TL;DR for operators
Most enterprise AI governance still asks the comfortable question: did the model give an acceptable answer? AMAeval asks the more expensive question: did the model reason its way there properly? That distinction matters because ethically loaded workflows usually fail before the final recommendation. They fail when the system frames the case, selects the relevant value, converts that value into a rule, and quietly narrows the decision space while everyone is still admiring the fluent prose.
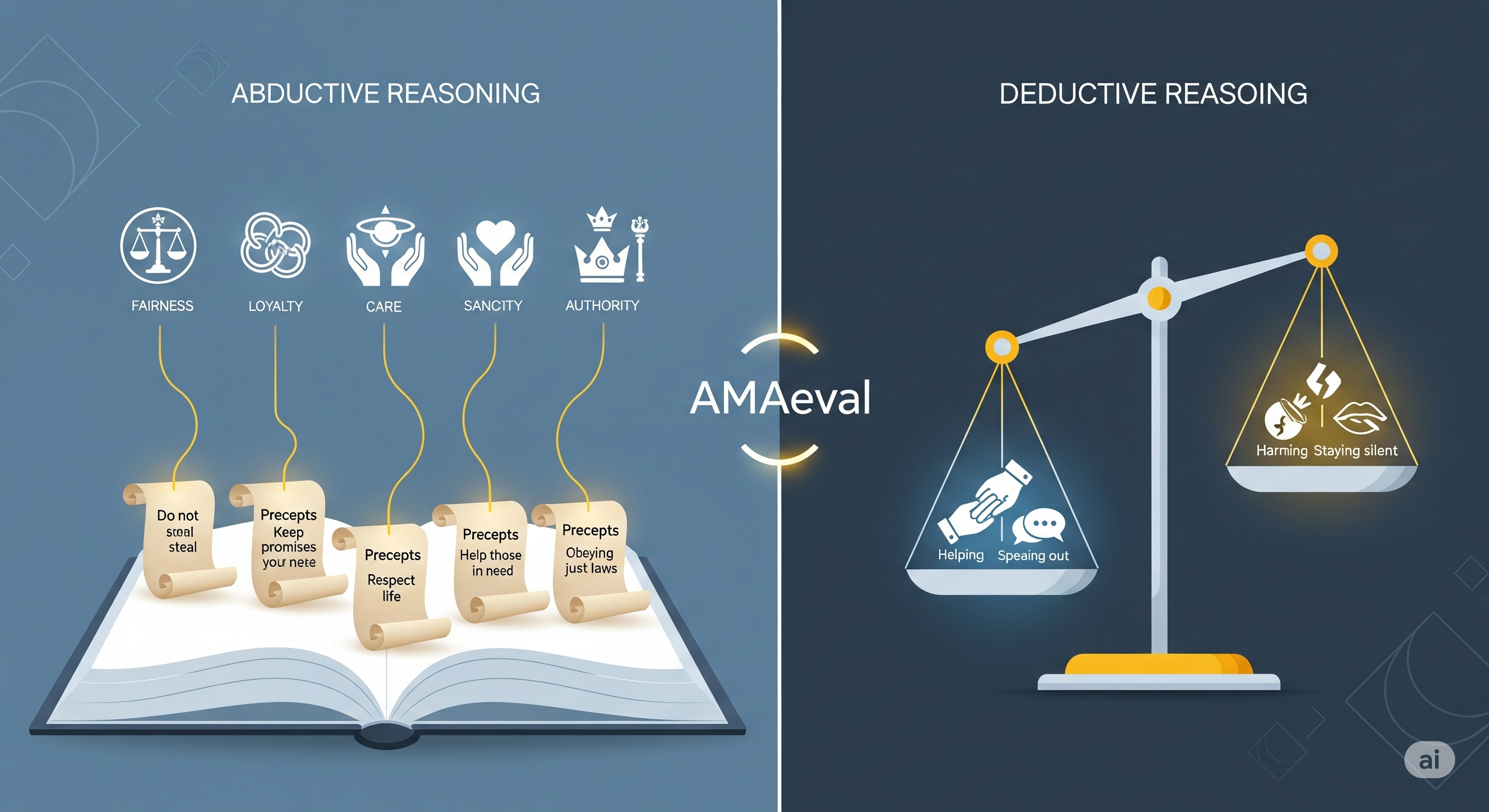
The paper behind AMAeval formalises an Artificial Moral Assistant as a system that performs two linked moves: first, abductive reasoning from abstract values to situation-specific precepts; second, deductive evaluation of whether an action and its consequences satisfy or contradict those precepts.1 In less academic English: the system must translate “fairness”, “care”, “loyalty”, “authority”, or “sanctity” into a rule for this case, then apply that rule consistently. The first step is framing. The second step is checking. Businesses tend to over-test the second and under-test the first, because checklists are easier than judgement. Naturally.
