TL;DR for operators
Most enterprise LLM failures do not come from the model “not knowing enough”. They come from the system forgetting what it was doing five minutes ago, rediscovering the same facts, and treating every user turn as a fresh episode in a soap opera nobody asked to watch.
The paper behind this article proposes Cognitive Workspace: an active memory architecture for LLMs that deliberately curates, reuses, consolidates, and forgets information rather than merely retrieving chunks or stretching the context window.1 Its core claim is simple but consequential: useful long-context behaviour is not the same as having a long context window. It is the ability to maintain a working state across a task.
The reported empirical results are directionally interesting. In a small GPT-3.5-turbo setup using eight AI-domain documents, Cognitive Workspace reports roughly 54-60% memory reuse, compared with 0% reuse for the traditional RAG baseline, and about 17-18% net efficiency gain after accounting for around 3.3x more operations. That is not yet a production benchmark. It is evidence for a design hypothesis: active memory management can reduce repeated work in multi-turn tasks.
For operators, the lesson is not “replace RAG”. The lesson is sharper: classic RAG gives the model access to documents; a cognitive workspace gives the agent continuity. Those are different jobs. If your AI use case is a one-shot question, classic retrieval may be enough. If your AI use case is legal review, due diligence, customer support investigation, product research, sales intelligence, or multi-step analysis, then the expensive part is often not retrieval. It is reconstruction.
The business question is therefore not “how many tokens can we fit?” It is: how much previously earned understanding can the system reuse without becoming stale, leaky, or wrong?
The familiar failure mode: every turn starts from zero
A manager asks an AI analyst to compare three vendors. The model retrieves the right documents, summarises them, identifies gaps, and suggests follow-up questions. Good.
Then the manager asks: “Now adjust that for our APAC rollout and ignore the vendor with the weak compliance posture.”
A surprisingly large amount of enterprise AI still behaves as if this is a new task. It retrieves again. It re-summarises. It may or may not remember which vendor had the compliance problem. It may preserve the surface conversation while losing the actual work state: assumptions, rejected options, unresolved questions, partial conclusions, and why certain facts mattered.
That is the distinction the Cognitive Workspace paper is trying to make. A large context window can hold a lot of text. RAG can fetch relevant chunks. Neither necessarily maintains an evolving problem representation.
This matters because most valuable business work is not a single prompt. It is a chain of judgment: collect evidence, compare alternatives, resolve contradictions, update assumptions, revisit earlier decisions, and explain why the answer changed. A system that cannot preserve intermediate reasoning is forced to keep paying a tax on reorientation. The invoice arrives as latency, token cost, tool calls, analyst frustration, and occasionally a beautifully formatted wrong answer.
The paper’s argument is that LLM memory should look less like a filing cabinet and more like a workspace: part scratchpad, part project room, part archive, part executive assistant with a ruthless sense of what is still relevant.
Three options are being confused under “more context”
The current market bundles several different ideas into one phrase: “give the model more context.” That phrase is too blunt. It hides three distinct design strategies.
| Strategy | What it gives you | What it does not automatically give you | Operator reading |
|---|---|---|---|
| Larger context window | More tokens visible in one pass | Memory policy, task state, selective forgetting, reuse discipline | Useful for broad inspection, but expensive if every task becomes a token landfill |
| Classic RAG | External document access through retrieval | Persistent working memory across turns | Necessary for knowledge access, insufficient for long-running reasoning |
| Cognitive Workspace | Active curation, hierarchical buffers, reuse, consolidation, task-driven context allocation | Guaranteed correctness, governance, or production-scale efficiency | Promising architecture for agent continuity, but still early evidence |
The paper is strongest when read as a comparison between these options, not as a declaration that one has conquered the others. Long context is a capacity strategy. RAG is an access strategy. Cognitive Workspace is a control strategy.
That distinction is the business value of the paper. Enterprise AI does not merely need more input. It needs memory with intent.
