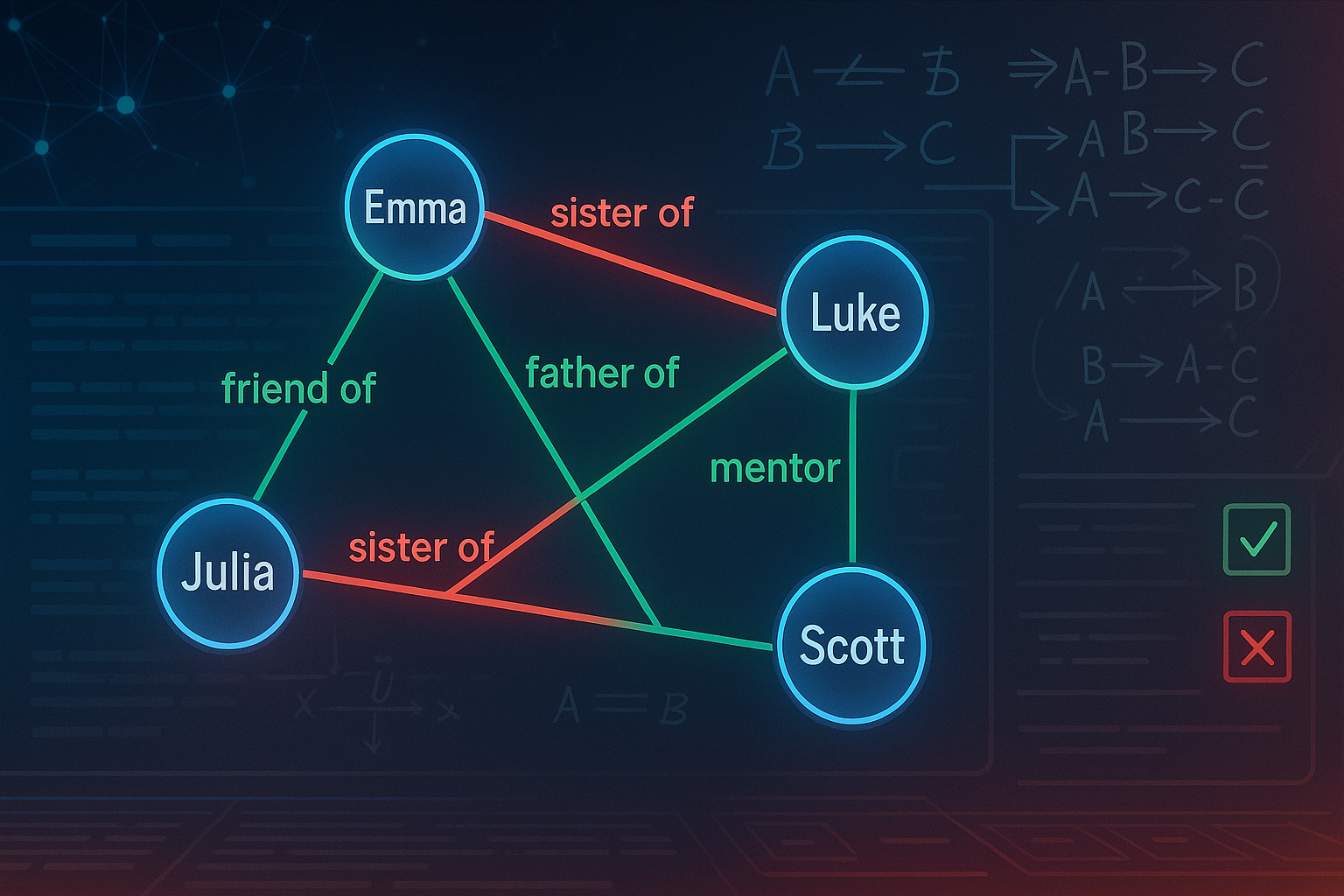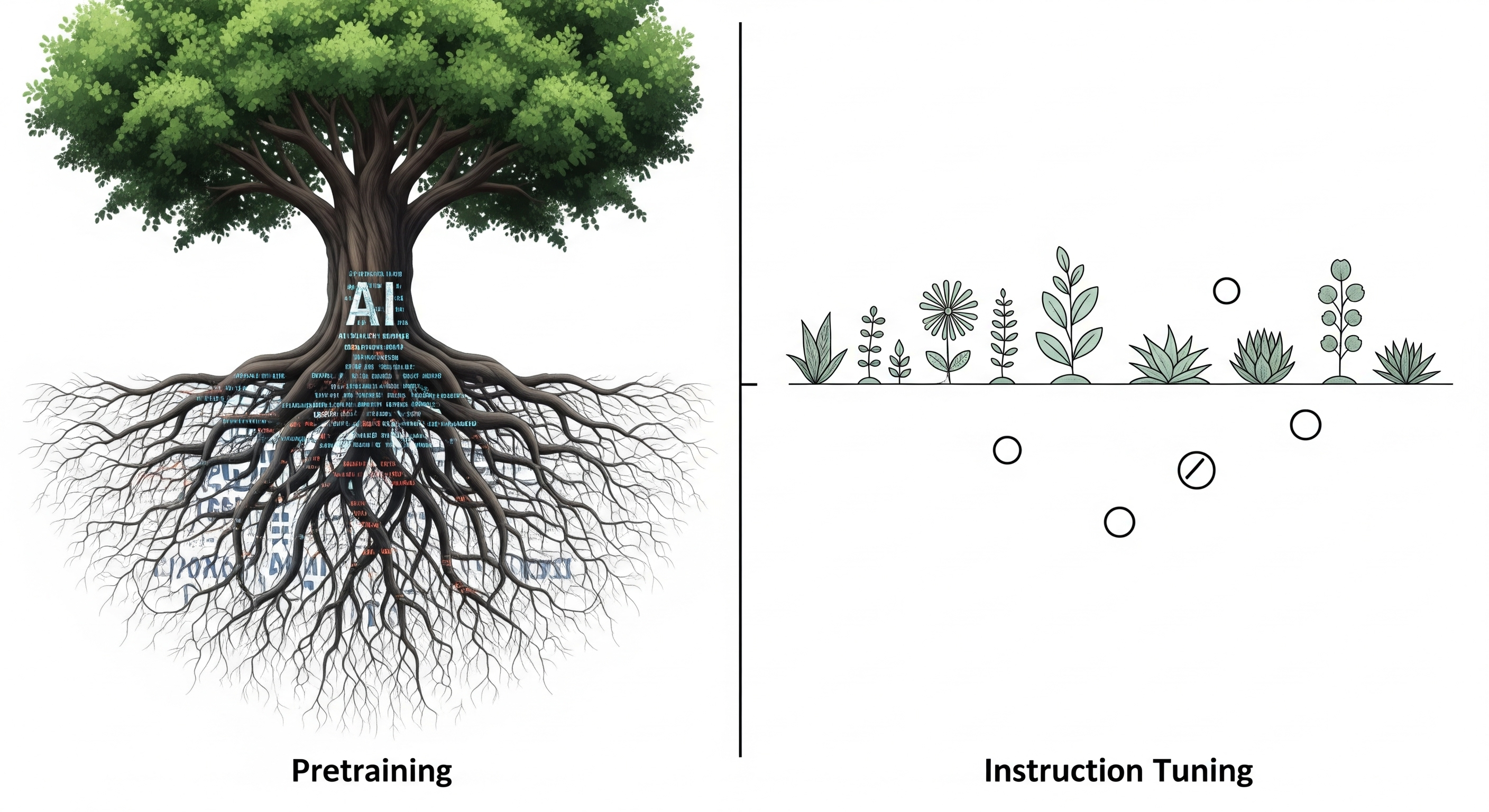
Bias, Baked In: Why Pretraining, Not Fine-Tuning, Shapes LLM Behavior
TL;DR for operators Fine-tuning is not a washing machine. It may polish, redirect, or occasionally muffle a model’s behavioural tendencies, but this paper suggests that many cognitive-bias patterns are already substantially shaped before instruction tuning begins. The study separates three possible sources of observed bias in large language models: the pretrained backbone, the instruction dataset, and random variation during fine-tuning. Its main finding is that models’ bias profiles cluster more strongly by pretrained model identity than by the instruction data used later. In plainer operational language: the base model carries a behavioural signature that survives downstream training. ...