TL;DR for operators
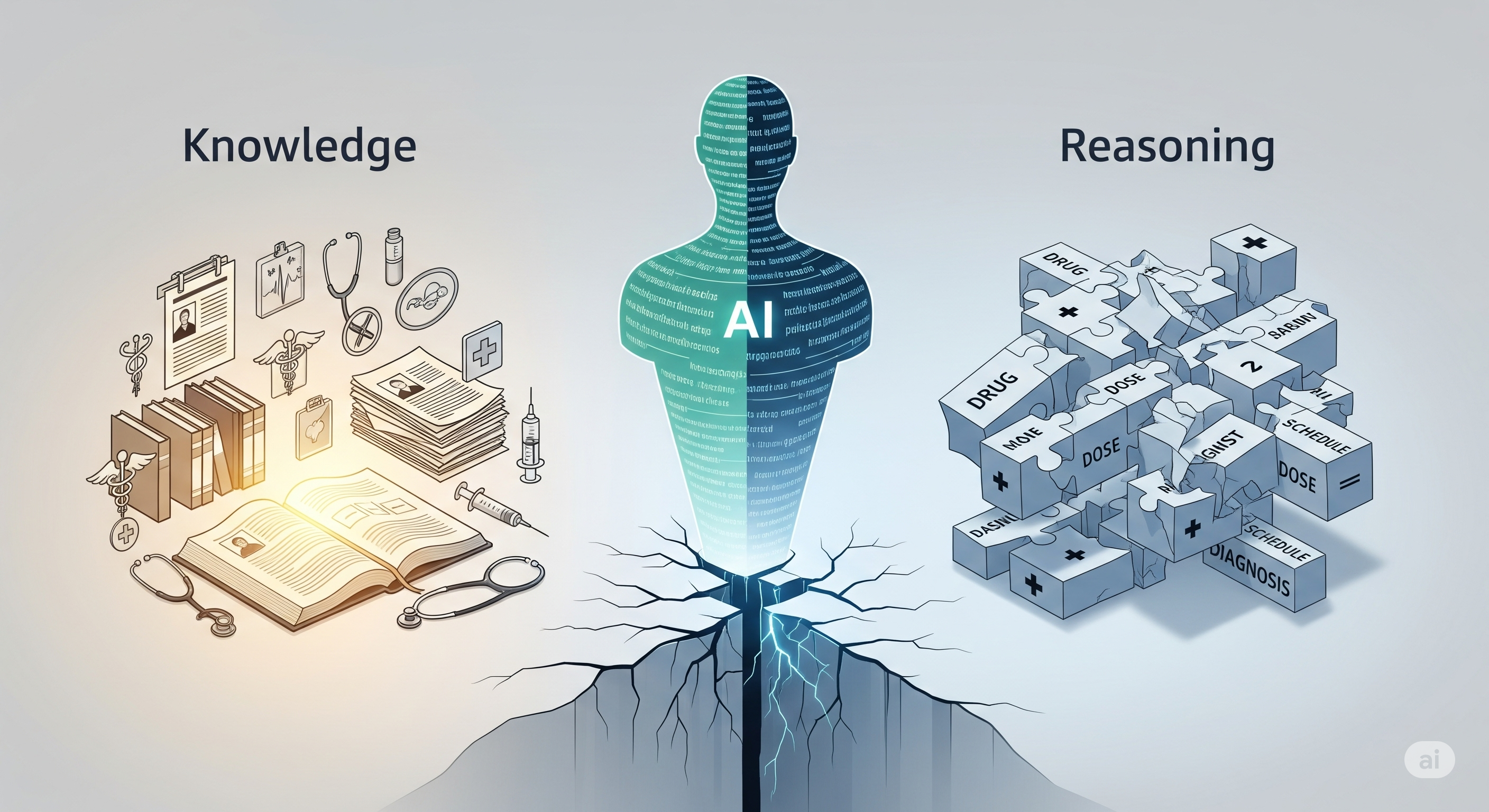
A model that can answer clinical fact-checking questions is not necessarily a model that can reason clinically. That is the inconvenient result of The Knowledge-Reasoning Dissociation: Fundamental Limitations of LLMs in Clinical Natural Language Inference, which introduces CTNLI, a controlled clinical NLI benchmark paired with Ground Knowledge and Meta-Level Reasoning Verification probes.1
The paper evaluates six LLMs across four clinical reasoning families: causal attribution, compositional grounding, epistemic verification, and risk state abstraction. The models perform well on the paired knowledge probes, with mean GKMRV accuracy of 0.918, but poorly on the main reasoning tasks, with mean accuracy of 0.25. Worse, the wrong answers are often consistent rather than random. The models are not merely guessing badly. They are often applying the same shallow heuristic again and again, which is much more operationally annoying.