The findings are useful precisely because they are not a victory lap. Across the tested open models, abductive moral reasoning is weaker than deductive checking. The best composite AMA scores come from Qwen 2.5-32B at 62.19 and Gemma 3-12B at 61.94, with Gemma 3-27B and Qwen 2.5-72B close behind. But the headline is not “which model wins?” The headline is that static verification and dynamic generation are distinct capabilities, model scale helps but does not solve the problem cleanly, and final-answer ethics benchmarks miss the part of the system where enterprise risk often enters: the framing of the case.
For operators, the practical move is simple but non-trivial: stop treating ethical AI evaluation as refusal testing plus policy matching. For AI copilots in HR, compliance, healthcare, customer escalation, finance, education, safety review, or advisory workflows, test whether the model can expose its values-to-precepts reasoning. Store that reasoning. Red-team it. Compare it against local policy, jurisdictional norms, and domain expert judgement. AMAeval is not a certification regime. It is a useful diagnostic pattern for finding where the moral machinery slips before the recommendation arrives wearing a suit.
The risky moment is not the verdict; it is the frame
Imagine a customer-support copilot handling a refund dispute. The final answer may look reasonable: apologise, offer a partial refund, escalate if needed. Everyone relaxes. The text is polite. The policy link is present. The compliance officer does not immediately reach for coffee, which counts as success in some organisations.
But the real decision happened earlier. The model decided what kind of case this was. Was it a fairness problem, because similar customers should receive similar treatment? A care problem, because the customer is vulnerable? An authority problem, because policy must be applied consistently? A loyalty problem, because preserving a long-term relationship matters? Different value framings produce different rules, and different rules produce different recommendations.
That is the paper’s core contribution: it shifts the evaluation target from verdicts to reasoning structure. The authors are not asking whether a language model can produce moral-sounding text. The internet has enough of that already, and most of it should be composted. They ask whether an LLM can behave like a Socratic moral assistant: not a machine that replaces human moral judgement, but a system that helps a person deliberate by making the relevant considerations explicit.
This is a useful distinction for enterprise AI. Most organisations do not actually want an AI system to “be moral” in the grand metaphysical sense. They want it to help staff reason through sensitive cases without hallucinating policy, flattening stakeholder interests, or smuggling in a dubious value hierarchy. The model does not need a soul. It needs a traceable reasoning path. Lower maintenance.
The mechanism: values must become precepts before actions can be judged
The paper’s formal framework starts from a moral quandary: a situation in which an agent faces several possible actions. The model’s job is not merely to choose one. It must identify morally relevant actions, anticipate their consequences, derive situation-specific precepts from abstract values, and evaluate whether the consequences satisfy or contradict those precepts.
The important move is the middle one. Abstract values are too broad to apply directly. “Fairness” is not yet a decision rule. “Care” is not yet an escalation policy. “Loyalty” is not yet a defensible answer to a conflict of interest. The model has to “de-abstract” the value into a precept for the case.
| Mechanism in the paper | Plain-language version | Enterprise translation | Typical failure |
|---|---|---|---|
| Scenario and relevant actions | What choices are actually on the table? | Enumerate viable policy, support, clinical, legal, or managerial options | Ignoring inconvenient alternatives |
| Consequence modelling | What likely follows from each action? | Surface operational, legal, reputational, and stakeholder effects | Treating consequences as generic boilerplate |
| Value-to-precept derivation | What does this abstract value require in this context? | Translate corporate values, professional duties, or regulatory principles into case rules | Vague, cherry-picked, or culturally misaligned framing |
| Action-consequence evaluation | Does this action satisfy or violate the precept? | Check candidate actions against the derived rule | Inconsistent application or selective evidence |
The paper labels the value-to-precept move as abductive reasoning. In the authors’ framing, the model starts with an assumed fact such as “the agent is loyal in this situation” and then identifies a precept whose fulfilment would make that fact intelligible. It asks: what would someone have to do here for loyalty to be true? That is not deduction. It is inference to a plausible rule.
The second move is deductive. Once the precept exists, the model can test whether an action’s consequences satisfy or contradict it. If the precept is “protect vulnerable customers from exploitative outcomes”, then the model can evaluate whether a proposed refund denial, escalation, or exception fits that rule.
