TL;DR for operators
SymbolicThought1 is a useful reminder that relationship extraction is not a vibes problem. It is a graph problem wearing a language-model costume.
The paper proposes a human-in-the-loop system for extracting character relationships from narrative text. The pipeline lets an LLM propose characters and relations, then applies symbolic rules to infer missing edges, detect contradictions, retrieve supporting evidence, and ask humans to confirm or correct what matters. That is the important mechanism: the LLM is not trusted as a final judge. It is treated as a noisy extractor inside a controlled annotation workflow.
The empirical results are directionally strong but not magical. SymbolicThought improves relation extraction F1 over prompting, self-consistency, and self-reflection across GPT-4.1, GPT-4o-mini, and Qwen2.5-32B-Instruct. For GPT-4.1, F1 rises from 33.4 under direct prompting to 37.9. For GPT-4o-mini, it rises from 9.9 to 18.8. For Qwen2.5-32B-Instruct, it rises from 14.8 to 22.5. These are meaningful gains, but the absolute scores also say the quiet part aloud: relationship extraction from long, messy narratives remains hard.
For operators, the business lesson is straightforward. If you are building systems for legal document review, investigative journalism, intelligence analysis, HR case review, CRM relationship mapping, or enterprise knowledge graphs, do not ask a model to “extract all relationships” and call it a product. Build a graph workflow. Let the model propose. Let deterministic rules check. Let retrieval ground disputed claims. Let humans adjudicate the cases where the system’s confidence should not be allowed near production.
The paper’s limitation is equally practical. It evaluates a small narrative corpus: 19 texts, 1,398 extracted relation triplets, and a relationship-logic dataset built from 160 interpersonal relationship categories. That is enough to demonstrate the mechanism. It is not enough to declare the problem solved. Which, in AI, already makes it unusually honest.
The problem is not extraction; it is coherence
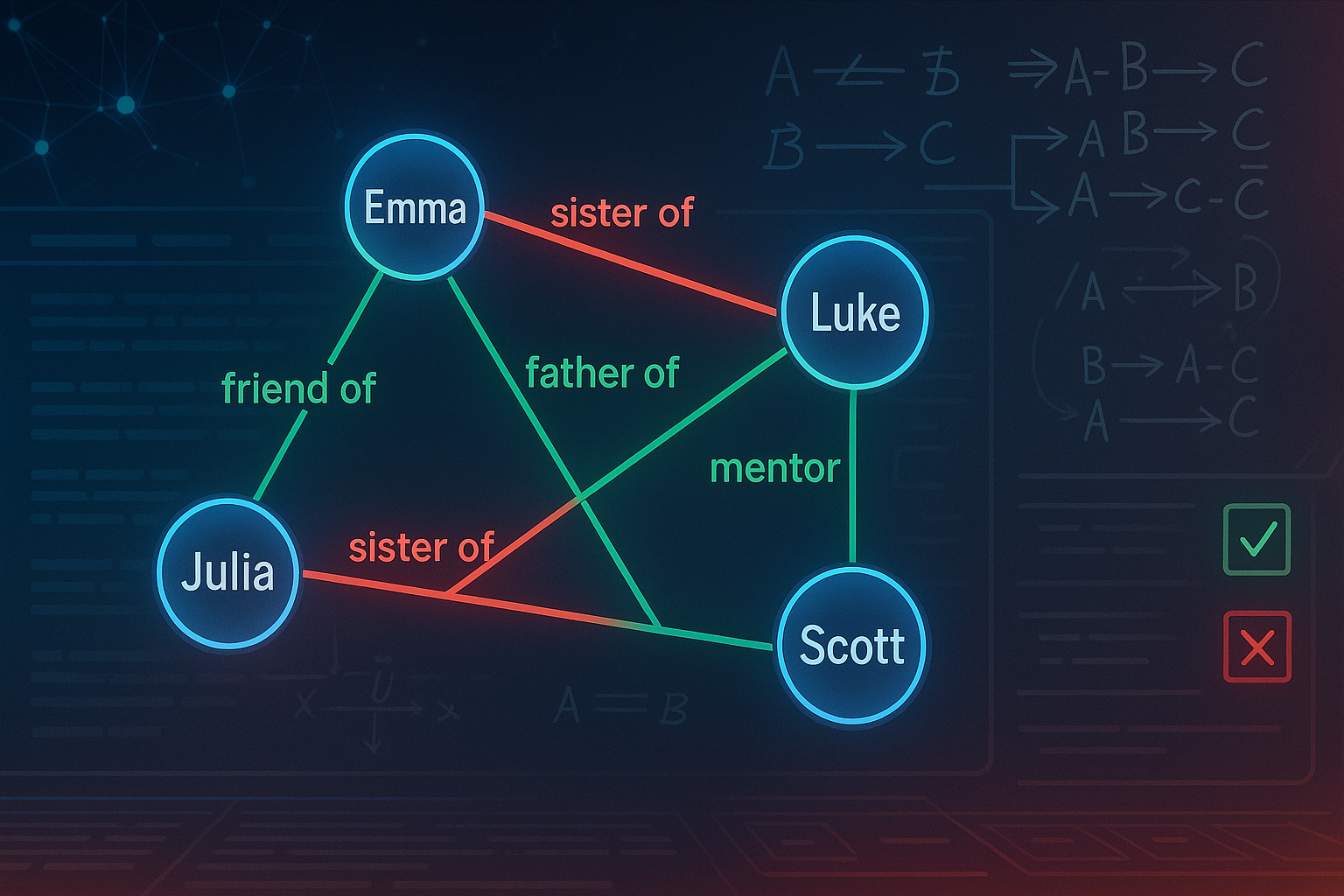
A relationship graph looks simple once it exists. Andrew is Scott’s father. Emma is Andrew’s wife. Scott is Emma’s son. A compliance analyst, journalist, or lawyer might look at that and think the task is merely to find the relevant sentences.
That is the easy version.
The hard version appears when the text is long, indirect, multi-perspective, and socially dense. A person may be described by several aliases. A relationship may be implied rather than stated. One sentence may say “his wife”; another may name the wife; a third may imply a child; a fourth may contradict the first three because the model confused directionality. Now the system is no longer extracting facts. It is maintaining a social ledger.
LLMs are awkward in precisely this setting. They are strong at proposing plausible relationships from text. They are weak at guaranteeing that the resulting graph is complete, consistent, and directionally correct. A model may know that “husband of” and “wife of” are inverses in one place, then fail to apply the same logic two paragraphs later. It may identify “A is B’s child” but forget the reverse relation. It may infer a superficial relationship because it is linguistically obvious while missing the deeper social relation that human annotators actually want.
