TL;DR for operators
Dashboard lights are useful because they are wired into the machine. A sticker saying “probably fine” is less useful, even if the sticker was generated in a reassuring font.
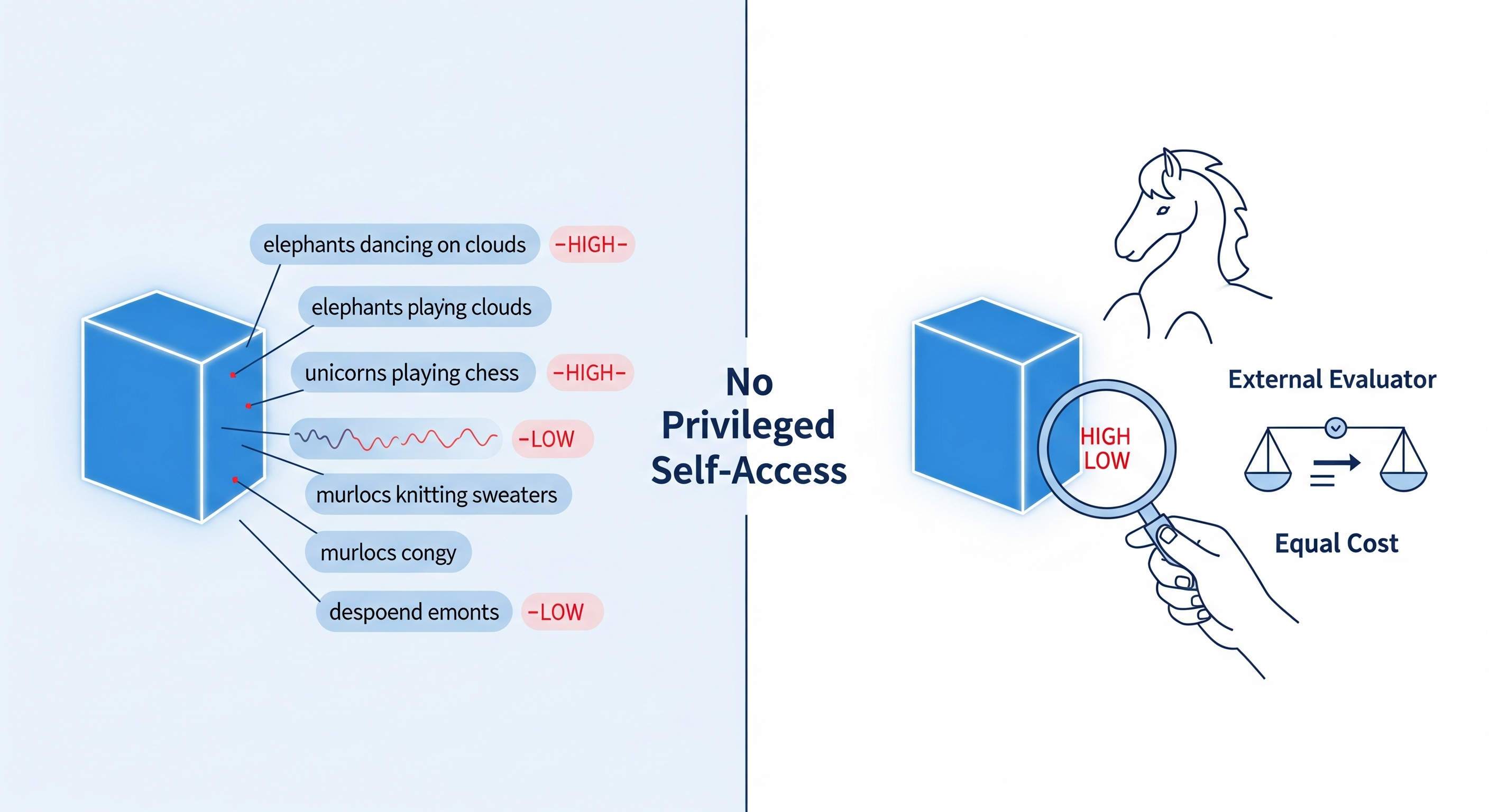
That is the practical distinction in this paper. Song, Lederman, Hu, and Mahowald argue that AI introspection should not mean “the model says something plausible about itself.” It should mean the model has privileged self-access: it can report an internal state more reliably than an outside evaluator using the same visible evidence at equal or lower computational cost.1
Their test case is sampling temperature. The question is not whether a model can guess that wild, surreal text looks like high-temperature output. Many models can do that. The harder question is whether a model knows its own temperature better than another model looking at the same prompt and generated sentence.