For buyers, regulators, clinical AI teams, insurers, and any organisation using LLMs in high-stakes review workflows, the practical lesson is straightforward: do not confuse recall with reasoning. A benchmark that asks whether a model knows a contraindication, causal principle, diagnostic criterion, or risk rule is only half a test. The more important half asks whether the model applies that knowledge when the premise is noisy, indirect, compositional, or evidentially conflicted.
Cognaptus’ inference is broader than medicine but not unlimited: the diagnostic pattern matters for any workflow where a model must turn known rules into decisions under context. Compliance review, credit underwriting, claims triage, due diligence, safety assessment, and research interpretation all have similar “knows the rule, misses the case” failure modes. The paper itself does not prove that all LLM reasoning is broken everywhere. It does show that polished factual competence is a very poor substitute for task-paired reasoning diagnostics.
The dashboard is green until the inference starts
The comfortable enterprise story is that domain knowledge is the hard part. Feed the model enough clinical text, instruction-tune it carefully, add chain-of-thought prompting if one is feeling artisanal, and it should learn to reason because the facts are already in there somewhere.
This paper makes that story look a little too convenient.
The authors do not merely ask whether LLMs know medical facts. They create paired tests. First, the model faces a clinical natural language inference task: given a premise and a statement, decide whether the statement is entailed, contradicted, or neutral. Then, for the same underlying item, the model faces a targeted GKMRV probe that isolates the relevant ground knowledge or meta-level reasoning principle. In plain English: “Do you know the rule?” and “Can you use the rule here?” are tested separately.
That separation is the whole point. Without it, a model failure is easy to misdiagnose. Perhaps the model did not know that metformin is contraindicated under severe renal impairment. Perhaps it did not know that single-arm observational outcomes cannot prove treatment efficacy. Perhaps it did not know that a clinician’s assertion can be weaker than objective evidence. Fine. Then the remedy is better retrieval, better medical knowledge, better fine-tuning.
But if the model knows those facts and still fails the inference, the remedy is not “more facts, sprinkled generously.” The issue has moved from knowledge access to reasoning control. That is a different engineering problem, and naturally, a more irritating one.
What CTNLI tests, and why the paired probes matter
CTNLI is built around four reasoning families. Each family targets a different clinical inference primitive, and each item is paired with GKMRV probes that test whether the relevant fact or principle is available to the model.
| Reasoning family | What the main task asks | What the paired GKMRV probe checks | The failure this design can expose |
|---|---|---|---|
| Causal attribution | Does the premise support a causal claim, or only an observed association? | Does the model know why uncontrolled or non-comparative evidence cannot establish causality? | Confusing observed improvement with treatment efficacy |
| Compositional grounding | Does the full drug–dose–condition–patient configuration support the stated clinical outcome? | Does the model know the relevant contraindication or unsafe configuration? | Checking facts in isolation while missing joint constraints |
| Epistemic verification | Should the model accept an asserted diagnosis, or revise it based on stronger evidence? | Does the model know the asserted diagnosis is unsupported or contradicted? | Treating authority as ground truth despite objective evidence |
| Risk state abstraction | Does the premise entail a risk-sensitive management or evaluation judgement? | Does the model know the latent risk, severity principle, or nonzero harm pathway? | Reducing risk to frequency or treating “unlikely” as “ruled out” |
This is not a standard leaderboard dressed in a lab coat. It is a diagnostic instrument. The key comparison is not model A versus model B. The key comparison is model performance on the main reasoning task versus performance on its paired knowledge probe.