SymbolicThought’s core move is to stop treating this as a pure natural-language understanding task. It reframes narrative relationship extraction as a constrained graph-construction workflow.
That sounds less glamorous than “the model understands the story”. Good. It is also much closer to how reliable systems are built.
SymbolicThought works because each layer has a different job
The framework has two main stages: character extraction and relationship extraction. Both start with LLM proposals, but neither ends there.
In character extraction, the model proposes candidate entities from the document. The system uses repeated extraction with temperature sampling and frequency filtering to improve coverage while suppressing obvious noise. Human annotators then verify the character list, merge aliases, split ambiguous names, and correct missing or spurious entities. This matters because relation extraction built on a bad entity inventory is doomed before the graph even begins. A model that confuses “Queen Elizabeth”, “Her Majesty”, and “Elizabeth” is not doing subtle social reasoning. It is misfiling the paperwork.
In relationship extraction, the model proposes pairwise relation triples of the form $(x, r, y)$: character $x$ has relationship $r$ to character $y$. Again, multiple model runs are filtered to produce a candidate edge set. Then the symbolic module starts doing the work that prompts alone usually pretend to do.
The paper defines inferable relationship patterns such as:
| Pattern | What it means | Example of operational value |
|---|---|---|
| Symmetry | If $r(x, y)$ holds, then $r(y, x)$ also holds | “Friend of” should usually work both ways |
| Inversion | If $r_1(x, y)$ holds, then $r_2(y, x)$ follows | “Husband of” implies “wife of” in the reverse direction, depending on schema |
| Composition | If $r_1(x, y)$ and $r_2(y, z)$ hold, infer $r_3(x, z)$ | Family or organisational chains can imply additional edges |
| Hierarchy | A specific relation implies a broader relation | “Mother of” is also a parental relation |
| Incompatibility | Two relations cannot both hold between the same pair | “Child of” and “father of” in the wrong direction cannot both be right |
| Asymmetry | A relation cannot hold in reverse | “Parent of” does not imply “child of” in the same direction |
| Exclusivity | A relation excludes equivalent alternatives | A spouse relation may conflict with another spouse relation under a given ontology |
This is the mechanism-first lesson. LLMs generate candidate structure. Symbolic rules test whether the structure behaves like a structure. RAG is used not as a decorative appendix, but as a conflict-resolution tool: when rules detect incompatible claims, the system retrieves relevant source context and asks the LLM to choose among structured alternatives. Humans remain in the loop through an interface that highlights suggested relations, inferred relations, conflicts, and supporting evidence.