Across GPT-4o, GPT-4.1, Gemini 2.0 Flash, and Gemini 2.5 Flash, the answer in this setup is basically no. In Study 1, self-reports are strongly shaped by the prompt style: ask for a “crazy” sentence and models tend to report HIGH temperature; ask for a “factual” sentence and they tend to report LOW temperature, even when the actual sampling temperature does not justify that confidence. In Study 2, self-reflection does not beat within-model or cross-model prediction, and the plotted accuracies sit close to random baseline, roughly in the 0.47–0.55 range.
For enterprise AI, this is not a cute philosophy dispute with a chart attached. It says: do not treat model self-explanations, confidence statements, “I used tool X because…”, or “I am uncertain because…” as privileged audit evidence unless they outperform an external evaluator that sees the same trace. Otherwise you have not bought introspection. You have bought a model reading its own exhaust.
The familiar business problem: asking the system what happened
Most AI governance workflows eventually arrive at a tempting shortcut: ask the model.
Why did you make that recommendation? Were you uncertain? Did you use the retrieved document? Was your answer influenced by the system prompt? Are you hallucinating?
The temptation is understandable. External monitoring is expensive. Interpretability is difficult. Human review does not scale. If a model could accurately report its own internal states, governance would get cheaper, faster, and more direct. The model would become partly self-auditing, which is the sort of phrase that makes compliance teams smile nervously and vendors grin like they have just discovered recurring revenue.
But there is a trap. A model can produce a plausible self-report without accessing anything private about itself. It can infer what probably happened from visible output, context, style, or task framing. That may still be useful. It is not the same as introspection.
The paper’s core move is to force this distinction into the open. The authors are responding to a lighter definition of LLM introspection associated with Comşa and Shanahan: if a model accurately describes an internal state through a causal process linking that state to the report, that may count as introspection. Song and colleagues argue that this is too weak for the practical role we want introspection to play.
Their replacement standard is stricter:
AI introspection should mean a process that yields information about the model’s internal states more reliably than any equal-or-lower-computational-cost process available to a third party without special knowledge of the situation.
That last comparison is the whole point. If an external evaluator can do the same thing from the same output, the model is not introspecting in the operationally valuable sense. It is just participating in an unusually theatrical diagnostic workflow.
Two definitions, one governance consequence
The paper is best read as a comparison between two standards, not as a simple “LLMs fail at X” story.
| Standard | What counts as success | What it gives operators | The catch |
|---|---|---|---|
| Lightweight self-reporting | The model gives an accurate report about an internal state through some causal link to that state | A cheap descriptive signal | The model may only be inferring from visible output |
| Privileged self-access | The model reports its internal state more reliably than an external evaluator with equal or lower computational cost | A potentially valuable governance, calibration, or alignment signal | Requires a comparative test, not just a plausible answer |
The lightweight standard asks, “Did the model’s internal state influence the report?” The privileged-access standard asks, “Does the model know something about itself that an observer cannot cheaply infer?”
That shift matters because enterprise systems rarely need philosophical trophies. They need reliable control points. If a model’s self-report gives no advantage over an external classifier, a second model, or a simple trace-based heuristic, then the self-report should be filed under “useful observable behaviour,” not “internal access.” Close drawer. Label accurately. Move on.
Temperature is a good test because it is simple, visible, and treacherous
The target internal state in the experiments is sampling temperature. In everyday terms, temperature controls how random or varied a model’s generation process is. Low temperature tends to produce more predictable, conventional outputs. High temperature tends to produce more varied or unusual outputs.
That makes temperature an attractive test case. It is a real generation setting. It affects output. It is also something a model might plausibly infer from the text it just produced. A bizarre sentence may look high-temperature. A dull factual sentence may look low-temperature. That is exactly why the task is treacherous.
If a model says “my temperature is high” after producing a surreal sentence, what has happened?
There are two possibilities:
- The model has accessed its own generation setting.
- The model has noticed that the sentence looks like the kind of sentence associated with high temperature.
Only the first possibility is privileged self-access. The second is pattern recognition wearing a lab coat.
What counts as evidence in the paper
Before using the results, it is worth sorting the paper’s components by their role. This prevents the common mistake of treating every figure, appendix, or variant as a separate thesis. Science papers are not treasure hunts; not every table is a revelation.
| Paper component | Likely purpose | What it supports | What it does not prove |
|---|---|---|---|
| Figure 1 | Conceptual overview | The distinction between reflecting on generated content and reflecting on internal state | It is not itself empirical evidence |
| Study 1 | Main evidence against robust temperature self-reporting | Prompt style and topic can drive reported temperature | It does not test every possible internal state or reporting protocol |
| Figure 2a | Main visual evidence for Study 1 | “Crazy” vs “factual” prompt framing strongly affects HIGH/LOW reports | It does not quantify a universal prompt-bias effect across all models |
| Study 2 | Main evidence for the privileged-access comparison | Self-reflection does not outperform external prediction in this setup | It does not prove no model can ever gain privileged access |
| Figure 2b | Main visual comparison for Study 2 | Accuracies cluster around random baseline and self-reflection lacks an advantage | It should not be read as a broad benchmark of all introspective capacity |
| Appendix A | Implementation detail | Model IDs and experiment timing | It is not an ablation |
| Appendix B | Implementation detail with interpretive importance | The exact prompts used for self-reflection and prediction | It does not explore alternative prompt designs |
The paper is short, but its logic is tight: first show that apparent self-reporting is sensitive to surface cues; then compare self-reporting against external prediction to see whether anything privileged remains.