That is why the headline result is so sharp. Across six contemporary LLMs, the paper reports mean GKMRV accuracy of 0.918 and mean reasoning-task accuracy of 0.25. The models can often recognise the correct clinical principle when it is presented directly. They then fail to deploy the same principle inside the actual inference setting.
One can almost hear the procurement spreadsheet sigh.
The main result is a gap, not a score
The paper’s most useful contribution is not that the tested models perform badly on a niche clinical benchmark. Bad benchmark scores are plentiful; the industry produces them almost as a renewable resource. The useful contribution is the measured dissociation between ground knowledge and inferential deployment.
The authors evaluate OpenAI o3, GPT-4o, GPT-4o-mini, Gemini 2.5 Pro, DeepSeek R1, and LLaMA 3.2 3B under direct and chain-of-thought prompting. The benchmark uses ten examples per reasoning family, with ten completions per example. This is small, but deliberately controlled.
The pattern is consistent:
| Evidence item | Likely purpose | What it supports | What it does not prove |
|---|---|---|---|
| Main CTNLI task accuracy | Main evidence | Models struggle with structured clinical inference across four reasoning families | That every clinical deployment will fail in the same way |
| Paired GKMRV accuracy | Diagnostic control and main evidence | Many failures are not caused by missing clinical facts | That the model has a full internal clinical ontology |
| Consistency across completions | Main evidence against pure randomness | Errors are often systematic and repeatable | That the same heuristic explains every wrong answer |
| Direct vs chain-of-thought comparison | Robustness and sensitivity test | CoT adds little overall and does not reliably repair the failures | That no prompting strategy could ever help |
| Model-choice appendix | Robustness and comparison across model families | Bigger or more advanced models do not dominate every reasoning type | That smaller models are generally safer or better |
| Limitations appendix | Boundary setting | Results are indicative, not a final universal measurement | That the benchmark is irrelevant because it is small |
The consistency result matters. Across reasoning tasks, the paper reports high completion consistency: 0.84 for causal attribution, 0.87 for compositional grounding, 0.90 for epistemic verification, and 0.85 for risk abstraction. In other words, many wrong answers are not unstable sampling accidents. The model often reaches the same wrong label repeatedly.
That is commercially worse than noise. Noise can sometimes be averaged, filtered, or escalated. A systematic shortcut looks reliable until someone asks what it is reliably doing.
Causal attribution: the model knows comparison matters, then forgets to compare
The causal attribution task tests whether models distinguish observed outcomes from causal claims. A premise might report that a percentage of patients improved after receiving a treatment. The hypothesis then claims that the treatment caused or accelerated the improvement.
The correct reasoning requires a comparator or counterfactual. Observing improvement after treatment does not by itself show that the treatment caused the improvement. The model needs to separate:
from an intervention-style claim about what would happen under treatment versus no treatment:
The paper reports that causal attribution is the strongest of the four main tasks, but still weak: average main-task accuracy is 0.49. GKMRV performance, by contrast, is near ceiling, with all models above 0.95 except LLaMA 3.2 in one setting.
That gap has a clean interpretation. The models often know the principle that single-arm evidence cannot prove causality. When the probe asks directly whether the absence of a comparison group undermines a causal claim, they usually answer correctly. But inside the NLI task, the visible numerical outcome becomes seductive. A percentage improved; a metric moved; therefore the treatment probably worked. That is not causal reasoning. That is a spreadsheet with bedside manner.
The business lesson is not limited to medicine. Many enterprise workflows involve causal language attached to observational data: “this campaign improved retention,” “this control reduced fraud,” “this intervention lowered churn.” If an LLM is allowed to summarise or validate such claims, testing factual recall is not enough. It must be tested on whether it rejects causal overreach when the counterfactual is missing.
Compositional grounding: the worst failure is the most practical one
Compositional grounding is where the benchmark becomes especially uncomfortable. The average main-task accuracy is only 0.04, while GKMRV accuracy on drug–dose–condition validity is high, around 0.96 aside from weaker LLaMA results. That is not a small stumble. That is the reasoning equivalent of confidently walking through the wrong door because the sign contained familiar words.