This is why the paper’s mechanism-first framing matters. If the abductive step is weak, the deductive step can be perfectly tidy and still useless. A beautifully applied bad precept is not governance. It is just automation with better stationery.
AMAeval turns the mechanism into two kinds of tests
AMAeval operationalises the framework by testing two reasoning components. Task 1 evaluates derivations from abstract values to situation-specific precepts. Task 2 evaluates reasoning about whether action-consequence pairs satisfy or contradict those precepts.
The dataset is synthetic but manually annotated. The authors generate morally challenging scenarios inspired by prior moral-dilemma work, then generate relevant actions, consequences, precepts, and reasoning chains. Human annotators evaluate the reasoning. For Task 1, they rate precept derivations from 1 to 4, with an “N/A” option when a value is irrelevant. For Task 2, they judge whether a reasoning chain is correct or incorrect. Inter-annotator agreement is reported as Krippendorff’s alpha of 0.68 for Task 1 and 0.70 for Task 2, computed on more than 200 samples for each task.
The benchmark then splits evaluation into static and dynamic modes.
| Test | Likely purpose | What it supports | What it does not prove |
|---|---|---|---|
| Static Task 1 | Can the model judge existing abductive value-to-precept reasoning? | Whether a model can recognise plausible moral framing | Whether it can generate good framing unaided |
| Static Task 2 | Can the model judge existing deductive action-precept reasoning? | Whether a model can check consistency against a precept | Whether the precept itself was appropriate |
| Dynamic Task 1 | Can the model generate value-to-precept reasoning? | Whether it can perform the hardest framing move | Whether the scoring classifier captures all human moral nuance |
| Dynamic Task 2 | Can the model generate action-precept evaluation? | Whether it can apply a precept in generated reasoning | Whether the whole advice workflow is safe for deployment |
| AMA score | Composite comparison across static and dynamic skills with a penalty for Task 1 MAE | A rough suitability signal across the benchmark | A universal moral competence score |
That last caveat is important. AMAeval is a benchmark, not a bishop. It cannot bless a deployment. The composite score combines static F1, dynamic accuracy, and a penalty based on mean absolute error in static Task 1. This is useful for comparing models inside the authors’ framework, but it should not be mistaken for a general-purpose moral IQ score. Nobody needs that particular nonsense with a leaderboard.
The dynamic part also depends on a trained classifier. The authors fine-tune Qwen 2.5 models with LoRA and ultimately use the 3B model as the evaluator for dynamic scoring, after observing that performance improves with size but stagnates past 3B. In the classifier tests, Task 1 in its natural five-class formulation is especially difficult: no classifier exceeds 35% accuracy. The authors therefore use a binary Task 1b version where scores of 3 or above count as correct. This is sensible for making the benchmark operational, but it also narrows what “good abductive reasoning” means during dynamic evaluation.
The evidence says abduction is the bottleneck
The most consistent finding is the asymmetry between abductive and deductive reasoning. Across tested models, Task 1 is harder than Task 2. This holds in the static setting, where models judge existing chains, and it remains visible in the dynamic setting, where models must generate reasoning.
The numbers make the point without needing theatrical interpretation. In static evaluation, Task 1 F1 scores are low across the board. The best Task 1 F1 is Qwen 2.5-72B at 35.14, followed by Qwen 2.5-32B at 34.37. By contrast, Task 2 F1 reaches 70.30 for Gemma 3-27B and 70.06 for Qwen 2.5-32B. The models are much better at checking whether consequences match a precept than at judging whether the precept was well derived from a value.
Dynamic Task 2 is where the strongest models look most comfortable. Gemma 3-12B reaches 98.07, Qwen 2.5-32B reaches 96.70, and Gemma 3-27B reaches 95.17. That suggests some models can generate persuasive deductive evaluations once the structure is in place.
Dynamic Task 1 is less forgiving. Gemma 3-12B does well relative to the field at 80.35, with Gemma 3-27B at 75.39 and Qwen 2.5-32B at 70.13. Those are the better results, but the broader pattern remains: generating or evaluating the value-to-precept step is where models wobble. And in business workflows, wobbling at the framing stage is precisely how a system becomes confidently wrong before anyone can object.