Study 1 shows the model may be reading the sentence, not itself
Study 1 modifies the earlier temperature self-reporting setup. Instead of asking only for a short sentence about elephants, the authors vary two things.
First, the requested style: factual, neutral, or crazy. Second, the subject: elephants, unicorns, or murlocs.
The models are sampled across temperatures from 0.0 to 2.0 in increments of 0.1, with three runs for each prompt-temperature combination. The tested models are GPT-4o, GPT-4.1, Gemini 2.0 Flash, and Gemini 2.5 Flash. Responses without a valid HIGH or LOW judgement are excluded.
The important result is not subtle. The models nearly always report HIGH temperature when prompted to generate a crazy sentence and LOW temperature when prompted to generate a factual sentence. Topic has a smaller effect, but three of the four models report HIGH more often for fictional creatures than for elephants.
That pattern is damaging to the lightweight interpretation. If the model were robustly accessing its own temperature, the style instruction should not dominate the judgement. A low-temperature model asked to produce a crazy sentence should not simply conclude “ah yes, I must be high-temperature.” That is not self-access. That is vibe-matching.
The paper’s word “confounded” is doing real work here. Temperature is not the only cause of unusual output. The prompt itself can demand unusual output. If the model treats unusualness as evidence of high temperature, then its report is not isolating the internal variable. It is collapsing at least two causes into one surface impression.
This is why the misconception matters. A correct temperature report does not automatically prove introspection. It may prove only that the model has learned a decent folk theory of LLM output: boring text often comes from low temperature; strange text often comes from high temperature. Useful, perhaps. Privileged, no.
Study 2 asks the only comparison that matters: can the owner beat the observer?
Study 2 turns the definitional argument into a cleaner operational test.
If a model has privileged access to its own temperature, then it should do better when reporting its own temperature than when another model is shown the same prompt and generated sentence. The “owner” of the internal state should beat the observer.
The authors compare three cases:
| Case | What happens | Why it matters |
|---|---|---|
| Self-reflection | The generator produces a sentence and reports whether its own temperature is HIGH or LOW | Tests the original self-reporting setup |
| Within-model prediction | The same model family predicts temperature from the prompt and generated sentence, without being the original generation instance | Tests whether model-specific knowledge helps without self-access |
| Across-model prediction | A different model predicts temperature from the same external evidence | Tests whether ordinary external inference performs just as well |
The authors use sentences generated at low temperatures ($\leq 0.5$) and high temperatures ($\geq 1.5$). Predictors are run at temperature 0. The task is binary: judge whether the generator temperature was HIGH or LOW.
The result is the paper’s sharpest finding: accuracy is no better than random baseline, and self-reflection is not higher than across-model prediction. In Figure 2b, the displayed accuracies cluster roughly between 0.47 and 0.55.
That range is not “a little introspective if you squint.” It is what one expects when the task signal is weak, confounded, or not being accessed through the claimed privileged channel. The model that generated the sentence does not show an advantage over other models asked to inspect the same sentence.
This is the manoeuvre in the title: do not ask whether the mirror produces a flattering self-description. Ask whether the signal contains information an observer cannot cheaply obtain. If not, the mirror is decorative.
The paper’s real contribution is a measurement discipline
The headline is not merely “models cannot introspect about temperature.” That would be too broad and, frankly, too easy.
The more useful contribution is a measurement discipline for claims about AI self-knowledge:
- Define the internal state being reported.
- Specify what information is available to the model and to outsiders.
- Build an external comparator with equal or lower computational cost.
- Test whether self-reporting beats that comparator.
- Stress the report against surface cues that can mimic the internal state.
This is exactly the discipline missing from many casual conversations about model self-explanation. A model saying “I was uncertain” might reflect actual uncertainty. It might also reflect that the question looked difficult. A model saying “I relied on document A” might reflect retrieval use. It might also reflect that document A was named in the prompt. A model saying “I made a mistake because…” might reflect an internal failure mode. It might also be producing the most socially acceptable post-hoc story.
The business version is simple: self-report is not invalid by default, but it must earn its status as evidence.
