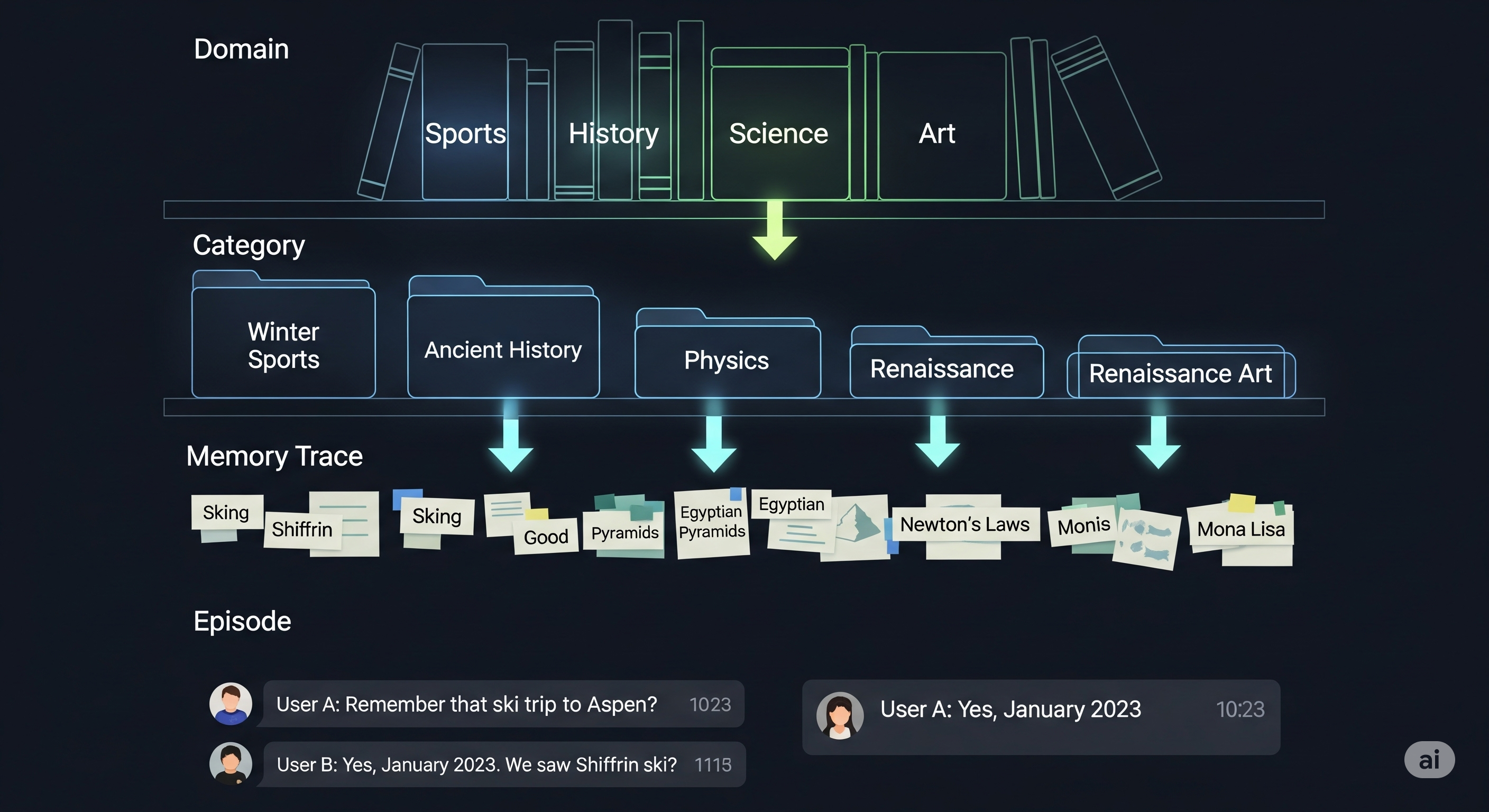
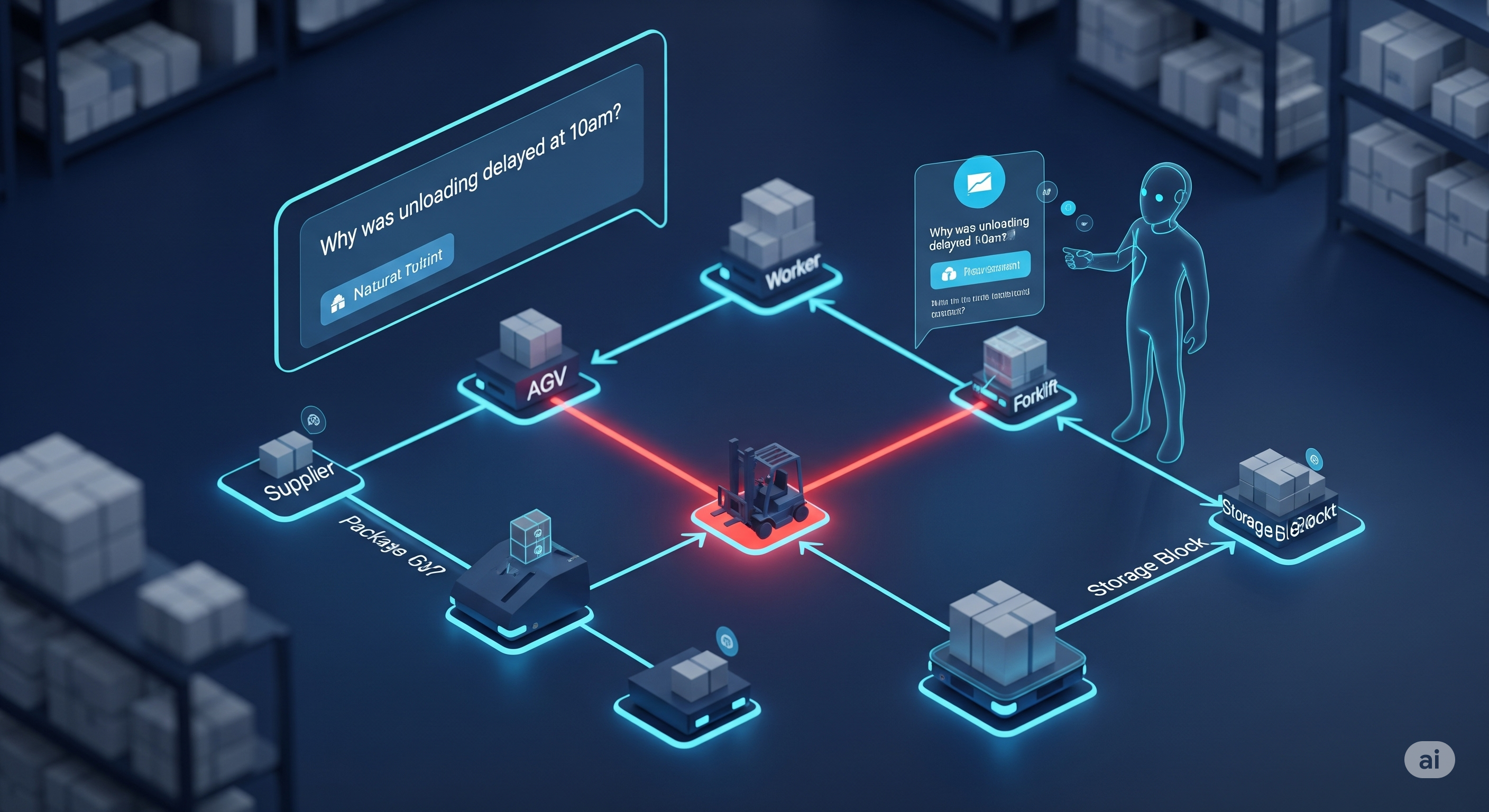
From Autocomplete to Autonomy: How LLM Code Agents are Rewriting the SDLC
TL;DR for operators The useful question is no longer “Can an LLM write code?” It can. Often quite well, occasionally with the confidence of a junior developer who has just discovered Stack Overflow and caffeine. The better question is: which parts of the software development lifecycle can be safely handed to an agentic workflow, and under what controls? ...