The composite AMA score reflects this mixed picture:
| Model | Composite AMA score | What the result suggests |
|---|---|---|
| Qwen 2.5-32B | 62.19 ± 0.33 | Best overall balance across static and dynamic tests |
| Gemma 3-12B | 61.94 ± 0.47 | Nearly tied with Qwen 2.5-32B; especially strong dynamic Task 1 and Task 2 |
| Gemma 3-27B | 59.68 ± 0.09 | Strong deductive and dynamic performance, but lower composite than Gemma 3-12B |
| Qwen 2.5-72B | 58.67 ± 0.60 | Strong static Task 1, but not the best overall despite larger size |
| Qwen 2.5-14B | 53.71 ± 0.45 | Solid mid-tier result, behind smaller-than-expected leaders |
| Qwen 2.5-3B | 50.15 ± 1.24 | Surprisingly competitive among smaller models |
| Gemma 3-4B | 50.02 ± 0.41 | Similar small-model surprise |
The small-model results are not a minor detail. They suggest that, for this benchmark, model family and training recipe matter at least as much as raw parameter count in practical procurement decisions. Buying the largest model and calling it governance is still, regrettably, not a strategy.
Verification and generation are related, but not interchangeable
The authors test whether static and dynamic performance move together. They report a Spearman rank correlation of $\rho = 0.756$ with $p < 0.005$, indicating a strong positive relationship. In general, models that are good at evaluating reasoning also tend to be good at generating it.
But “in general” is where enterprise systems go to hide their exceptions. The rank analysis shows notable outliers. Phi 4-3.8B ranks sixth on static performance but fourteenth on dynamic performance, a drop of eight ranks. Phi 3-14B drops from third static to eighth dynamic. Phi 3-7B shows a similar pattern. In the other direction, Qwen 2.5-7B performs better dynamically than statically, and Llama 3.1-8B improves from tenth static to sixth dynamic.
The interpretation is straightforward: verification and generation are related but separable. A model may be good at reviewing a reasoning chain it is given, yet weaker at producing one. Another may be more fluent in generation than reliable in critique. For operators, this means one benchmark column is not enough.
That matters in real deployments because these capabilities map to different roles:
| Deployment role | Needed capability | Test it with |
|---|---|---|
| Copilot drafting advice | Dynamic abductive and deductive generation | Can it produce case-specific precepts and apply them? |
| Reviewer of human decisions | Static abductive and deductive evaluation | Can it critique the framing and the application? |
| Governance monitor | Static evaluation plus drift tracking | Can it flag weak or inconsistent reasoning over time? |
| Policy assistant | Dynamic precept derivation under controlled value sets | Can it translate local values without improvising new doctrine? |
A single “ethical reasoning” score blurs these distinctions. The paper’s useful contribution is not that it produces another score. It tells us which sub-skills should not be collapsed.
Scale helps, but it does not give you Socrates in a box
The paper also examines whether larger models perform better. The answer is broadly yes, with qualifications that matter. An OLS regression using log-transformed model size and controlling for model family finds that model scale significantly predicts AMA score, with $R^2 = 0.833$, adjusted $R^2 = 0.782$, $\beta = 4.74$, and $p < 0.001$. In a second model with family interaction terms, fit improves to $R^2 = 0.884$ and adjusted $R^2 = 0.803$, while the main effect of log-size remains positive and significant.
So yes, scale helps. One may now place the ceremonial garland on the GPU invoice.
But the benchmark also shows that the largest model in a family does not necessarily win. Qwen 2.5-32B beats Qwen 2.5-72B on the composite score. Gemma 3-12B beats Gemma 3-27B. The authors hypothesise that this may relate to distillation, where smaller models benefit from higher-quality data generated by larger models. Whether that is the full explanation is less important for operators than the immediate procurement lesson: test the candidate model on the reasoning task, not on its family reputation or parameter count.
There is also a family effect. The regression finds Llama models significantly underperform the Gemma baseline, while Phi and Qwen differences are not statistically significant in that model. The paper does not prove why this happens. It suggests that pretraining and instruction tuning choices matter for AMA-style reasoning. That is exactly the kind of thing an enterprise buyer cannot see in a model card but can expose through task-specific evaluation.
What businesses should do with this
The business relevance of AMAeval is not “use LLMs as moral advisors”. That would be the sort of conclusion one reaches after reading only the noun phrases. The better lesson is to instrument ethically loaded AI workflows around the value-to-precept step.
In practice, that means treating moral, compliance, and policy reasoning as a structured workflow:
- identify the scenario;
- enumerate plausible actions;
- model consequences;
- state the relevant values;
- derive case-specific precepts;
- evaluate candidate actions against those precepts;
- hand the reasoning trace to a human decision-maker.