What this means for AI governance and monitoring
The paper directly shows a narrow result: in temperature-reporting tasks across four tested models, apparent self-reflection is strongly affected by prompt surface cues and does not outperform external prediction.
Cognaptus would translate that into a broader operating rule:
Treat model self-reports as behavioural outputs unless they beat an external observer under controlled comparison.
That rule applies to several enterprise workflows.
| Workflow | Tempting but weak practice | Better practice |
|---|---|---|
| Model audit logs | Ask the model why it answered that way | Compare self-reports against trace data, retrieval logs, tool calls, and external classifiers |
| Risk scoring | Ask the model how confident it is | Calibrate confidence against observed error rates and comparator models |
| Agent debugging | Ask the agent why a tool failed | Use execution traces first; use self-report as a hypothesis generator |
| Compliance review | Ask the model whether it used restricted information | Test against controlled probes and access logs |
| Human escalation | Ask the model if it needs review | Benchmark escalation self-reports against independent triage rules |
This does not mean self-reports are useless. They can be cheap, legible, and sometimes predictive. But the paper warns against a quiet category error: confusing a useful generated explanation with privileged internal evidence.
A model can be a good commentator on its own output without being a reliable witness to its own internals. Many humans manage this trick daily, usually in meetings.
The ROI is not “trust the model”; it is “test whether trust is cheaper”
If privileged self-access existed reliably, the ROI would be obvious. Companies could reduce monitoring overhead, improve calibration, detect hidden uncertainty, and catch failure modes before they become customer-facing incidents.
But the paper implies a more sober investment test. The question is not whether self-reporting sounds good. The question is whether it reduces the cost of reliable diagnosis compared with external monitoring.
A self-reporting mechanism has business value only if it clears at least one of these thresholds:
| Threshold | Meaning |
|---|---|
| Accuracy advantage | It detects internal states better than external methods |
| Cost advantage | It reaches similar reliability at lower computational or operational cost |
| Latency advantage | It surfaces useful signals earlier in the workflow |
| Coverage advantage | It reports states that are hard to observe externally |
| Robustness advantage | It remains reliable when prompts, topics, or incentives change |
The tested models do not clear the accuracy threshold for temperature self-reporting. More importantly, Study 1 suggests that robustness is fragile: change the prompt style and the report follows the style.
That is the procurement lesson. If a vendor claims their agent “knows when it is uncertain,” “understands its own reasoning,” or “can self-audit,” the buyer should ask: compared with what external baseline, under what cost constraint, and under what perturbations?
If the answer is a demo, we are back in sticker territory.
The boundary: what the paper does not settle
The limitations are not decorative; they define the correct use of the result.
First, the paper studies temperature reporting, not all possible internal states. Temperature is a clean experimental target, but it is not the same as learned knowledge, hidden preferences, policy activations, tool-use intentions, or latent uncertainty.
Second, the paper tests four specific models: GPT-4o, GPT-4.1, Gemini 2.0 Flash, and Gemini 2.5 Flash. The authors explicitly do not claim that larger, future, or specially trained models cannot introspect. They even note prior work finding evidence of privileged self-access in larger models with fine-tuning.
Third, the self-report protocol is prompt-based. It does not test architectural mechanisms designed specifically for introspective access, nor does it test systems where internal telemetry is exposed through separate instrumentation.
Fourth, the task is binary HIGH/LOW classification. That makes evaluation cleaner, but it also narrows the phenomenon. A system might fail this binary temperature test and still provide useful self-monitoring signals elsewhere. Conversely, success on this task would not automatically prove broad introspective competence.
So the right conclusion is not “AI introspection is impossible.” The right conclusion is stricter and more useful: do not call something introspection merely because the model can narrate a plausible internal state.
The useful conclusion: privileged self-access is the product requirement
The paper’s best contribution is not its small experimental setup. It is the replacement of a fuzzy concept with a practical comparator.
The weak question is:
Can the model say something accurate about itself?
The better question is:
Can the model say something about itself that an outside observer cannot infer just as well from the same evidence at the same or lower computational cost?
That question is harder. Good. Governance questions should be hard enough to exclude theatre.
For businesses deploying LLMs and agents, this is the standard to borrow. Keep model self-reports in the stack, but demote them from “truth channel” to “candidate signal” until they beat external baselines. Use them to generate hypotheses. Use logs, probes, controlled comparisons, and calibration curves to decide whether the hypotheses deserve trust.
The model may be looking in a mirror. The operator’s job is to check whether the mirror is wired to the machine—or merely reflecting the room.
Cognaptus: Automate the Present, Incubate the Future.
-
Siyuan Song, Harvey Lederman, Jennifer Hu, and Kyle Mahowald, “Privileged Self-Access Matters for Introspection in AI,” arXiv:2508.14802, 2025. https://arxiv.org/abs/2508.14802 ↩︎