The design is not “AI replaces annotation”. It is “AI stops wasting human annotation time on search, formatting, and obvious graph closure”. That is a much less cinematic product claim, and therefore a more useful one.
The dataset is small, but it is aimed at the right weakness
The paper introduces two evaluation assets. The first is a relationship-logic dataset covering 160 interpersonal relationship categories. Two trained experts annotated conflicts and antisymmetric interactions, producing about 51,000 derived logical relations. The reported Cohen’s Kappa is 0.832, which suggests substantial agreement after a task that is not exactly “click the cat pictures”. The second is a corpus of 19 narrative texts across historical accounts, news reports, biographical narratives, and fictional stories, from which the authors extracted 1,398 relation triplets.
Those numbers are not massive. They are not supposed to be. The point is not to build a universal social universe. The point is to test a specific failure mode: whether LLMs can handle relation logic, graph consistency, and narrative evidence well enough to support reliable annotation.
The answer is: not by themselves.
On the logical relationship tasks, GPT-4.1 performs best among the tested models, but still leaves plenty of room for system design. For the “Add” task, where the model must infer new relationships from existing ones, GPT-4.1 reaches 62.3 F1. GPT-4o-mini reaches 55.3, and Qwen2.5-32B-Instruct reaches 52.2. On the “Remove” task, where the model must judge conflicting relationships, performance is weaker: GPT-4.1 reaches 57.3 accuracy and 42.8 F1, while the smaller models are lower.
This result is useful because it diagnoses the disease before prescribing the medicine. If a model cannot reliably infer that one relation implies another, or that two relations cannot coexist, then “just prompt harder” is not an architecture. It is a coping mechanism.
The main evidence is improvement, not perfection
The paper compares SymbolicThought with direct prompting, self-consistency, and self-reflection across three models: GPT-4.1, GPT-4o-mini, and Qwen2.5-32B-Instruct.
Character extraction is the cleaner task. Self-consistency improves F1 slightly across all three models:
| Model | Direct prompting F1 | Self-consistency F1 | Interpretation |
|---|---|---|---|
| GPT-4.1 | 79.8 | 81.6 | Small gain from repeated sampling |
| GPT-4o-mini | 78.8 | 80.2 | Small gain, mostly stabilisation |
| Qwen2.5-32B-Instruct | 80.0 | 81.4 | Similar pattern |
This is component evidence. It tells us the first stage of the pipeline can produce a usable character inventory, especially with human verification and alias management. It does not prove the full system works.
The harder test is relation extraction. There, SymbolicThought consistently outperforms the baselines:
| Model | Best baseline F1 | SymbolicThought F1 | What this supports |
|---|---|---|---|
| GPT-4.1 | 33.4 | 37.9 | Symbolic refinement improves the strongest tested model |
| GPT-4o-mini | 12.5 | 18.8 | Structured rules help more when the base model is weaker |
| Qwen2.5-32B-Instruct | 16.9 | 22.5 | Gains transfer across model families |
The important word is “consistently”. SymbolicThought does not turn relation extraction into a solved task. GPT-4.1’s F1 of 37.9 is still low in absolute terms. But in this domain, low absolute performance is itself part of the evidence. It shows why a workflow with verification, evidence, and logic is necessary.
A weaker article would say: “SymbolicThought improves F1, therefore it is better.” The more interesting reading is: “Even after symbolic refinement, F1 remains modest, therefore the architecture should be viewed as annotation support rather than autonomous social understanding.”
That is not a criticism of the paper. It is the paper’s practical value.
