Spin Doctors: Why RL Fine‑Tuning Mostly Rotates, Not Reinvents
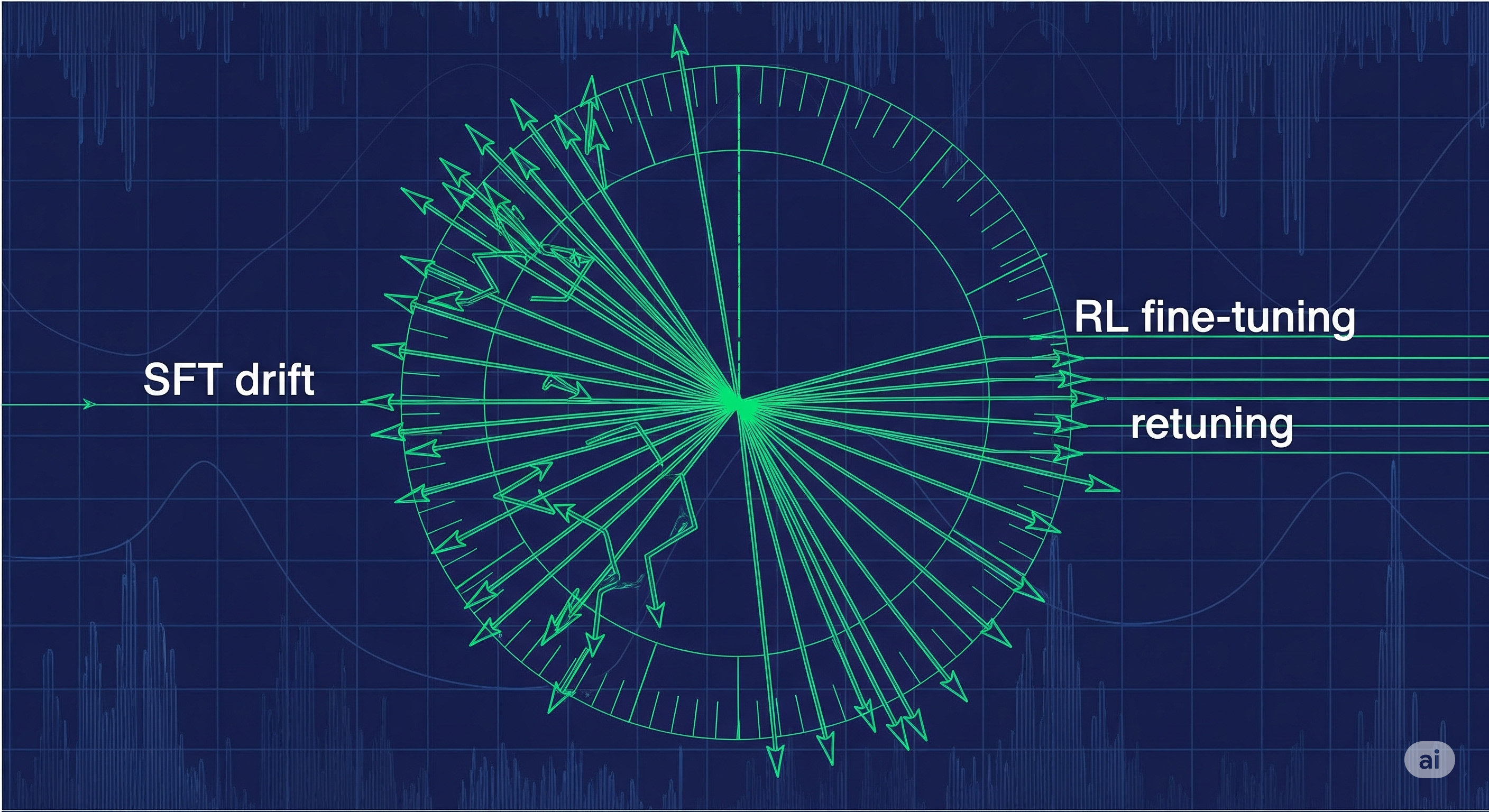
TL;DR for operators If your fine-tuned model gets better on the training task while quietly becoming worse outside it, the problem may not be that the model “lost intelligence”. It may have rotated its useful internal directions away from broadly generalizable behaviour. The paper behind this article studies SFT followed by PPO-style RL on two open LLMs using a controlled arithmetic benchmark, then inspects the weight matrices through singular-value decomposition.1 The pattern is clean enough to be operationally interesting: OOD performance peaks early during SFT, falls as SFT continues, and can be substantially restored by RL when the SFT checkpoint is only moderately degraded. But if SFT pushes the model too far into a specialized regime, RL is no longer a reliable rescue crew. Apparently even reinforcement learning has limits. Who knew. ...