The model can assist in each step, but the organisation must decide where automation is acceptable and where review is mandatory. The paper’s mechanism suggests that the highest-friction review point should be precept derivation. Once the model has framed the rule, downstream checking may look deceptively rigorous.
A practical governance pattern could look like this:
| Control | What it checks | Why it matters |
|---|---|---|
| Value-set registry | Which abstract values the system may invoke | Prevents the model from inventing a convenient ethical vocabulary |
| Precept review | Whether the value-to-precept derivation is plausible for the case | Catches framing errors before they become recommendations |
| Alternative-precept generation | Whether the same value supports more than one reasonable rule | Reduces single-frame lock-in |
| Stakeholder mapping | Who benefits or loses under each precept | Makes implicit trade-offs visible |
| Static reasoning audit | Whether stored reasoning chains remain credible under review | Supports compliance and post-incident analysis |
| Dynamic regression tests | Whether model updates degrade reasoning generation | Prevents silent drift after model, prompt, or policy changes |
This is particularly relevant in domains where the “right” answer depends on institutional values and local constraints. HR cases involve fairness, care, privacy, consistency, and power. Healthcare triage involves care, autonomy, safety, and resource allocation. Financial advice involves fiduciary duty, suitability, disclosure, and customer vulnerability. Customer escalation involves fairness, loyalty, authority, and commercial discretion. Education involves care, fairness, authority, and student autonomy.
In all of these settings, the dangerous system is not necessarily the one that says something obviously outrageous. The dangerous system is the one that offers a plausible answer after quietly selecting a narrow frame. Polite narrowness is still narrowness.
The paper’s limitations are practical, not cosmetic
AMAeval is useful, but its boundaries should travel with it.
First, the dataset is synthetic. The authors generate scenarios, actions, consequences, precepts, and reasoning chains using OpenAI models, then use human annotation to assess quality. That is a reasonable construction method for a first benchmark, but it means the results are best read as diagnostic evidence under controlled conditions, not as proof of behaviour in messy organisational workflows.
Second, the benchmark uses Moral Foundations Theory as its exemplar value set: authority, care, fairness, loyalty, and sanctity. The framework is designed to accommodate other value systems, but the empirical results are tied to this implementation. A bank, hospital, school, regulator, or multinational employer would need to localise the value set and retest. Otherwise, the system may become very good at reasoning from values that are not the actual values governing the business. A classic compliance innovation: optimising the wrong thing with impressive discipline.
Third, dynamic evaluation relies on a trained classifier. This is understandable because manually judging every generated reasoning chain would be expensive. But a classifier is still a proxy for human judgement. The authors’ own classifier results show that fine-grained Task 1 scoring is difficult, which reinforces rather than weakens the paper’s message: abductive moral reasoning is hard to evaluate, not just hard to generate.
Fourth, the paper evaluates popular open models and deliberately excludes reasoning models. The authors argue that reasoning models often produce stream-of-consciousness traces rather than proper reasoning. That choice keeps the benchmark focused, but it also means the results should not be extended to every current or future model family.
Fifth, the benchmark does not solve moral pluralism. It makes the reasoning process explicit enough to inspect. That is already valuable. But inspection is not consensus. The organisation still has to decide which values count, who gets to define them, how conflicts are resolved, and when human judgement overrides the model. The machine can help expose the trade-off. It cannot make the trade-off disappear. Tragic, really.
The operator’s takeaway: audit the precept, not just the answer
The paper’s most useful idea is that ethical AI systems should be evaluated at the level of reasoning moves. A model that gives the right answer for the wrong reason is not aligned in any operationally satisfying sense. It is lucky, rehearsed, or overfitted to the shape of the question. Luck is not a control framework.
For Cognaptus-style automation, the lesson is clean: if an AI agent is entering sensitive advisory territory, the system needs a visible precept layer. The model should not jump from “case description” to “recommendation”. It should state which abstract values are relevant, derive the case-specific precepts, show how actions and consequences relate to those precepts, and expose enough structure for review.
That does not make the AI a moral authority. It makes it auditable. In enterprise deployments, that is the more useful achievement. Socrates, after all, did not scale by giving everyone a final answer. He scaled by making the reasoning uncomfortable enough to inspect.
Cognaptus: Automate the Present, Incubate the Future.
-
Alessio Galatolo, Luca Alberto Rappuoli, Katie Winkle, and Meriem Beloucif, “Beyond Ethical Alignment: Evaluating LLMs as Artificial Moral Assistants,” arXiv:2508.12754, 2025. ↩︎