Human time falls because the interface changes the task
The comparison with manual annotation is where the paper becomes more operationally relevant. Across history, biography, and narrative categories, SymbolicThought improves recall and reduces average annotation time.
| Category | Human recall | SymbolicThought recall | Human time | SymbolicThought time |
|---|---|---|---|---|
| History | 57.3% | 85.6% | 163.4 min | 118.3 min |
| Biography | 67.3% | 91.4% | 87.2 min | 45.5 min |
| Narrative | 63.4% | 89.1% | 102.5 min | 74.7 min |
This is not just “the AI is faster”. The mechanism is more specific. Humans are not being asked to discover every relation from scratch. They are reviewing a graph that already contains model proposals, inferred links, highlighted evidence, and conflict warnings. Their work shifts from exhaustive search to targeted judgement.
That distinction matters for business adoption. Many AI pilots fail because they treat human review as a thin layer slapped onto model output. The reviewer is handed a wall of generated text and asked to be legally responsible for it. Delightful. Very modern. SymbolicThought points to a better division of labour: make the system surface exactly where the graph is incomplete, inconsistent, or uncertain.
The usability study supports this interpretation, though it should be treated as exploratory. Ten non-expert annotators used the system and completed a questionnaire. Nine out of ten said they would use the tool in future annotation tasks. Users rated highlighting, suggested relations, and conflict detection as helpful, while expressing lower confidence in relation extraction accuracy than in character extraction. That is exactly the pattern one would hope to see: users like the scaffolding, but do not mistake it for infallibility.
A rare moment of user-interface sanity in AI research. Savour it.
The appendix is not a second thesis; it explains why the mechanism behaves as advertised
The paper’s appendix does useful supporting work, but it should not be overread.
The completeness proof argues that, given a finite entity set and defined relation operations, a finite sequence of symbolic operations can transform an initial graph into a target ground-truth graph. This is a theoretical property of the operation set. It does not mean the system automatically knows the ground truth. It means the rule vocabulary is expressive enough, under the paper’s assumptions, to complete or correct graphs through finite edits.
That is closer to a product-design guarantee than a model-intelligence guarantee. The framework gives users a finite set of meaningful operations for moving from rough extraction to coherent graph. It does not eliminate ambiguity, ontology disputes, or bad evidence retrieval.
The case studies are also best read as mechanism demonstrations. The paper shows examples where an LLM produces conflicting relationship edges, such as directionally inconsistent parent-child relations or mutually exclusive spouse candidates. Symbolic rules flag the conflict. RAG retrieves the relevant narrative evidence. A structured multiple-choice prompt forces the model to choose among alternatives rather than rambling its way into a plausible fog.
The error analysis is especially relevant. The authors note that LLMs often miss implied kinship relations, such as in-law relationships, because those require multi-hop inference. They also report that models sometimes choose superficial relations where humans prefer deeper social interpretations. In one example, a model treats a priest as an information receiver because someone confided in him, while humans view him as a helper or saviour. That is a subtle but important failure: the model extracts the nearest textual function, not necessarily the socially meaningful role.
This is the sort of error businesses should care about. A CRM system that labels someone as an “email recipient” when they are actually the executive sponsor is technically not hallucinating. It is merely useless in a highly structured way.
Small-world structure may predict annotation pain
One exploratory analysis connects annotation difficulty to the Small-World Index, a graph measure capturing dense local clustering and short global paths. The paper reports that documents with richer small-world structure tend to produce higher F1 scores and may require less human effort. Biographies cluster toward higher F1 and higher small-world structure; history texts appear sparser and harder.
This is not the main result. It is a useful operational hypothesis.
If future work validates this pattern, graph structure could become a workload estimator. A system could run an early pass over a document, estimate relational density and connectivity, and predict whether the case needs light review or expert-heavy annotation. For enterprise workflows, that matters because review cost is rarely uniform. Some documents are simple because relationships are repeated, explicit, and socially cohesive. Others are expensive because the important links are sparse, indirect, and scattered.
In other words, not every document deserves the same human budget. It would be nice if procurement departments eventually discovered this, preferably before buying another dashboard.
What Cognaptus infers for business use
The paper directly shows that symbolic refinement can improve narrative relationship extraction and reduce annotation time in a small, controlled evaluation. Cognaptus infers a broader design principle: relationship intelligence should be implemented as governed graph construction, not free-form extraction.
