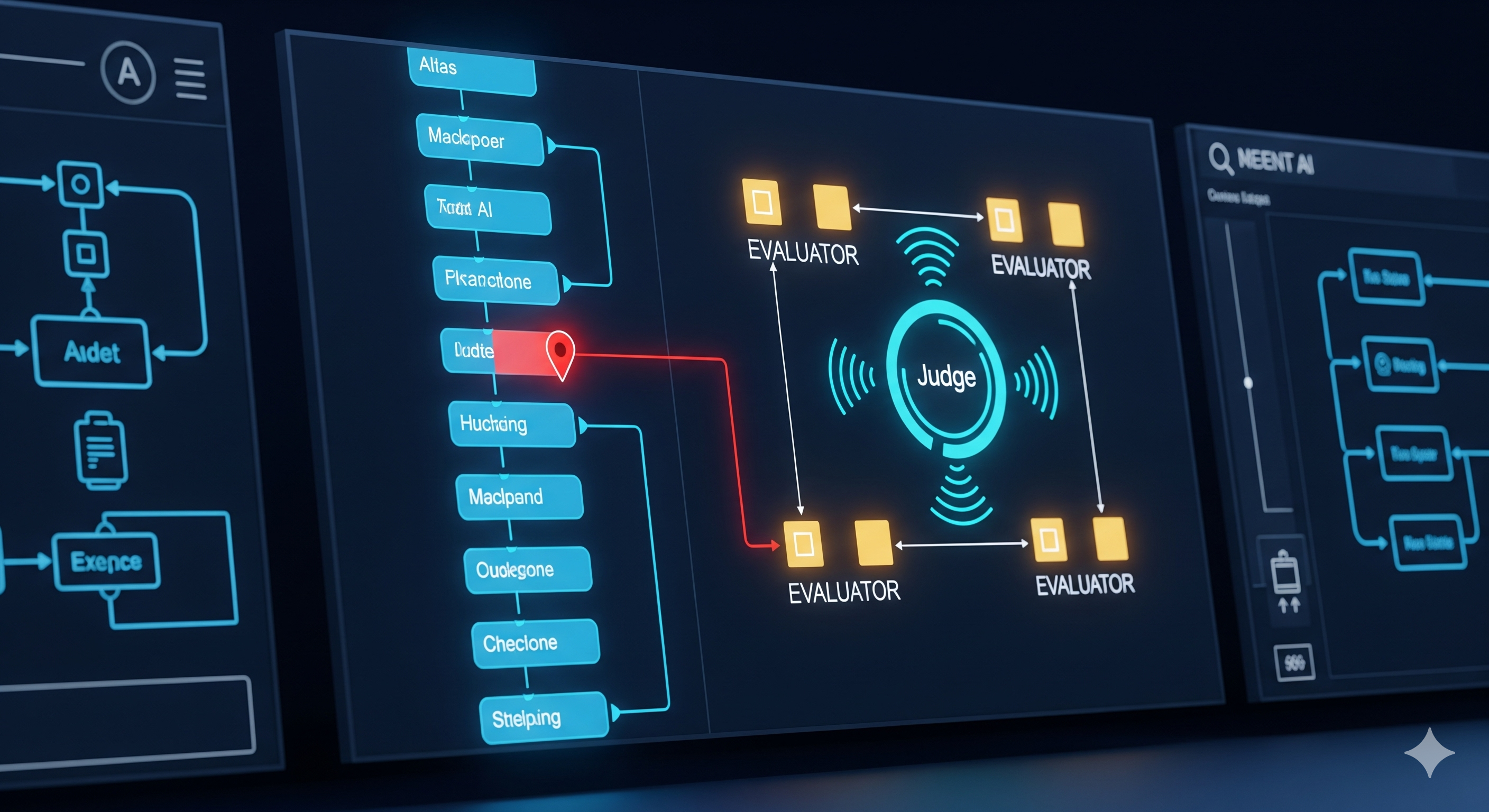
Branching Out of the Middle: How a ‘Tree of Agents’ Fixes Long-Context Blind Spots
Contracts are not polite. They hide the important clause on page 83, define the crucial exception on page 17, and bury the fatal cross-reference in an appendix nobody wanted to read. Annual reports behave similarly. So do medical SOPs, litigation files, policy manuals, technical logs, and most documents produced by institutions that have discovered both Microsoft Word and committees. ...