A bigger window can still be passive. The model sees more, but it does not necessarily know what to preserve, what to compress, what to ignore, or what to bring forward. Classic RAG improves access, but it usually reacts to the query in front of it. Cognitive Workspace asks the system to manage memory as part of the task itself: predict information needs, check whether relevant state already exists, retrieve only when needed, update the working state, and consolidate useful knowledge.
The paper’s algorithmic loop is straightforward: initialise hierarchical buffers, decompose the task, predict information needs, check working memory for reusable state, retrieve if missing, update cognitive state, and consolidate memory. That sounds almost mundane. It is also exactly where many enterprise AI systems quietly fail.
What Cognitive Workspace changes: memory becomes a managed resource
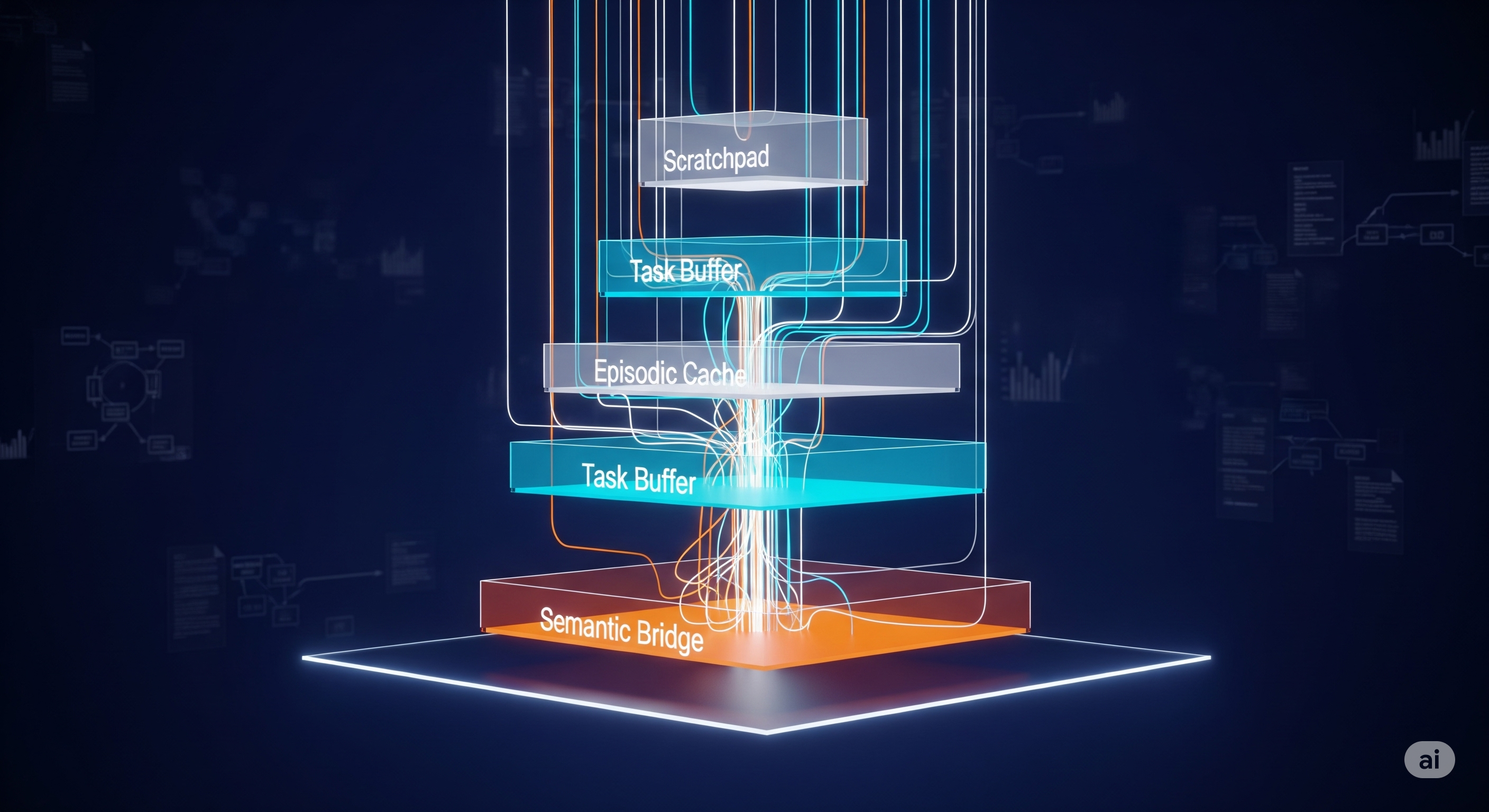
The proposed architecture has three main layers.
