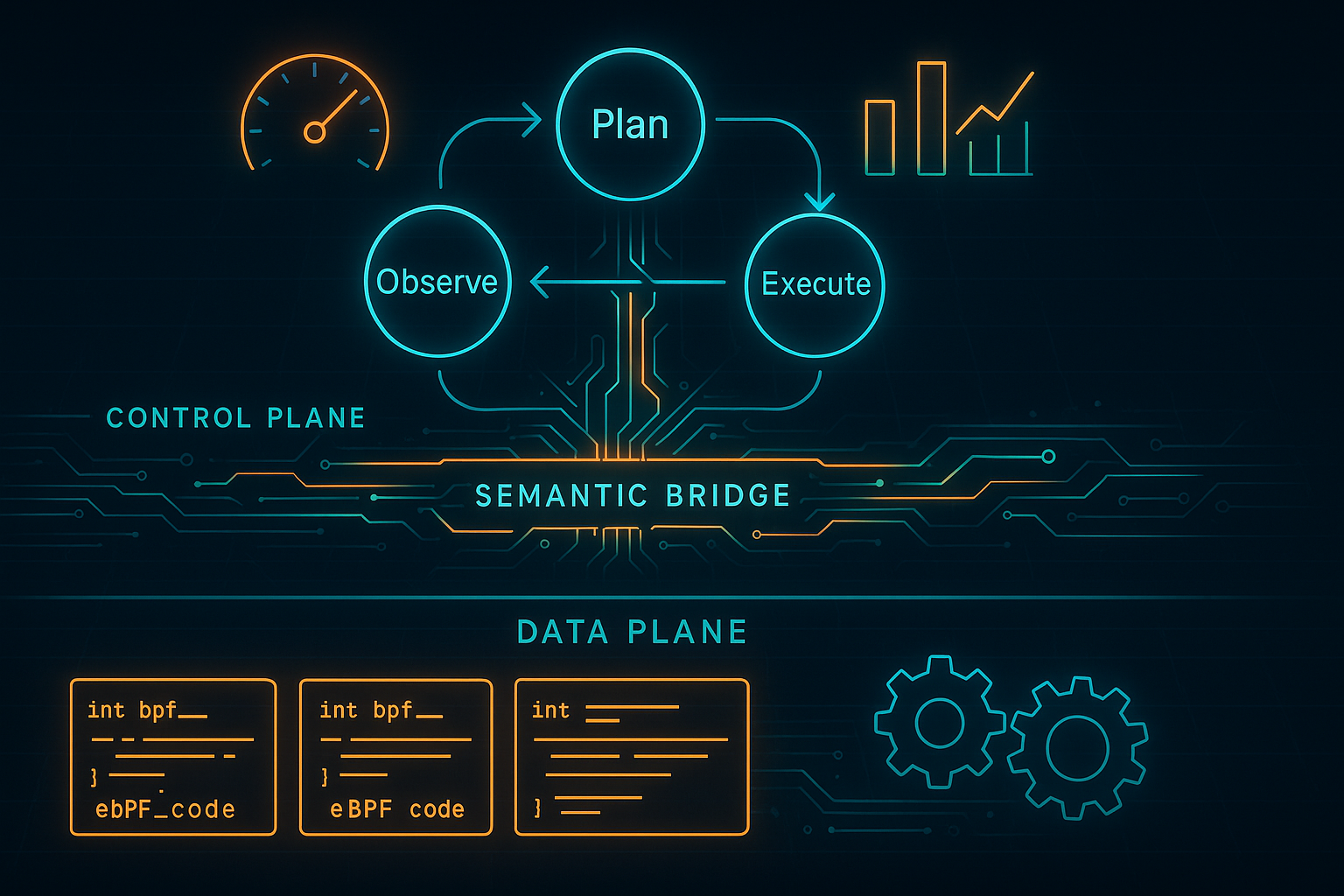