The task is simple in concept but hard in structure. A treatment may be appropriate in one dose, unsafe in another, suitable for one condition, contraindicated for another, and dependent on patient-specific factors such as renal function. No single token decides the answer. The model must evaluate a tuple: drug, dose, schedule, diagnosis, patient condition, and expected outcome.
The paper’s representative example uses metformin in a patient with severe renal impairment. The GKMRV probe asks whether the dosage is contraindicated because of lactic acidosis risk. Models can identify that principle. But the main entailment task asks whether the treatment configuration supports expected benefits. There, models often drift into partial associations: metformin helps glycaemic control; kidney protection is discussed in diabetes contexts; the hypothesis sounds medically plausible; perhaps neutral, perhaps entailed.
The missing operation is joint constraint checking. The model is not merely retrieving “metformin” and “diabetes” and “kidney.” It must bind them into a clinically valid configuration. If the full configuration violates a safety constraint, the hypothesis should be contradicted even if several individual phrases are familiar and positive.
For operators, this is the paper’s most directly useful warning. Many business decisions are compositional in exactly this way. A loan might be acceptable under one collateral structure but not another. A contract clause might be fine under one jurisdiction but risky under a particular counterparty and liability cap. A clinical recommendation might be fine for the average patient and unsafe for this patient. The model’s individual facts can all be correct while the final judgement is wrong because the constraint lives in the combination.
That is where “the model knows the facts” becomes a dangerously low bar.
Epistemic verification: authority is not evidence, despite what meetings suggest
The epistemic verification task asks models to reason about asserted claims versus evidential support. In clinical text, not every sentence should be treated as equally true. A physician may assert a diagnosis, a lab test may support another, symptoms may contradict both, and the model must resolve the conflict.
The paper reports average epistemic verification accuracy of 0.24, with GKMRV again near ceiling except for LLaMA 3.2. The model often knows the diagnostic pattern when asked directly. Yet in the main task, it may defer to an asserted clinician interpretation even when objective evidence supports a different conclusion.
This is not a niche clinical quirk. It is a general failure of evidential hierarchy. In many enterprise contexts, a source’s assertion is not the same as a fact. A manager’s status update is not the same as audit evidence. A vendor’s claim is not the same as a penetration test. A borrower’s explanation is not the same as bank statements. A board deck is not the same as underlying cash flow. Shocking, I know.
The model must therefore do more than parse who said what. It must decide which assertions are defeasible, which evidence is stronger, and when a claim should be rejected or treated as unresolved. The paper’s result suggests that current LLMs can be brittle here. They may recognise the medical rule in a direct probe, but when the same rule competes with an authority cue inside a premise, the cue can win.
This is why “source-aware summarisation” is not enough for high-stakes workflows. The model must be evidence-aware, conflict-aware, and willing to say: the stated conclusion does not follow.
Risk abstraction: frequency is not risk, and “unlikely” is not “impossible”
Risk state abstraction tests whether models reason over latent harm, probability, and severity. The paper uses two kinds of cases. Some present an explicit trade-off between frequent minor events and rarer severe events. Others require recognising a serious but unconfirmed condition that remains possible and therefore warrants evaluation.
The models perform poorly. All model–prompt pairs score below 0.27 on risk abstraction. GKMRV performance is much higher, with an average of 0.86. Again, the models can often identify the relevant risk principle when it is stated directly, but they fail to activate or integrate it in the main task.
Two failures stand out.
First, models conflate “unlikely” with “ruled out.” A condition may be less likely given the symptoms, but without the necessary examination or imaging it is not eliminated. Clinically, that distinction matters because risk is not only probability. It is probability weighted by harm. A low-probability catastrophic outcome can dominate a high-probability minor inconvenience.
Second, models reduce adverse-event risk to event frequency. If injection-site pain occurs more often than myocardial infarction, the model may treat injection-site pain as the “highest risk.” That is the wrong abstraction. Risk is closer to:
The exact clinical decision function is richer than that toy expression, but the point is enough. Frequency alone is not risk. Severity matters. Downstream consequences matter. The cost of missing the event matters.
