TL;DR for operators
RALLY is not a chatbot with propellers. It is a hybrid control framework for UAV swarms where the LLM supplies structured semantic reasoning and the reinforcement-learning layer decides how agents should divide responsibility.1
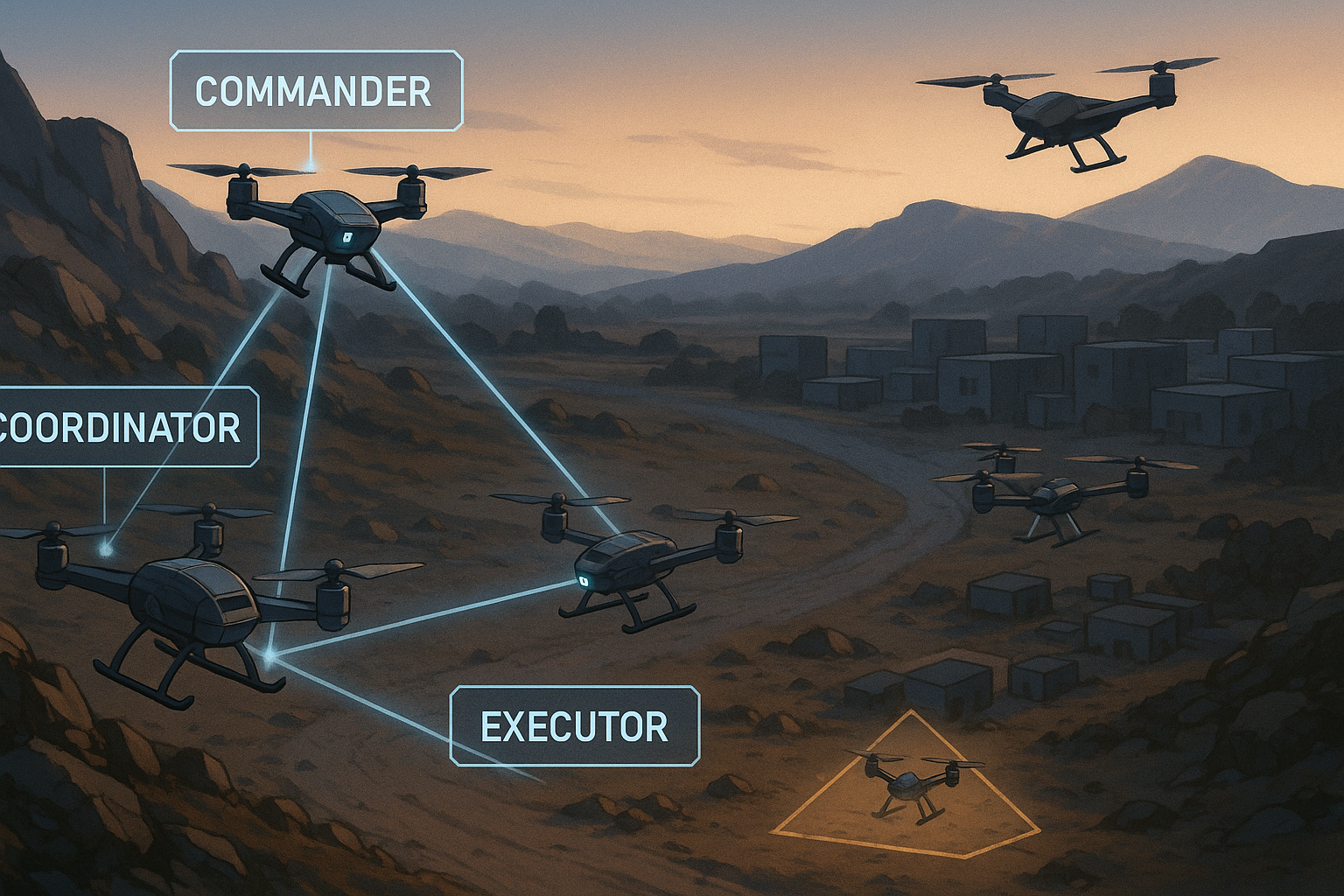
The practical insight is the separation of labour. A drone swarm does not only need to know where to fly; it needs to agree who should lead, who should coordinate, who should follow, and when those roles should change. RALLY handles that by combining two-stage LLM consensus with RMIX, a role-value mixing network trained to assign Commander, Coordinator, and Executor roles under partial observability and limited communication.