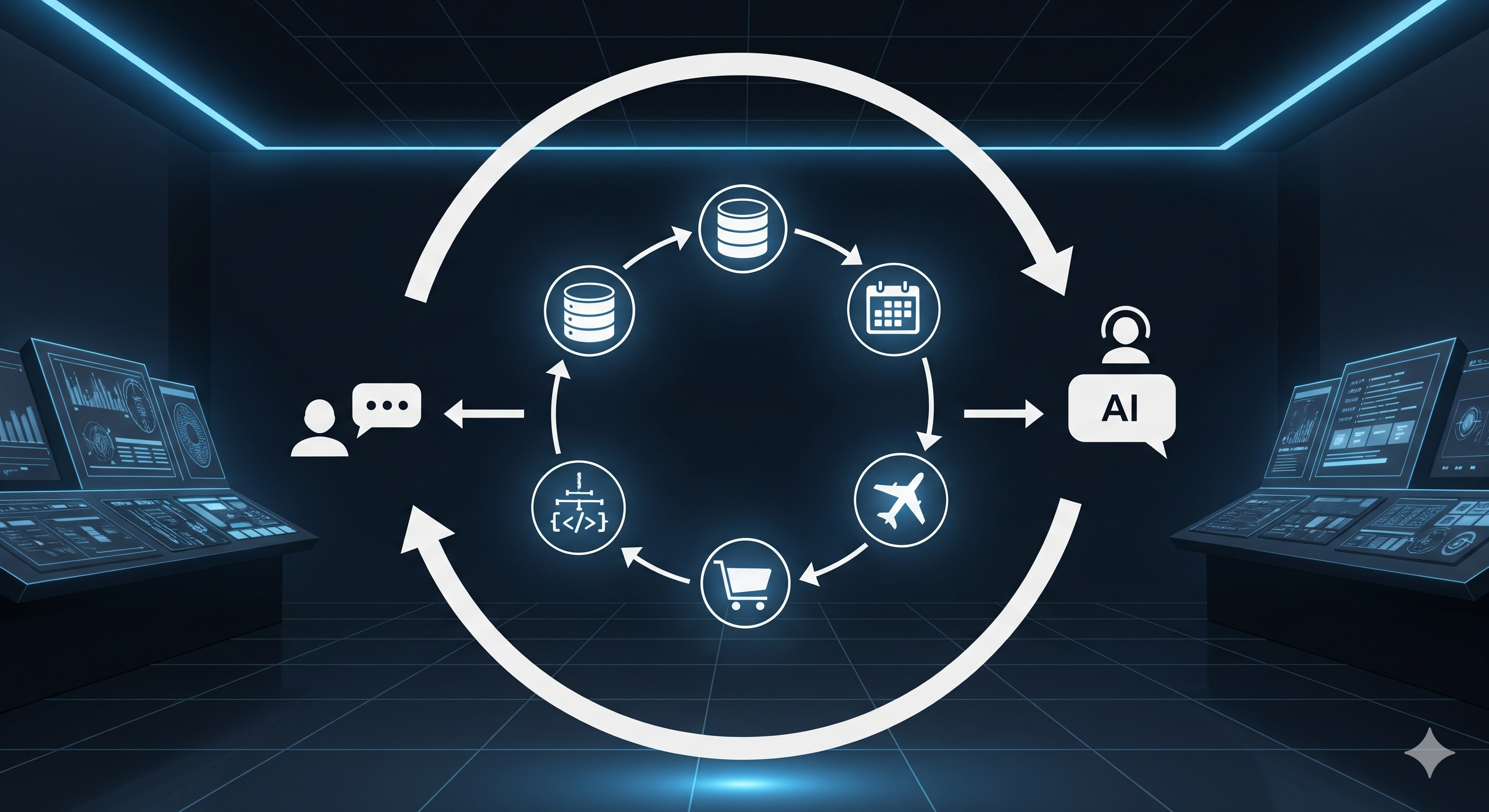
