Memory With Intent: Why LLMs Need a Cognitive Workspace, Not Just a Bigger Window
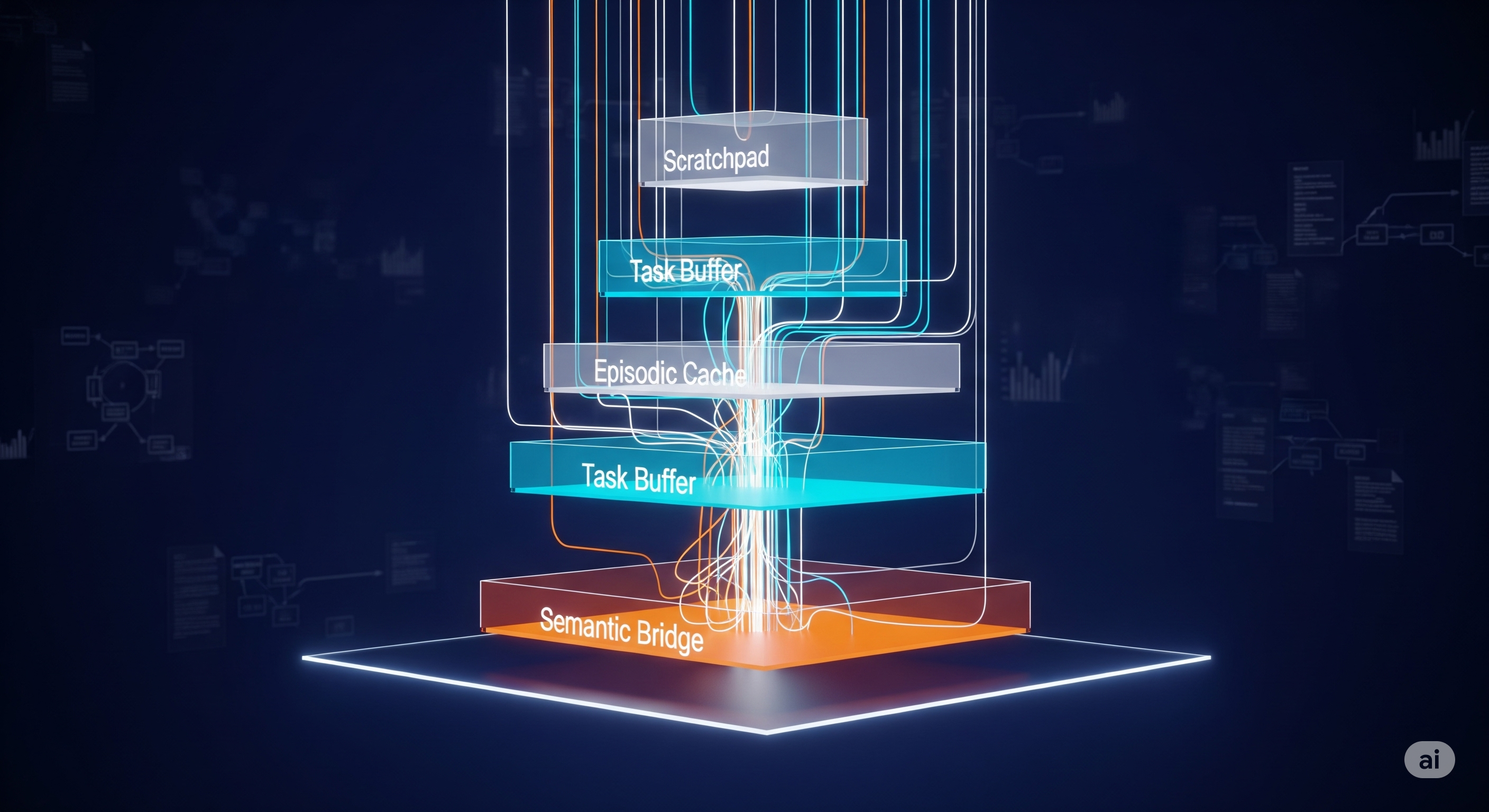
TL;DR for operators Most enterprise LLM failures do not come from the model “not knowing enough”. They come from the system forgetting what it was doing five minutes ago, rediscovering the same facts, and treating every user turn as a fresh episode in a soap opera nobody asked to watch. The paper behind this article proposes Cognitive Workspace: an active memory architecture for LLMs that deliberately curates, reuses, consolidates, and forgets information rather than merely retrieving chunks or stretching the context window.1 Its core claim is simple but consequential: useful long-context behaviour is not the same as having a long context window. It is the ability to maintain a working state across a task. ...