For business users, this is perhaps the most transferable lesson in the paper. Compliance alerts, fraud signals, cyber vulnerabilities, safety incidents, and credit exceptions all have frequency–severity trade-offs. A model that ranks the most common issue as the most important issue will look productive while quietly misallocating attention. Excellent. We have automated the junior mistake.
Chain-of-thought makes the answer longer, not necessarily better
The appendix tests prompt choice. Direct prompting and chain-of-thought prompting are compared across the four reasoning families and six models. CoT produces a small overall mean accuracy gain: 0.226 versus 0.196, an absolute improvement of 0.030. The effect is heterogeneous. GPT-4o shows no aggregate change; GPT-4o-mini and LLaMA 3.2 benefit more; o3 slightly regresses.
This is best read as a robustness and sensitivity test, not as a second thesis. The point is not “CoT never helps.” The point is that asking the model to explain itself step by step does not reliably repair the structural failure. In qualitative inspection, the paper reports that CoT often verbalises the shortcut rather than replacing it. The model may produce a more elaborate explanation for why frequency equals risk, or why an asserted diagnosis overrides lab evidence. A wrong staircase is still a staircase.
For deployment teams, this matters because chain-of-thought-style prompting is often used as cheap assurance theatre. The output looks more thoughtful, the intermediate reasoning gives humans something to inspect, and the system feels less like autocomplete wearing a tie. But if the rationale is post hoc or heuristic-driven, verbosity becomes a false comfort.
The better control is not “make it explain more.” The better control is “test whether explanations change when the inference structure changes.” If the model can state the rule but fails when the same rule must govern a decision, the explanation layer is not the control surface.
Model choice helps, but not in the comforting leaderboard way
The model-choice appendix is another useful operational detail. Model identity explains more variance than prompt format, but the ranking is not clean. Gemini 2.5 and o3 do well on causal attribution relative to other models, yet collapse on compositional grounding. DeepSeek R1 is strongest on compositional grounding, though still weak in absolute terms. LLaMA 3.2, despite lower ground-knowledge scores, is comparatively strong on some risk and epistemic settings.
The conclusion is not that smaller models are secretly better. Please do not turn this into a procurement slogan; the world has suffered enough. The conclusion is that “better model” is not a single scalar when the task decomposes into causal, compositional, epistemic, and probabilistic primitives.
This is important for evaluation design. A single “reasoning score” can hide precisely the difference that matters. A model that performs well on causal attribution may still fail at joint constraint checking. A model that retrieves clinical facts well may still mishandle evidential conflict. A model that writes beautiful explanations may still reduce risk to frequency.
Enterprise evaluation should therefore be task-primitive-specific. The practical question is not “Which model reasons best?” It is: which reasoning primitive does this workflow require, and has the model been tested against that primitive under realistic context pressure?
What the paper directly shows versus what businesses should infer
The paper directly shows a controlled dissociation in a clinical NLI benchmark. Six tested LLMs frequently succeed on paired GKMRV probes while failing the main reasoning tasks. The errors are often internally consistent, and CoT prompting provides only limited improvement. The failures cluster around identifiable heuristic substitutions: association for causation, pairwise facts for joint constraints, authority for evidence, and frequency for risk.
Cognaptus infers a broader evaluation principle: high-stakes AI systems should be tested with paired diagnostics that separate fact possession from inferential deployment. The operational question is not only whether the model knows a rule, but whether the rule governs behaviour when it is not explicitly foregrounded.
That principle applies beyond clinical NLI. Consider:
| Workflow | Factual test that is insufficient | Paired reasoning diagnostic that matters |
|---|---|---|
| Clinical triage | Does the model know contraindications? | Does it apply contraindications inside patient-specific treatment configurations? |
| Compliance review | Does the model know the policy rule? | Does it identify violations when the rule conflicts with surface-level business justification? |
| Credit underwriting | Does the model know risk factors? | Does it combine borrower, collateral, cash flow, and covenant constraints correctly? |
| Cybersecurity | Does the model know vulnerability severity categories? | Does it prioritise low-frequency, high-impact exploit paths over common noise? |
| Due diligence | Does the model know accounting red flags? | Does it resolve contradictions between management claims and documentary evidence? |
What remains uncertain is scale and generality. CTNLI uses a small set of template-generated items: ten per reasoning family. The strict three-way NLI labels may under-represent partial reasoning success. Different prompting strategies, tool-augmented pipelines, verifiers, retrieval systems, or future model versions could shift results. The authors are clear that the benchmark is indicative rather than definitive.