The evidence is strongest as simulation evidence. In Multi-Agent Particle Environment tests, RALLY reports higher average reward, narrower reward variance, faster convergence, and better generalisation than CIHRL, CoNavGPT, and DITTO. In Gazebo-ROS-PX4 SITL, it demonstrates distributed role switching and formation splitting under more realistic quadrotor dynamics. Useful, yes. A licence to deploy autonomous drone teams near humans tomorrow morning, no.
For businesses, the near-term relevance is not “replace UAV operators with LLMs”. The better reading is: semantic intent can make swarm coordination more interpretable, while learned role assignment can make it less brittle than fixed leader-follower architectures. That matters for inspection, disaster response, industrial monitoring, logistics, and security—especially where teams must split, regroup, and react to moving hazards.
The catch is deployment cost and latency. The paper tries to address this by distilling GPT-4o-style reasoning into smaller LoRA-fine-tuned Qwen2.5 models, with the 1.5B model used in the SITL setup as a balance between decision quality and inference overhead. The result is promising architecture work, not a final field system.
The hard part of swarm autonomy is agreement, not movement
A single drone is already a stack of compromises: sensing, planning, control, payload, battery, weather, regulation, and the minor inconvenience that gravity remains undefeated. A swarm adds a more interesting problem: every drone sees only part of the world, communicates with only some neighbours, and still has to behave as if the group knows what it is doing.
That is the setting for RALLY: Dynamic Swarm coordination with Cooperative Evasion and Formation Coverage, or DS-CEFC. In this task, a group of UAVs must cover target regions in formation while avoiding obstacles and an adversarial pursuer. Coverage only matters when enough agents cluster at a target. Clustering, unfortunately, also makes them attractive to the enemy. The swarm must therefore keep solving a moving organisational problem: when to gather, when to split, where to go, and which agent’s local view deserves authority.
Traditional multi-agent reinforcement learning can adapt online, but its communication often happens through opaque numerical vectors. That is efficient for tensors, less efficient for humans trying to understand why eight UAVs suddenly flew into a bad idea. Pure LLM-based planning has the opposite problem. It can reason semantically and explain itself, but without online reinforcement feedback it can become static, greedy, or overconfident. A familiar résumé, really.
RALLY’s main contribution is to avoid choosing between those two weaknesses. It lets the LLM reason in language about intent and neighbourhood context, then lets RMIX learn which role assignment is actually valuable for the group.
RALLY’s control loop: local observation becomes role-aware consensus
The paper’s architecture is easiest to understand as a loop:
local observation
↓
LLM initial intent
↓
RMIX role selection
↓
neighbour communication
↓
LLM consensus refinement
↓
navigation and flight-control execution
The high-level module is where RALLY lives. The paper assumes a mid-layer navigation policy and low-layer PID flight control are already available, then focuses on learning the high-level consensus policy. That matters because the LLM is not directly generating motor commands. It is selecting target-region intent within a structured swarm-navigation hierarchy.
Each UAV begins with a local observation: its own position and velocity, enemy position and velocity, target information, and neighbour information within an observation radius. In the experimental setting, the observation distance is 3 metres, simulations run for 1,000 steps, and every 50 steps the UAVs select target regions. Target candidates are drawn from a grid based on coordinates such as $(-8,0,8)$ across the two axes.
The LLM first produces an initial target intention from structured prompts. Then RMIX selects the agent’s role. Then the agent exchanges information with neighbours and constructs a second prompt containing its own intent, assigned role, neighbours’ roles, neighbours’ target preferences, and environmental constraints. The LLM then refines the final consensus target.
The design choice is subtle. The first LLM call asks, roughly: “Given what I see, where should I go?” The second asks: “Given what I see, who I am in the team, and what my neighbours intend, where should we converge?” That second question is where the paper’s mechanism actually lives.
Commander, Coordinator, Executor: hierarchy without a permanent boss
RALLY uses three core roles:
| Role | Behaviour in the paper | Operational interpretation |
|---|---|---|
| Commander | Focuses on strong individual reward and tends to select the personally best target | Local leader when the agent has a useful vantage point or strong target opportunity |
| Coordinator | Balances individual and team gains, often mediating Commander choices | Middle layer that prevents local optimisation from becoming group stupidity |
| Executor | Mainly follows Coordinator guidance, with fallback behaviour if needed | Stabilising follower that helps turn consensus into formation behaviour |
This is not a fixed chain of command. RMIX dynamically assigns roles based on local observation and expected contribution to group reward. That is important because static role assignment breaks down when the swarm grows, targets move, or threats reshape the environment.