First, an active memory management system. This is the metacognitive layer: it evaluates relevance, anticipates future needs, prioritises information, applies forgetting policies, and consolidates frequently used patterns. In plain business language, it decides what deserves a place on the desk and what belongs in the archive.
Second, hierarchical cognitive buffers. The paper describes an immediate scratchpad for active reasoning, a task buffer for problem-specific state, an episodic cache for interaction history, and a semantic bridge to larger external knowledge. The exact capacities are less important than the design principle: different memories have different jobs. A contract clause being actively negotiated should not live in the same memory tier as background industry knowledge or a six-week-old exploratory note.
Third, task-driven context optimisation. The system shifts attention and compute depending on the stage of the task: focused reasoning, scanning, integration, or consolidation. The point is not to attend equally to everything. Equal attention is not intelligence. It is panic with a GPU budget.
This is where the cognitive-science framing becomes practically useful. Humans do not solve complex tasks by holding every fact in mind at once. They use notebooks, whiteboards, folders, diagrams, tabs, and memory cues. The external artifact is not just storage; it shapes the thinking process. The paper borrows that idea and applies it to LLM systems: memory should be part of the reasoning architecture, not a database bolted on after the demo.
For enterprise agents, this suggests a useful design principle:
Treat memory as an operational asset with lifecycle rules, not as an ever-growing transcript.
That means deciding what gets pinned, what gets summarised, what expires, what is versioned, what requires provenance, and what cannot cross user or client boundaries. The word “memory” sounds soft. In production, it is policy infrastructure wearing a cardigan.
The experiments test state persistence, not general intelligence
The paper’s empirical section is the main evidence, but it needs careful interpretation.
The setup is modest: Python 3.8, GPT-3.5-turbo for task decomposition and synthesis, eight AI-domain documents covering machine learning, deep learning, and NLP topics, and a traditional RAG baseline using fixed chunking and vector retrieval. The metrics include memory reuse rate, operation count, response time, and statistical significance.
The experiments are best understood as tests of whether active state management creates measurable reuse under controlled task conditions. They are not broad tests of enterprise reliability, factual accuracy across domains, or multi-month agent performance.
| Test | Likely purpose | What it supports | What it does not prove |
|---|---|---|---|
| 4-round multi-turn dialogue | Main evidence for short-horizon state persistence | Cognitive Workspace can reuse memory across nearby turns in the authors’ setup | That reuse translates into better answers in real enterprise conversations |
| 10-round extended dialogue | Main evidence for longer interaction continuity | Reuse remains around 57.1%, with reported 17.3% net efficiency gain | That the same pattern holds over hundreds of turns or weeks of work |
| Multi-hop reasoning | Main evidence for chained inference tasks | Maintaining reasoning state can reduce redundant computation in linked tasks | That the system solves hard reasoning problems better than strong modern baselines |
| Conflict resolution | Main evidence for synthesis under contradictory information | Reuse is highest here at 59.8%, suggesting value when viewpoints must be tracked | That the system handles messy legal, regulatory, or organisational conflicts safely |
| Figure 1 summary | Visual synthesis of the reported experiments | Shows reuse, operation growth, net efficiency, and statistical separation | Independent validation or a separate robustness test |
In the four-round dialogue experiment, Cognitive Workspace reports an average reuse rate of 54.52%, compared with 0% for the RAG baseline. Operation counts are higher: 99 operations for Cognitive Workspace versus 30 for RAG. The authors interpret this as a 3.3:1 operation ratio reflecting the cost of active management, while reuse produces a substantial efficiency benefit.