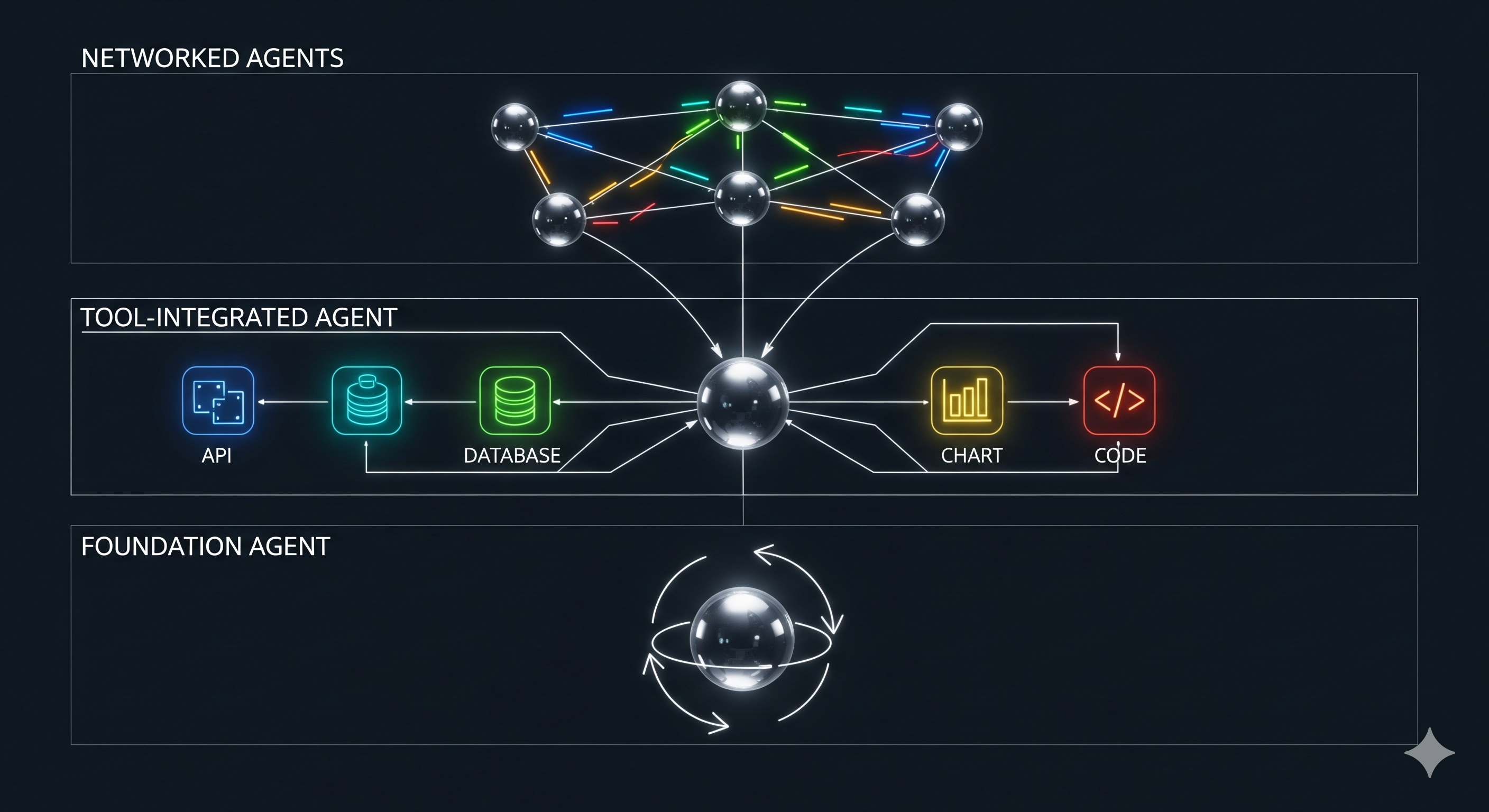
