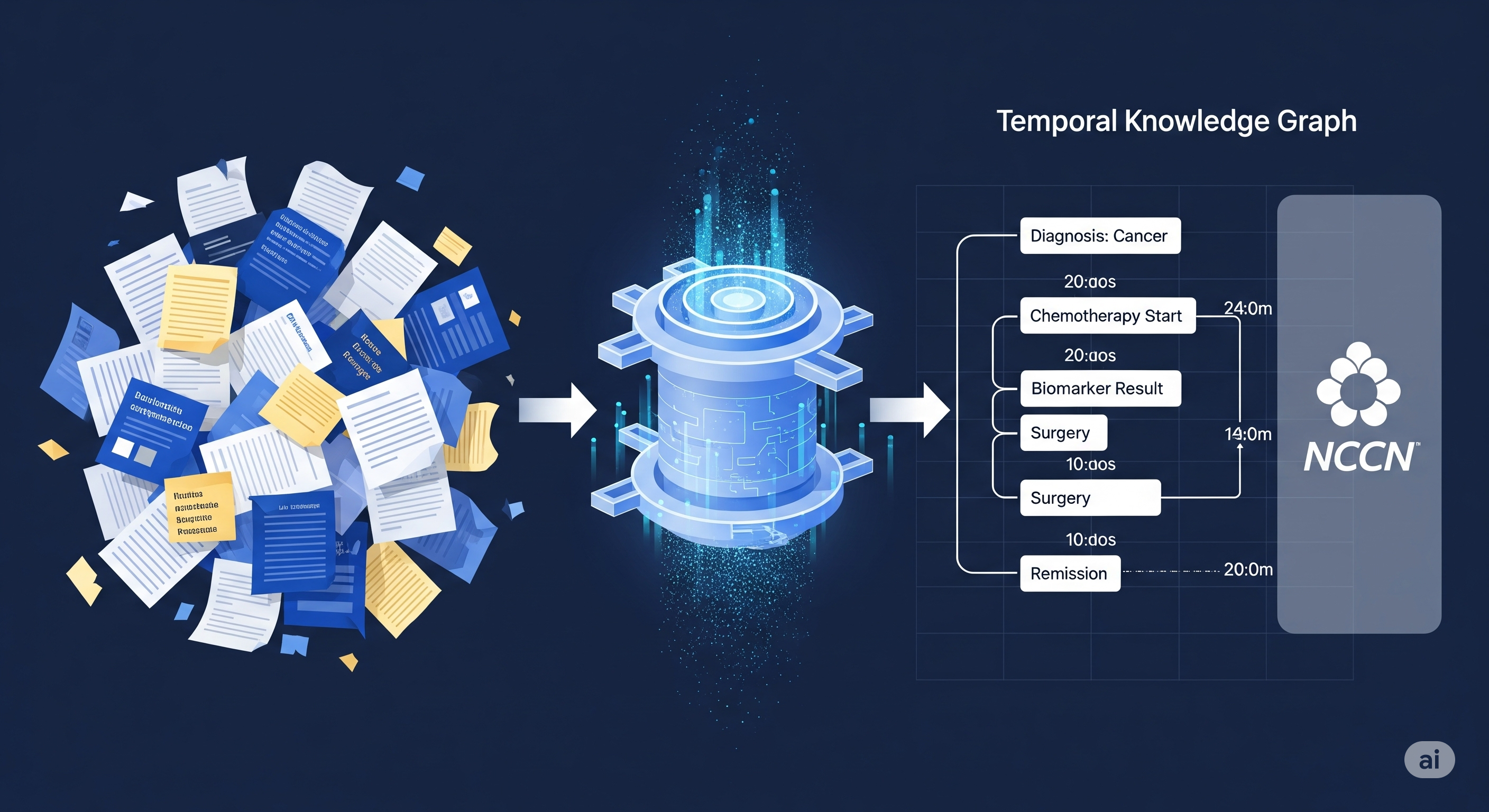
Cite Before You Write: Agentic RAG That Picks Graph vs. Vector on the Fly
TL;DR for operators Most enterprise RAG failures are not generation failures. They are retrieval-routing failures wearing a very convincing blazer. The paper behind this article proposes an open-source agentic hybrid RAG framework for scientific literature review: bibliographic metadata and citation relationships go into a Neo4j knowledge graph; full-text PDF chunks go into a FAISS vector store; an LLM-based agent decides whether a user’s question should be answered through GraphRAG or VectorRAG; a Mistral-based generator produces the final answer; DPO is used to improve grounding; and bootstrap resampling is used to report evaluation uncertainty.1 ...