In the 10-round dialogue experiment, the average reuse rate rises to 57.1%, the operation ratio is 3.31, cumulative saved operations are reported as 17, and net efficiency gain is 17.3% after accounting for overhead. The statistical test reports t(18) = 69.60, p < 0.001, and Cohen’s d = 23.20.
The multi-hop reasoning and conflict-resolution tests report similar reuse and efficiency ranges: 58.8% reuse and 17.9% net efficiency gain for multi-hop reasoning; 59.8% reuse and 17.8% net efficiency gain for conflict resolution. The reported Cohen’s d values for these latter tasks are extremely large, above 180.
Those effect sizes should not be read like normal business evidence. They mostly tell us that, under the authors’ metric design, the active-memory system and the stateless RAG baseline separate dramatically. That is useful, but it is not the same as proving production ROI. A baseline with 0% reuse is easy to beat on reuse because it was not designed to persist state in the first place. The interesting question is not whether a memory system has more memory reuse than a non-memory system. Please alert the Nobel committee, but perhaps after lunch.
The interesting question is whether the reuse is valuable, safe, and cheaper than the overhead when documents are numerous, permissions are messy, facts change, and users disagree about what should be remembered.
The useful number is not 60%; it is the break-even logic
The headline reuse number is attractive: 54-60%. But operators should focus on the structure behind it.
Cognitive Workspace spends more operations up front because it is managing state. It decomposes tasks, predicts needs, checks memory, updates buffers, and consolidates information. That is overhead. The paper reports roughly 3.3x higher operation counts.
The payoff appears when repeated work is avoided. In the paper’s calculation, reuse divided by operation overhead yields the 17-18% net efficiency range. In the conflict-resolution experiment, the paper identifies a break-even point at round 6. Before that, active memory management may be more expensive. After that, reuse begins to matter.
This is the most business-relevant idea in the paper.
A cognitive workspace is unlikely to pay off for every use case. It is overbuilt for one-shot FAQ, simple document lookup, or transactional summarisation. For those, classic RAG plus good evaluation may be sufficient. The architecture becomes interesting when tasks have repeated substructure:
- the same facts recur across multiple turns;
- intermediate conclusions need to be preserved;
- the user changes constraints without restarting the task;
- contradictions must be tracked rather than flattened;
- the cost of re-analysis is higher than the cost of maintaining memory.
That describes a large share of valuable enterprise AI work: deal screening, vendor diligence, policy analysis, claims investigation, portfolio monitoring, legal drafting, grant review, compliance Q&A, customer escalation handling, and internal research.
The operator’s question should therefore be: at what interaction depth does memory begin to pay for itself?
For some workflows, the answer may be round 3. For others, never. A serious pilot should measure the break-even curve rather than admiring the architecture diagram.
RAG is not dead; stateless RAG is just not enough
One easy but wrong reading is that Cognitive Workspace “beats RAG”. That is not the useful lesson.
RAG remains essential because enterprises need controlled access to external knowledge. Documents, databases, tickets, contracts, policies, code repositories, and CRM records do not magically fit into a model’s weights. Retrieval is not going away. Nor should it.
The real contrast is between retrieval as isolated lookup and retrieval as part of a managed cognitive process.
Classic RAG asks: “What chunks match this query?”
Cognitive Workspace asks a richer set of questions:
- What are we trying to accomplish?
- What do we already know from this task?
- Which prior conclusions are still valid?
- What uncertainty remains unresolved?
- What information is likely to be needed next?