The paper’s qualitative example with Agent #6 is the cleanest illustration. In the initial LLM-only phase, the agent sees itself as safe, identifies a scoring opportunity near $(-8,8)$, and greedily adopts the Commander role. The role policy then overrides it to Coordinator. That changes the agent’s function from “my best local move” to “support the group’s alignment”. The final consensus still recommends $(-8,8)$, but for a different reason: not isolated scoring, but coordinated team consistency.
That distinction matters. Two systems can output the same coordinate while making very different decisions. One got lucky. The other understood why the coordinate should be shared.
RMIX is the part that stops language from becoming theatre
The LLM makes RALLY interpretable. RMIX makes it trainable.
In multi-agent tasks, assigning credit is difficult because the reward is collective. If the swarm succeeds, which drone’s role choice mattered? If it fails, which agent caused the collapse? Instantaneous reward does not reliably answer that. RALLY uses RMIX to aggregate individual role-value estimates into a global value estimate while preserving monotonic value factorisation: improving an individual role-value should not reduce the global value estimate.
The paper seeds RMIX with offline experience generated using GPT-4o role suggestions, then continues with online cooperative training under a CTDE-style setup. This is a practical compromise. Starting from pure online exploration across all role combinations would be expensive and noisy, especially because the joint role space grows quickly with the number of agents and roles. GPT-4o provides a reasonable prior; RMIX then learns which role assignments actually help under task rewards.
This is where the “LLM plus RL” label is less hand-wavy than usual. The LLM does not replace the reinforcement learner. It reduces the cold start and provides structured semantic candidates. RMIX supplies the feedback loop that punishes beautiful but useless reasoning.
The theory is a guardrail, not a magic certificate
The paper includes a theorem arguing that the two-stage policy should outperform a one-stage baseline under two assumptions: monotonic value factorisation and the idea that extra contextual reasoning improves action-value quality. That is a useful formal sanity check, but it should not be overread.
The theorem does not prove that any LLM prompt will improve any swarm. It says that if the consensus stage genuinely improves local value estimates, and if the mixing network preserves monotonic improvement into the global value, then the two-stage setup yields higher expected return than a one-stage policy. Fair enough. Also, gravity still waits for implementation details.
For operators, the useful point is narrower: the architecture is designed so that extra context can help rather than merely add text. The neighbour-aware consensus step is connected to a value-mixing mechanism that can evaluate whether role-conditioned choices improve group reward.
What the experiments actually test
The paper’s experimental section is doing several jobs at once. Treating every figure as “proof RALLY is better” would be lazy. The better reading is to separate main evidence, ablation, robustness, and deployment checks.
| Test or figure | Likely purpose | What it supports | What it does not prove |
|---|---|---|---|
| Fig. 6 baseline comparison | Main evidence and comparison with prior work | RALLY achieves the highest mean reward and narrowest variance over 30 test episodes against CIHRL, CoNavGPT, and DITTO | Field readiness or safety under real-world uncertainty |
| Fig. 7 RMIX vs VDN | Credit-assignment comparison | RMIX converges faster and estimates cumulative returns more accurately than a simpler weighted-sum VDN-style aggregation | That RMIX is optimal for every swarm-control task |
| Fig. 8 Qwen2.5-7B LoRA loss | Implementation detail | Fine-tuning converges, with validation beginning at step 500 | Mission success by itself |
| Fig. 9 changing swarm size | Generalisation/robustness test | RALLY handles 9, 10, and 11 agents better than CIHRL after training on the original configuration | Arbitrary swarm scaling |
| Fig. 10 target grid variation | Sensitivity test | RALLY remains stable across 3×3, 2×4, and 4×2 target layouts | Generalisation to all geographies, sensors, or mission rules |
| Fig. 11 Agent #6 trace | Mechanism illustration | Role reassignment can correct an isolated Commander bias | Statistical superiority by itself |
| Fig. 12 role count variants | Ablation | Three roles outperform simpler or more granular role structures in this setup | That three roles are universally optimal |
| Fig. 13–14 fine-tuning and model scale | Deployment-oriented ablation | Smaller fine-tuned Qwen2.5 models can recover useful reasoning while reducing overhead | That onboard deployment is solved |
| Fig. 16 SITL sequence | High-fidelity validation case | RALLY can run through distributed consensus and role switching in Gazebo-ROS-PX4 | Real outdoor flight validation |
The main performance result is the baseline comparison. RALLY reports the strongest reward distribution and consistency. CIHRL is stable but modest. CoNavGPT benefits from LLM environmental reasoning but lacks online exploration. DITTO gains from role-based LLM collaboration but remains unstable because its role choices are greedy and lack reinforcement feedback.