That boundary should be respected. It should not be used as a universal indictment of all LLM-assisted clinical work. It should be used as a warning that factual competence is not the same thing as structured inference.
The evaluation pattern is the product
The most commercially useful artefact in this paper may not be CTNLI itself. It is the testing pattern.
A well-designed high-stakes evaluation should include at least three layers:
-
Ground knowledge probe Can the model identify the relevant fact, rule, constraint, or principle when asked directly?
-
Embedded reasoning task Can the model apply that same rule when it is embedded in a realistic premise with distracting, conflicting, or incomplete context?
-
Consistency and perturbation test Does the model’s answer remain stable when irrelevant surface features change, and does it change when the actual inference structure changes?
Most organisations stop at layer one, then wonder why the system behaves oddly in production. Layer one is easy to measure and easy to pass. Layer two is where the useful failures appear. Layer three tells you whether the model is reasoning over structure or surfing on cues.
This is also where the paper’s evidence-first framing matters. The headline is not “LLMs are bad at medicine.” That is too broad and too easy. The headline is more specific and more operational: models may possess the facts required for a decision yet fail to activate, bind, weigh, or simulate those facts when the decision structure demands it.
That is the evaluation gap buyers should care about.
Boundaries: small benchmark, large diagnostic signal
The paper’s limitations are real and should not be airbrushed into a grand theory of everything.
CTNLI is small: four reasoning families, ten instantiated examples per family. The template-based construction improves control but narrows breadth. The three-way NLI labelling scheme is strict, while clinical reasoning often admits graded judgements such as plausible but unsafe, likely but unproven, or urgent despite uncertainty. Only direct and CoT prompting are tested, with ten stochastic completions per example. Tool use, self-consistency decoding, verifier-guided prompting, and retrieval-augmented systems are not exhaustively explored. The model set is diverse but not comprehensive, and proprietary systems remain opaque.
These limitations affect interpretation. They mean the paper should not be treated as a deployment benchmark for a specific hospital, insurer, or regulator. A production system would need domain-specific validation, clinical governance, human oversight, monitoring, and regulatory review.
But limitations do not erase the central signal. The paired-probe design shows a failure pattern that many ordinary evaluations miss. If a model answers the GKMRV probe correctly and fails the corresponding inference, then “more medical knowledge” is not the obvious fix. The fault lies in when and how knowledge is used.
That is exactly the kind of failure high-stakes operators need to detect before the model is placed anywhere near consequential decisions.
Conclusion: knowing the rule is table stakes; applying it is the job
This paper is useful because it refuses to let factual recall cosplay as reasoning. The models tested often know the clinical principles. They can say why a single-arm observation does not prove causality. They can recognise contraindications. They can identify unsupported diagnoses. They can explain that rare severe events may carry higher risk than common minor events.
Then, in the actual inference task, they often miss the plot.
For clinical AI, that is a safety issue. For business AI more broadly, it is an evaluation issue. The systems most likely to be trusted are often the ones that speak fluently, cite the right concepts, and produce consistent outputs. CTNLI shows why that can be a trap: consistency can reflect a stable shortcut, not stable reasoning.
The practical response is not to abandon LLMs in high-stakes workflows. It is to evaluate them like systems that can fail structurally while appearing competent locally. Ask what they know. Then ask whether that knowledge controls their decisions. Then test the gap until it becomes measurable.
Because in the end, the expensive failure is not the model that does not know the fact. It is the model that knows the fact, says the fact, and still makes the wrong call.
Cognaptus: Automate the Present, Incubate the Future.
-
Maël Jullien, Marco Valentino, and André Freitas, “The Knowledge-Reasoning Dissociation: Fundamental Limitations of LLMs in Clinical Natural Language Inference,” arXiv:2508.10777, 2025, https://arxiv.org/abs/2508.10777. ↩︎