- Which memory should be compressed, preserved, expired, or escalated?
- When should retrieval happen, and when would it merely duplicate work?
That is a very different control loop. It turns retrieval from a reflex into a planning act.
For business systems, this difference is visible in the user experience. A stateless RAG assistant can answer questions. A workspace-based agent can continue work. It can say: “We rejected Vendor B earlier because its compliance documentation did not cover APAC data residency; the new constraint strengthens that rejection, but Vendor C now needs a pricing check.” That is not just retrieval. That is continuity.
Continuity is where many AI products currently pretend to be more mature than they are. They preserve chat history and call it memory. Chat history is not memory. It is a transcript. A transcript still needs interpretation, prioritisation, and state management. Otherwise the system is just rummaging through its own diary.
Where this becomes practical inside an enterprise stack
The paper sketches integration with current systems through API compatibility, tool integration, multi-agent coordination, and gradual migration. That direction is sensible, but production design needs a harder operational frame.
A useful enterprise cognitive workspace would need at least five layers.
| Layer | Practical role | Failure if ignored |
|---|---|---|
| Working state | Keeps task assumptions, current goals, open questions, and intermediate conclusions | The agent keeps restarting the analysis |
| Evidence memory | Stores source-backed facts with provenance and versioning | The agent remembers conclusions without knowing why |
| Policy memory | Applies retention, access control, expiry, and confidentiality rules | The agent leaks or misuses remembered information |
| Evaluation memory | Tracks reuse quality, false reuse, and redundant retrieval avoided | The system optimises for remembering, not being right |
| User control | Allows pinning, correction, forgetting, and audit | Users distrust the system or cannot correct stale state |
This is where the business pathway becomes clear. Cognitive Workspace is valuable if it reduces repeated reasoning without creating new governance debt.
A sales-intelligence agent should remember which account hypotheses were rejected and why. A legal-review agent should remember clause-level concerns while preserving citation lineage. A support agent should track investigation state across escalation levels. A due-diligence agent should preserve open risks, not merely summarise uploaded PDFs again every morning like an intern trapped in a calendar invite.
The ROI is not “fewer tokens” in the abstract. It is fewer duplicate retrievals, fewer repeated tool calls, fewer analyst restarts, faster handoffs, and better continuity across long-running work.
That is Cognaptus’ inference from the paper, not something the paper proves at enterprise scale. The paper provides an early experimental argument for memory reuse. The business case still needs deployment evidence.
How to pilot Cognitive Workspace without cosplaying research theatre
A practical pilot should start narrow. The wrong pilot is: “Let’s add memory to everything.” That is how organisations create haunted filing cabinets.
Choose a workflow where repeated context is genuinely expensive. Good candidates include policy Q&A over evolving documents, support escalations, contract review across multiple drafts, research brief production, or account planning. Bad candidates include one-shot document summarisation, generic chatbot FAQs, and simple search interfaces.
Then measure the right things.
| Metric | Why it matters |
|---|---|
| Memory reuse rate | Shows whether stored state is actually being used |
| Useful reuse rate | Separates helpful reuse from stale or irrelevant reuse |
| Duplicate retrievals avoided | Converts memory into retrieval savings |
| Duplicate tool calls avoided | Converts memory into operational savings |
| Time to resume task | Measures continuity after interruption |
| False-memory incidents | Captures stale, wrong, or unauthorised reuse |
| Break-even turn depth | Identifies when active memory starts paying off |
| Human correction rate | Shows whether memory is aligned with user intent |
The pilot should compare at least three systems: strong RAG, RAG with lightweight session memory, and a more active workspace design. Otherwise the experiment risks proving only that memory beats no memory. Again, useful, but hardly a revelation.
The workspace should also expose memory actions. Users should be able to see, at least at a policy level, what the system is preserving: assumptions, decisions, unresolved questions, source-backed facts, preferences, and exclusions. “Trust me, I remembered correctly” is not an enterprise control.