This is exactly what the architecture predicts. Pure MARL underuses semantic structure. Pure LLM planning underuses environmental feedback. RALLY gets leverage by refusing to be pure.
Generalisation: prompts help the swarm avoid habitual grouping
The generalisation result is especially relevant for business use because real operations rarely preserve the training configuration. Inspection routes change. Disaster zones change. Some drones fail. Communication graphs mutate. A system that only works for yesterday’s formation is less a swarm than a choreographed dance routine with batteries.
The paper tests changing swarm sizes from 8 to 9, 10, and 11 agents. CIHRL degrades as the swarm grows beyond the training configuration. The authors describe this as “habitual grouping”: agents repeatedly form learned clusters instead of adapting to cover additional targets. RALLY avoids this by encoding formation constraints into the prompt, allowing the swarm to split consensus and avoid excessive clustering.
The same pattern appears in target-layout variation. RALLY is evaluated across a 3×3 grid, a 2×4 grid, and a 4×2 grid, with target locations randomly generated. The paper reports no significant reward difference across those layouts.
This is not universal general intelligence. It is more specific and more useful: semantic constraints can help a policy generalise across structured mission variations that would otherwise require retraining or careful engineering.
Too few roles underfit; too many roles become coordination tax
The role-number ablation is one of the more business-relevant parts of the paper because it undermines the usual “more agent specialisation is better” instinct.
The authors compare four configurations: a single Executor role, two roles with Commander and Executor, three roles with Commander, Coordinator, and Executor, and four roles that add a Decoy. The three-role setup gives the best balance of performance and stability. Single-role control lacks task decomposition. Two roles improve mean reward but increase variance, suggesting that Commander-driven behaviour can become unstable. Four roles add a Decoy but reduce average reward and increase variance, implying that extra role granularity creates coordination overhead.
This is a useful product lesson. Role design is not taxonomy design. Adding another label does not automatically create capability. In a real operations platform, every extra role adds policy complexity, monitoring burden, failure modes, and operator training. RALLY’s result says the middle layer—the Coordinator—is the valuable addition. The Decoy is the fun one. Naturally, the fun one is expensive.
Edge deployment is partially addressed, not solved
A UAV swarm cannot depend comfortably on round-tripping every decision to a frontier cloud model. Latency, bandwidth, availability, energy, and security all object. Loudly.
RALLY addresses this through capacity migration. GPT-4o is used to generate high-quality instruction samples. The authors then filter invalid or low-quality outputs and fine-tune smaller Qwen2.5 models with LoRA. In the paper’s setup, they create 50 manually labelled few-shot examples, use GPT-4o for API-driven data collection, and after simulation and filtering accumulate 8,231 samples for fine-tuning Qwen2.5-7B.
The deployment comparison is useful because it includes runtime metrics on an NVIDIA RTX 4090:
| Model | Average inference time | Memory footprint | Runtime overhead |
|---|---|---|---|
| Qwen2.5-7B | 15.39 s | 15.0 GB | 15.7 GB |
| Qwen2.5-3B | 17.63 s | 5.8 GB | 7.17 GB |
| Qwen2.5-1.5B | 14.48 s | 2.9 GB | 4.13 GB |
| Qwen2.5-0.5B | 15.45 s | 1.2 GB | 1.77 GB |
The paper identifies Qwen2.5-1.5B as the best balance between decision quality and overhead, and uses the fine-tuned 1.5B model in the SITL validation. The 0.5B model is lighter, but the paper’s model-scale results show that smaller is not automatically better once task quality is included.
The business interpretation is straightforward: local models can reduce cloud dependence, but inference time remains material. A 14–18 second decision cycle can be acceptable for high-level consensus in slow formation coverage. It is not acceptable for fast collision avoidance, which is why RALLY keeps lower-level control outside the LLM. Again: the chatbot is not flying the drone. The flight stack is.
SITL validation moves closer to robotics, but not all the way to deployment
The Gazebo-ROS-PX4 SITL validation is a meaningful step beyond abstract particle simulation. The paper models quadrotor dynamics, uses PX4 with PID control, runs independent off-board Python controllers per UAV, communicates through MAVROS over UDP, and converts RALLY’s target-region output into horizontal acceleration commands.
