BLEU performs best on average, but the difference versus cosine is small in the reported table. Random selection is weaker. The useful business interpretation is not “BLEU is now the universal enterprise RAG selector.” Please do not start a procurement meeting with that sentence. The better reading is that selection quality matters: if you only have budget to process part of the corpus with an LLM, choose the part where disambiguation is likely to pay.
The hybrid result is the most commercially relevant part of the indexing story. Clue-RAG-0.5 reaches 94.95%–100.51% of Clue-RAG-1.0’s performance while using half the indexing token budget. On some MuSiQue settings, the half-token version even outperforms the full-token version. The authors suggest that some questions align better with original lexical phrasing than with LLM-paraphrased knowledge units. That is a useful reminder: LLM “cleaning” can occasionally wash away the exact term the retriever needed.
Q-Iter keeps the query in the loop instead of letting the graph wander
The second half of Clue-RAG is Q-Iter, the online retrieval algorithm. This is where the mechanism-first framing earns its keep. Without understanding Q-Iter, the results look like another leaderboard entry. With Q-Iter, the gains become more interpretable.
Q-Iter has three broad phases.
First, it performs entity anchoring. The system extracts entities from the query using an LLM, matches them to entity nodes in the graph, and also performs semantic search over knowledge units. The paper divides this into two components: Spreading Activation and Knowledge Anchoring. Spreading Activation starts from query entities and finds related entity nodes. Knowledge Anchoring retrieves semantically similar knowledge units and adds their entities to the seed set.
This dual start matters because queries can be under-specified. A query may mention an event, a title, or a partial entity rather than the final answer entity. Semantic search over knowledge units helps reveal additional anchors.
Second, Q-Iter performs iterative retrieval. It moves between entity nodes and knowledge-unit nodes, retrieving candidate units at each depth. It uses a beam size to limit expansion and a lightweight re-ranker to score accumulated evidence against the query. This is not a free-form graph walk. It is constrained, ranked, and repeatedly checked against the question.
Third, it maps the selected knowledge units back to their original chunks and re-ranks those chunks for the final generation prompt. This final mapping is easy to overlook, but it is operationally sensible. Knowledge units are good retrieval handles; chunks are better answer context. The system does not ask the generator to answer from detached facts alone.
The clever detail is query updating. As Q-Iter retrieves knowledge units, it updates the query embedding by subtracting the embedding of already selected units. The purpose is to shift attention away from evidence already covered and toward missing information. In plain terms: once the system has found one clue, it changes the retrieval pressure to look for the next clue rather than five paraphrases of the first one.
That is exactly the kind of mechanism multi-hop retrieval needs.
The main evidence says the architecture matters before the LLM budget does
The paper evaluates Clue-RAG on MuSiQue, HotpotQA, and 2WikiMultiHopQA, using 1,000 validation questions per dataset. It tests two answer-generation models, LLaMA3.0-8B and Qwen2.5-32B. It compares against simple baselines, graph-based baselines, and tree-based baselines: Zero-shot, VanillaRAG, GraphRAG local search, several LightRAG modes, HippoRAG, KETRAG, RAPTOR, and SIRERAG.
The overall table is dense, but the pattern is simple:
| System family | What the comparison tests | What the result implies |
|---|---|---|
| Zero-shot and VanillaRAG | Whether retrieval structure helps beyond direct generation or vector retrieval | Structured retrieval is necessary for these multi-hop tasks |
| Graph baselines | Whether existing graph RAG methods solve the same problem | Clue-RAG’s chunk-unit-entity structure and Q-Iter outperform graph-only alternatives on average |
| Tree baselines | Whether hierarchical passage organisation is enough | Tree organisation helps, but does not replace query-driven graph traversal |
| Clue-RAG variants | Whether LLM indexing budget drives the whole result | The architecture remains strong even with reduced or zero LLM indexing |
Clue-RAG-1.0 reports average F1 of 45.76 and average accuracy of 48.46 across the displayed settings. Clue-RAG-0.5 reports average F1 of 44.92 and average accuracy of 47.73. Clue-RAG-0.0 reports average F1 of 42.56 and average accuracy of 45.73.
Those numbers are not just incremental against weak baselines. KETRAG, one of the strongest graph baselines, reports average F1 of 37.66 and average accuracy of 37.52. SIRERAG, the strongest tree baseline by average accuracy, reports average F1 of 27.91 and average accuracy of 45.83. Clue-RAG-0.0, without LLM indexing, still exceeds KETRAG in average F1 and roughly matches SIRERAG’s average accuracy.