The most important pilot output is not a demo. It is a memory ledger: what was stored, why it was stored, when it was reused, what it saved, and whether it remained valid.
The boundaries: promising architecture, early evidence
The paper is ambitious, but its current evidence has clear boundaries.
First, the empirical validation is small. It uses eight documents and interactions up to 10 rounds. That is useful for a controlled demonstration, not enough for enterprise generalisation. Thousands of documents, conflicting data sources, changing permissions, and multi-month projects create different failure modes.
Second, the baseline matters. Traditional RAG is stateless in the comparison, so it naturally scores 0% on memory reuse. A stronger comparison would include modern RAG systems with caching, session memory, agent scratchpads, graph memory, or production-grade retrieval orchestration. The paper positions Cognitive Workspace against a broad state-of-the-art landscape, but the direct empirical comparison is narrower.
Third, the overhead is real. A 3.3x operation count may be acceptable for slow, high-value analytical tasks. It may be unacceptable for low-latency support, high-volume workflows, or cost-sensitive consumer products. Active memory management is not free; it is a bet that reuse will amortise the cost.
Fourth, memory consistency becomes harder as systems become more useful. A single-agent workspace is one thing. A multi-agent, multi-user workspace with shared state, partial permissions, contradictory updates, and audit requirements is quite another. The paper identifies memory consistency as an open challenge, and that challenge should be read as central, not decorative.
Fifth, evaluation needs to evolve. Passive retrieval benchmarks do not capture whether an agent preserved the right intermediate conclusion, forgot the right stale fact, or reused the right prior assumption. A cognitive workspace needs evaluation for memory quality, not just answer accuracy.
These limitations do not undermine the paper’s main design insight. They simply place it where it belongs: as an early architectural and empirical argument, not a finished enterprise recipe.
The better mental model: not a longer window, a managed workbench
The phrase “functional infinite context” is useful if read carefully. It should not mean infinite memory. It should mean the system can operate over an unbounded task horizon by managing limited attention intelligently.
A craftsperson does not put every tool on the bench. A lawyer does not keep every precedent in working memory. A CFO does not recalculate the entire model from first principles every time someone changes an assumption. Skilled work depends on structured external memory: what is active, what is archived, what is trusted, what is provisional, and what has been superseded.
That is the practical intuition behind Cognitive Workspace. The workspace is not valuable because it stores more. It is valuable because it helps the system decide what should remain operationally alive.
For AI agents, that may become one of the dividing lines between toy autonomy and useful autonomy. Tool use lets an agent act. Planning lets it sequence actions. Memory lets it become accountable to its own prior work.
Without that, the agent is not a colleague. It is a bright contractor with permanent amnesia and excellent formatting.
Conclusion: the next context race is about control
The industry has spent years stretching context windows and improving retrieval. Both matter. Neither solves the full continuity problem.
The Cognitive Workspace paper makes a timely argument: LLM systems need active memory management, hierarchical working state, and task-driven context optimisation if they are to support long-running reasoning. Its experiments are small but coherent. They show that, in controlled multi-turn tasks, active memory can generate substantial reuse and modest net efficiency gains after overhead.
The operator takeaway is disciplined optimism. Do not rip out RAG. Do not declare infinite context solved. Do not let a memory layer quietly become an ungoverned swamp.
Instead, treat memory as a first-class system component. Give it policies. Give it metrics. Give users control. Measure when it pays back. Test whether reuse improves outcomes, not merely whether reuse exists.
Bigger windows help the model see more. Cognitive workspaces may help it carry work forward. For enterprise AI, that difference is not cosmetic. It is the gap between answering a question and staying on the job.
Cognaptus: Automate the Present, Incubate the Future.
-
Tao An, “Cognitive Workspace: Active Memory Management for LLMs — An Empirical Study of Functional Infinite Context,” arXiv:2508.13171, 2025, https://arxiv.org/abs/2508.13171. ↩︎