The scenario sequence is useful. At time-step 17, UAV #2 takes the Commander role and leads the group toward an upper-right scoring zone. At time-step 39, the enemy approaches, and the swarm splits: UAVs 3, 5, and 8 form a three-agent squad while the remaining five form another team. UAV #7 acts as Coordinator and positions itself to disturb the enemy’s pursuit vector. At time-step 43, that disruption changes the enemy’s trajectory, opening a route for the other drones. By time-step 62, both sub-clusters complete coverage of their respective scoring regions.
This validates the mechanism under a more realistic control loop. It does not validate weather, GPS degradation, wind, battery limits, sensor noise at production levels, adversarial communication failure, legal constraints, or human safety. SITL is where robotics papers become more credible. It is not where procurement teams should stop asking questions.
What this means for business adoption
The business case for RALLY-like systems is not a generic “AI makes drones smarter”. That sentence should be billed as hazardous waste.
The useful business pathway is more precise:
| Paper result | Business interpretation | Boundary |
|---|---|---|
| LLM prompts turn local observations into role-aware intent | Operators may gain more interpretable swarm decisions than opaque vector communication | Prompt sensitivity and illegal outputs still require guardrails |
| RMIX dynamically assigns roles | Swarms can adapt team structure without fixed leader-follower assumptions | Learned role policies depend on task reward design and training environment |
| RALLY generalises better than CIHRL to larger swarms and target layouts | Potentially lower retraining burden for structured mission changes | Tested only within controlled DS-CEFC variations |
| Fine-tuned smaller Qwen2.5 models reduce overhead versus relying on GPT-4o online | Edge-style deployment becomes more plausible | Inference latency and hardware assumptions remain significant |
| SITL shows role switching under PX4/Gazebo dynamics | The architecture can interact with a robotics stack | Still not live flight, certification, or safety-case evidence |
The most plausible early commercial use is decision support or supervised autonomy for controlled environments: industrial inspection zones, warehouse yards, perimeter monitoring, disaster-response simulations, or training systems where operators can review semantic swarm decisions. Fully autonomous open-environment deployment would require a much heavier safety and validation stack.
The strategic point is that RALLY suggests a design pattern: separate semantic coordination from low-level control, and separate role reasoning from role credit assignment. That pattern can transfer beyond UAVs. Warehouse robots, maritime drones, emergency-response agents, and mixed human-machine teams all face the same organisational problem. Who leads? Who follows? Who mediates? Who changes role when the environment changes?
The boundary: RALLY is architecture evidence, not operational proof
The paper is strongest when read as architecture evidence. It shows that combining semantic consensus and learned role-value mixing can outperform several relevant baselines in the DS-CEFC setting. It also shows that smaller fine-tuned models can carry some of the reasoning load needed for distributed deployment.
But several boundaries matter.
First, the task is stylised. Targets, urgency, enemy behaviour, observation radius, role definitions, reward weights, and formation rules are all engineered. That is normal for research, but it means the result should not be stretched into “works for drone swarms generally”.
Second, the LLM behaviour is prompt-sensitive. The appendix shows that different local contexts and roles produce different outputs, which is the point, but also the risk. The authors include fallback logic for illegal outputs, but production systems need much stronger validation around malformed decisions, adversarial inputs, and communication faults.
Third, the deployment story is incomplete. Fine-tuned 1.5B models are lighter than 7B models and avoid direct GPT-4o calls, but the reported inference times are still long enough that RALLY is clearly a high-level consensus system, not a reflex layer.
Fourth, SITL is not flight. It is a valuable bridge between MPE and hardware, but real UAV operations introduce failure modes that simulators politely leave outside the room.
The real contribution is not “LLMs for drones”; it is organisational control
RALLY’s interesting claim is not that LLMs can tell drones where to go. We already have enough systems telling things where to go, including several that have never met a risk assessment.
The interesting claim is that language can represent intent, role, and neighbour context in a form that is both machine-actionable and human-readable, while reinforcement learning can evaluate whether those roles actually contribute to group success. That is a cleaner division of labour than either black-box MARL communication or LLM-only planning.
For operators, this points toward a more mature model of agentic systems. The question is not whether an AI agent can make a plan. The question is whether a group of agents can continuously renegotiate responsibility under partial information, and whether the resulting behaviour can be inspected before it becomes expensive.
RALLY does not close that problem. It makes the shape of a credible answer easier to see.
Cognaptus: Automate the Present, Incubate the Future.
-
Ziyao Wang, Rongpeng Li, Sizhao Li, Yuming Xiang, Haiping Wang, Zhifeng Zhao, and Honggang Zhang, “RALLY: Role-Adaptive LLM-Driven Yoked Navigation for Agentic UAV Swarms,” arXiv:2507.01378, 2025. ↩︎