That result is the paper’s quiet insult to brute-force LLM indexing. If a zero-indexing-token variant remains competitive, then much of the value is coming from representation design and retrieval dynamics, not merely from asking an LLM to pre-digest the corpus.
The cost evidence reinforces the point. Compared with KETRAG, Clue-RAG-0.5 reduces token costs by up to 9.41% during offline indexing and up to 83.87% during online retrieval. Clue-RAG-0.0 removes LLM usage during indexing entirely and reduces online retrieval token costs by up to 82.92% versus KETRAG and 56.06% versus SIRERAG. This is the part procurement can understand without pretending to enjoy graph theory.
The ablation table shows which retrieval pieces do the heavy lifting
The ablation study is not a second thesis. It is a component stress test. The paper removes three parts of Q-Iter:
| Component | Likely purpose of test | Reported effect | Interpretation |
|---|---|---|---|
| Spreading Activation | Tests entity-based query anchoring | Removing it lowers average F1 from 45.76 to 41.79 and accuracy from 48.46 to 44.08 | Entity-level alignment is the strongest Q-Iter component |
| Knowledge Anchoring | Tests semantic-search anchoring over knowledge units | Removing it lowers average F1 to 43.44 and accuracy to 46.23 | Semantic anchoring adds useful coverage beyond entity matching |
| Query Updating | Tests whether retrieval should shift after evidence is found | Removing it lowers average F1 to 45.03 and accuracy to 47.83 | Helpful but smaller average contribution; can be dataset-sensitive |
Spreading Activation contributes the most in the ablation. The authors attribute this to semantic granularity alignment: entities extracted from the query are matched against entity nodes in the graph. That is a cleaner match than embedding a full query and hoping it lands near the right knowledge units.
Knowledge Anchoring still helps, but it is noisier because the query and knowledge units can sit at different semantic granularities. A question may express a task, while a knowledge unit expresses a fact. They can be related without being embedding-neighbours in a neat way.
Query Updating is the most interesting because it is useful but not uniformly so. The paper reports that it improves MuSiQue and HotpotQA but slightly degrades on 2Wiki. The proposed explanation is that 2Wiki often contains semantically similar entities, including family relations and homonyms such as Elizabeth I and Elizabeth II, making disambiguation harder. This is a good limitation hidden inside an ablation: mechanisms that encourage broader evidence seeking can struggle when the corpus contains many similar-looking entity trails.
For operators, the ablation says: if you copy only one idea from Q-Iter, copy entity anchoring first. If you copy two, add semantic knowledge-unit anchoring. If you copy query updating, test it against your corpus, especially if your domain has many similarly named products, people, subsidiaries, regulations, or projects. Which is to say: most enterprises, naturally.
The sensitivity tests are about retrieval discipline, not parameter worship
The parameter sensitivity section tests top-$K$ retrieved results, beam size, search depth, and the token constraint coefficient. Its purpose is robustness and tuning guidance, not a new claim about the nature of intelligence, despite what conference hallway conversations may try to make of it.
The pattern is unsurprising but useful.
Increasing top-$K$ does not consistently improve generation quality. More retrieved candidates can add noise. A top-$K$ of 3 is sufficient in the default setting.
Increasing beam size helps until it plateaus. The paper uses a default beam size of 5, arguing that larger beams add diminishing returns and can introduce noise.
Search depth helps up to a point. Since many benchmark questions require around two hops and fewer require three or four, deeper traversal improves performance until over-retrieval starts to hurt. When depth reaches 4, quality slightly deteriorates in the reported MuSiQue analysis.
The token constraint coefficient correlates positively with generation quality: more LLM-processed chunks tend to produce better knowledge units, which improves retrieval. That is expected. The more useful observation is that the gain curve does not eliminate the cost-performance appeal of hybrid extraction.
This is the operating lesson: retrieval parameters are not knobs for “more.” They are knobs for “enough.” Enough candidates, enough beam width, enough traversal depth, enough LLM extraction. Beyond that, the system begins retrieving plausible distractions with excellent confidence and terrible manners.
What Cognaptus infers for enterprise RAG
The paper directly shows that Clue-RAG improves benchmark multi-hop QA performance and token efficiency across the tested datasets, baselines, and two LLMs. It directly shows that hybrid extraction can preserve most of the full-token performance with half the LLM indexing budget. It directly shows that Q-Iter’s components contribute measurable gains, with entity-based spreading activation strongest in the ablation.
The business inference is broader but should stay disciplined.
