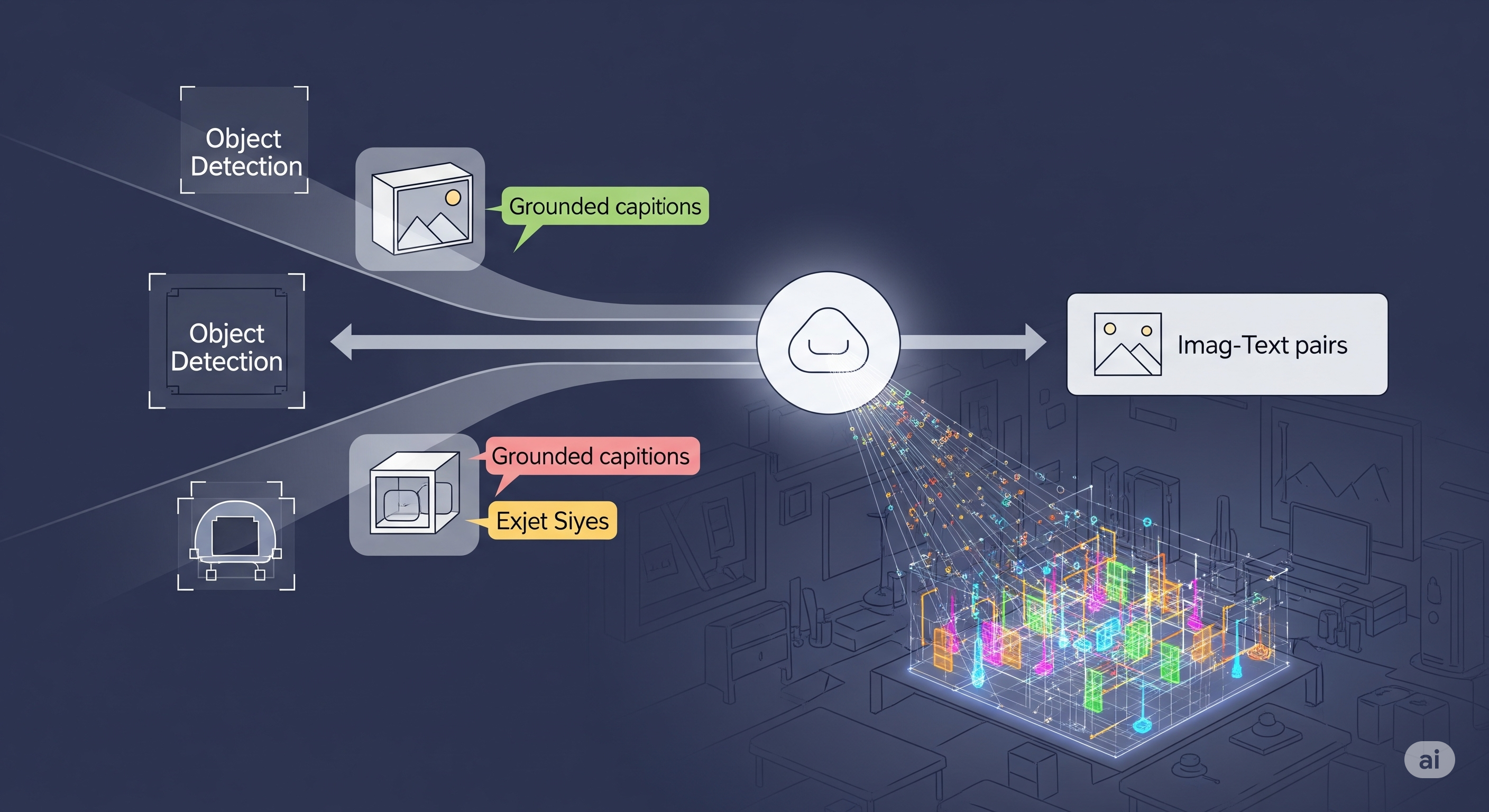
Synthetic Seas: When Artificial Data Trains Real Eyes in Space
TL;DR for operators Offshore infrastructure is hard to monitor because the ocean is large, reporting is uneven, and many installations are either poorly documented or wrapped in the usual fog of commercial and national sensitivity. Sentinel-1 radar imagery helps because it works through clouds and darkness. Deep learning helps because it can scan more scenes than any analyst team pretending it enjoys repetitive labour. ...