That has several practical consequences.
| Design choice | What the paper directly supports | Business interpretation | Boundary |
|---|---|---|---|
| LLM-generated candidate graphs | Models can propose entities and relations at scale | Use LLMs for first-pass coverage, not final authority | Candidate quality varies sharply by domain |
| Symbolic rule layer | Rules infer missing links and flag contradictions | Encode business logic explicitly rather than hoping prompts remember it | Rule maintenance becomes an operational responsibility |
| RAG for conflict resolution | Retrieved evidence helps resolve disputed relations | Use retrieval when claims conflict, not as generic decoration | Retrieval quality determines downstream judgement quality |
| Human verification interface | Annotators can confirm, edit, and inspect evidence | Human review should be targeted at ambiguity and conflict | Human decisions still require training and accountability |
| Graph complexity analysis | SWI correlates with annotation performance in the paper’s corpus | Early graph metrics may help forecast review effort | Exploratory result; not yet a general planning tool |
For legal review, the lesson is obvious: parties, obligations, authorisations, family ties, ownership chains, and communication roles should be represented as constrained graphs, not summarised into prose and thrown at a partner for “quick review”.
For journalism and intelligence analysis, the same applies to source networks, influence links, and event participants. A model-generated narrative summary can be fluent while still getting the direction of influence wrong. A graph makes the error inspectable.
For CRM and account intelligence, the implication is more commercial. Enterprise sales teams often care less about what a person said and more about their role in a decision network: sponsor, blocker, evaluator, budget owner, informal influencer. Many of those roles are inferred from scattered interactions. Symbolic rules will not solve that alone, but they provide a way to make the inference process auditable.
For HR investigations and compliance, the value is restraint. The system should not confidently label sensitive relationships without evidence and review. SymbolicThought’s architecture is attractive precisely because it exposes conflicts and evidence rather than burying them in fluent paragraphs. The future of responsible AI may be less “assistant with personality” and more “spreadsheet with a conscience”. Tragic for demos, excellent for liability.
Where the result should not be stretched
There are four boundaries worth keeping clean.
First, the evaluation domain is narrative text. Fictional stories, biographies, historical accounts, and news reports resemble many business documents, but they are not the same as contracts, email archives, call transcripts, medical records, or compliance cases. Each enterprise domain would need its own relation schema and conflict rules.
Second, the absolute relation-extraction scores remain modest. SymbolicThought improves F1, but the strongest reported relation F1 is 37.9 with GPT-4.1. That does not support autonomous deployment where missed or mislabelled relations carry high cost. It supports assisted annotation.
Third, the ground truth construction deserves care. The paper merges system-generated and human annotations to form the final ground truth for evaluation. That may be practical for annotation studies, but business users should not treat it as a universal benchmark methodology. In regulated contexts, ground truth needs independent validation and auditability.
Fourth, the symbolic layer is only as good as the ontology. A rule like “husband of” implies a reverse spouse relation only under a schema that defines those categories cleanly. Real enterprise relationships are messier: informal authority, temporary delegation, hidden influence, contested ownership, and jurisdiction-specific legal meanings. The rules will not maintain themselves. Sadly, neither will the people who promised they would.
The real contribution is supervised plumbing
SymbolicThought is easy to misread as a paper about making LLMs better at character relationships. That is part of it, but not the interesting part.
The interesting part is architectural humility. The system assumes LLMs are useful but unreliable. It assumes humans are accurate but expensive. It assumes symbolic rules are brittle but inspectable. It assumes retrieval is powerful but should be aimed at concrete disputes. Then it puts those weaknesses together in a way that produces a stronger workflow than any component would produce alone.
That is the pattern many enterprise AI systems need. Not a larger model pretending to understand everything. Not a human team manually reconstructing every relationship from scratch. Not a brittle rules engine pretending language is neat. A graph workflow where each layer is allowed to do the thing it is least bad at.
For AI operators, that is the quiet lesson: reliability is not a personality trait of the model. It is an architecture.
Cognaptus: Automate the Present, Incubate the Future.
-
Runcong Zhao, Qinglin Zhu, Hainiu Xu, Bin Liang, Lin Gui, and Yulan He, “SymbolicThought: Integrating Language Models and Symbolic Reasoning for Consistent and Interpretable Human Relationship Understanding,” arXiv:2507.04189, 2025. ↩︎