MoA vs. Moat: Agentic LLMs for Drug Competitor Mapping Cut Diligence Time 20×
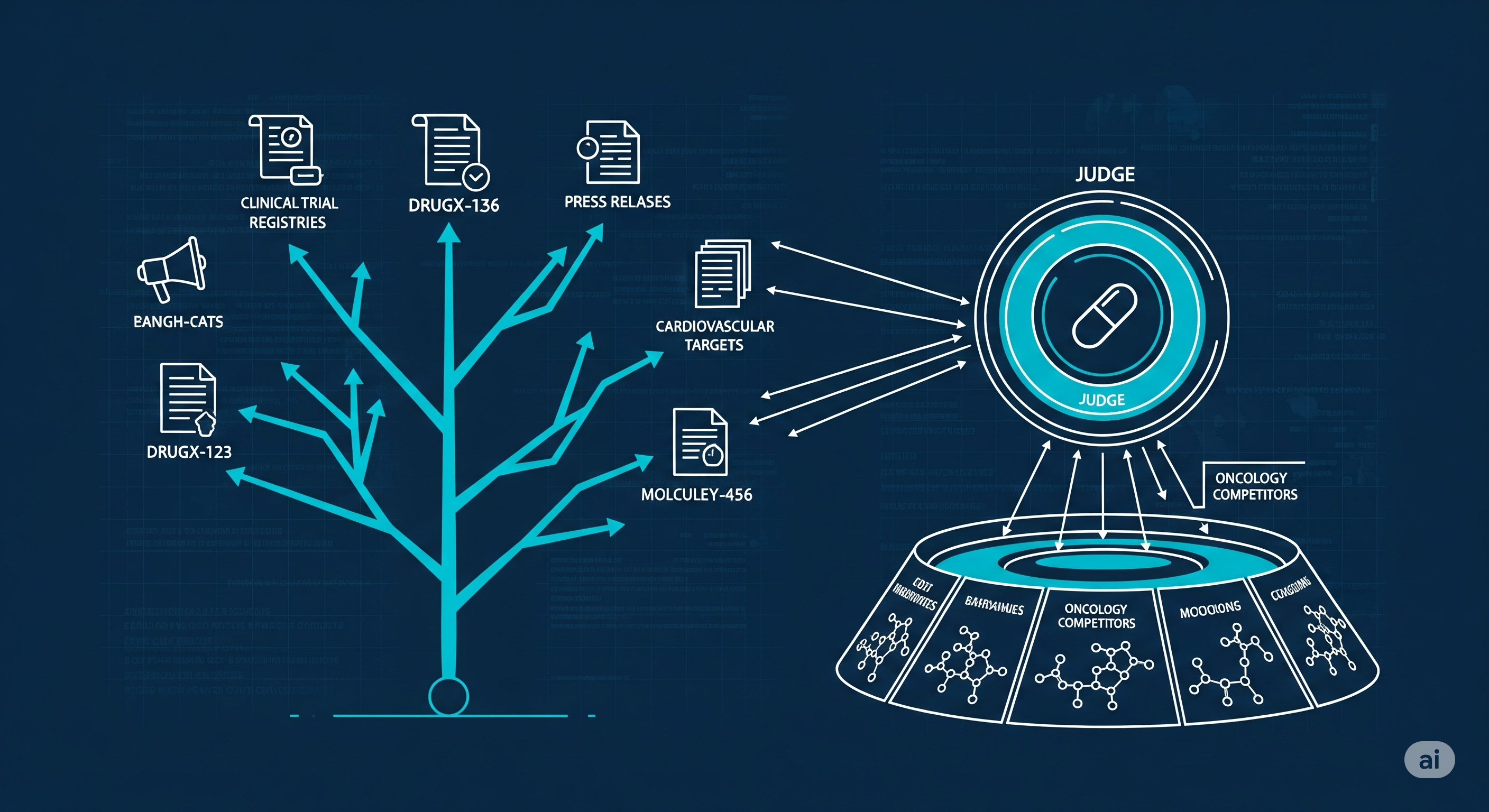
TL;DR for operators A recent arXiv paper on LLM-based agents for drug-asset due diligence shows something more useful than “AI does research now.” It shows a practical operating pattern: convert past expert memos into a measurable benchmark, send a persistent web-search agent to maximise competitor recall, then pass candidates through a stricter validator before analysts see them.1 ...