Clue-RAG suggests that enterprise RAG systems should be designed around semantic granularity. A single vector index over chunks is often too coarse. A pure entity graph is often too thin. A proposition-like or knowledge-unit layer may be the missing operational middle, especially where answers depend on conditions, exceptions, responsibilities, temporal details, and cross-document references.
It also suggests that indexing budgets should be allocated selectively. Not every document deserves expensive LLM decomposition. Chunks likely to cause ambiguity deserve more processing. Routine chunks may be handled with cheaper NLP tools. In a large corpus, that distinction can matter more than swapping one frontier model for another and calling it a strategy.
Most importantly, Clue-RAG reframes retrieval as an active process. The query is not merely used once at the beginning. It controls anchoring, traversal, re-ranking, and evidence expansion. This is closer to how a good analyst searches: identify known entities, find a relevant clue, use the clue to discover the next entity, discard tempting but irrelevant trails, and return to the source document before making the final claim.
That does not make Clue-RAG a production blueprint out of the box. But it gives system builders a better checklist.
| Design question | Clue-RAG-inspired answer | Enterprise implication |
|---|---|---|
| What should be indexed? | Chunks, atomic knowledge units, and entities | Preserve both context and granular facts |
| Where should LLM indexing be spent? | On chunks likely to suffer contextual ambiguity | Control indexing cost without abandoning quality |
| How should retrieval move? | Across entity and knowledge-unit layers, constrained by the query | Reduce graph drift in multi-hop retrieval |
| How should evidence reach the generator? | Map selected units back to original chunks | Keep generated answers grounded in source context |
| What should be tuned? | Candidate count, beam size, depth, and LLM extraction budget | Optimise for enough evidence, not maximum evidence |
Where this result should not be over-sold
The paper is strong, but its evidence lives in controlled benchmark QA. That boundary matters.
First, the datasets are multi-hop QA benchmarks with preprocessed passages. Enterprise corpora are uglier. They include PDFs, spreadsheets, scanned contracts, chat logs, permission boundaries, stale versions, duplicated policies, conflicting attachments, and that one SharePoint folder nobody admits owning.
Second, the evaluation metrics are accuracy and token-level F1 against gold answers. These are appropriate for the paper’s setting, but enterprise systems often care about citation faithfulness, answer abstention, auditability, latency, privacy controls, and downstream task completion. “Contains the gold answer” is not the same as “safe to send to a customer.”
Third, the system still uses LLMs in places beyond offline indexing, including query entity extraction and answer generation. The zero-token indexing variant is impressive, but it is not a zero-LLM RAG system.
Fourth, the method’s dependence on entity extraction can be a strength or weakness depending on domain. In domains with stable named entities, entity anchoring is powerful. In domains full of ambiguous internal labels, project codenames, similar product SKUs, abbreviations, and nested corporate entities, the anchoring layer will need serious governance. The paper’s 2Wiki query-updating behaviour already hints at this issue.
Finally, the paper’s future-work note mentions multimodal data. That matters because many enterprise retrieval failures occur in tables, diagrams, screenshots, forms, and spreadsheets, not only prose. Clue-RAG’s chunk-unit-entity design is conceptually extensible, but the paper does not prove multimodal performance.
The useful lesson is not “build a graph.” It is “choose the right retrieval unit.”
Clue-RAG is valuable because it refuses a lazy trade-off. It does not choose between raw chunks and structured graphs. It uses both, with knowledge units as the middle layer and Q-Iter as the query-controlled movement policy.
That is the practical takeaway for RAG builders. Better retrieval is not just better embedding search. It is not just a larger knowledge graph. It is not even simply “use an LLM to extract everything,” which remains the default enterprise instinct whenever a diagram has too much empty space.
The better question is: at each step, what is the smallest representation that preserves the fact the answer needs, and the largest representation that preserves enough context to trust it?
Clue-RAG’s answer is tidy: use entities to navigate, knowledge units to retrieve facts, chunks to ground generation, and the query to keep the whole process from wandering off into graph-shaped nonsense.
For once, the graph is not the main character. The retrieval unit is.
\ast\astCognaptus: Automate the Present, Incubate the Future.\ast\ast
-
Yaodong Su, Yixiang Fang, Yingli Zhou, Quanqing Xu, and Chuanhui Yang, “Clue-RAG: Towards Accurate and Cost-Efficient Graph-based RAG via Multi-Partite Graph and Query-Driven Iterative Retrieval,” arXiv:2507.08445, 2025. ↩︎