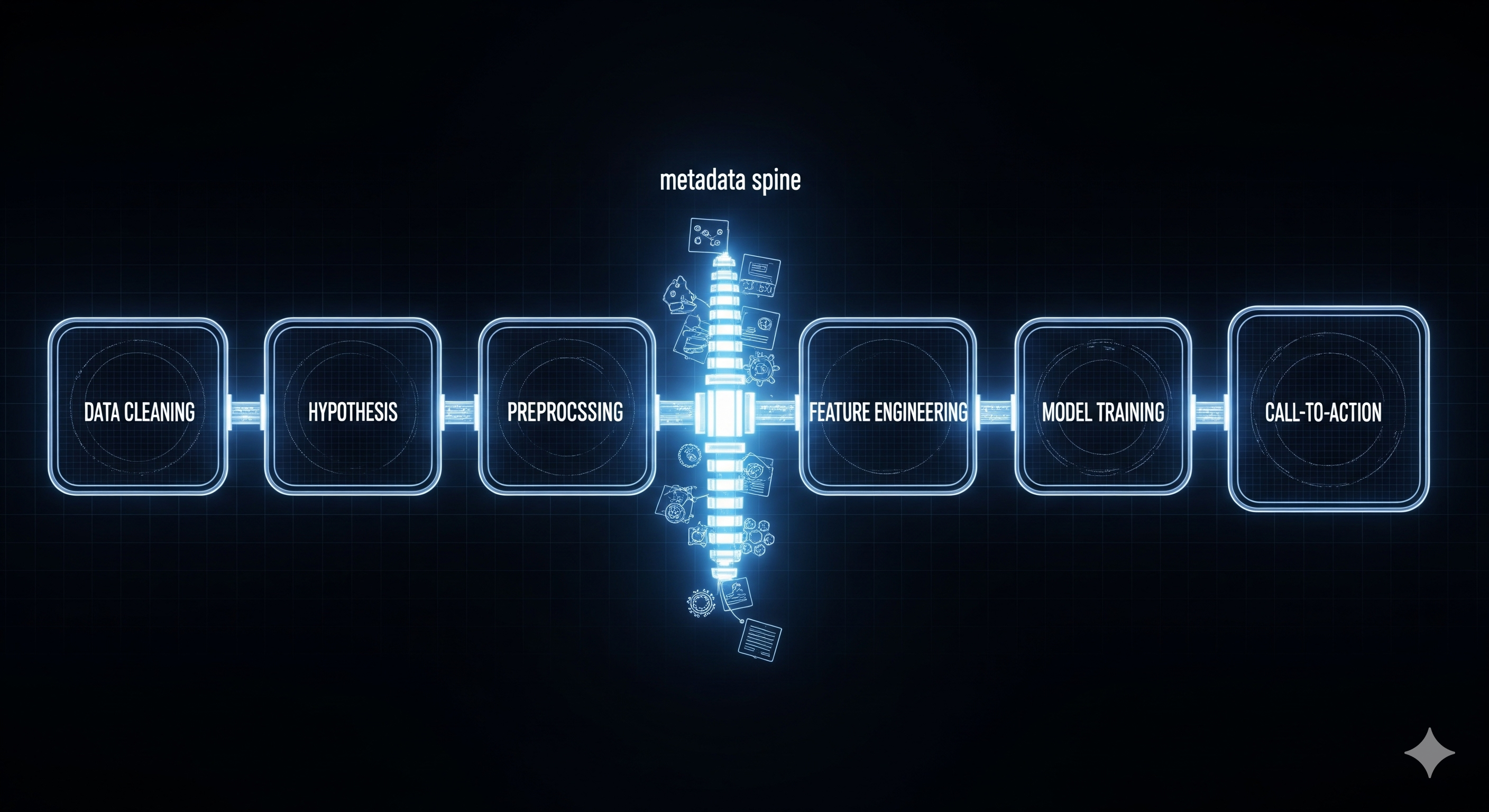
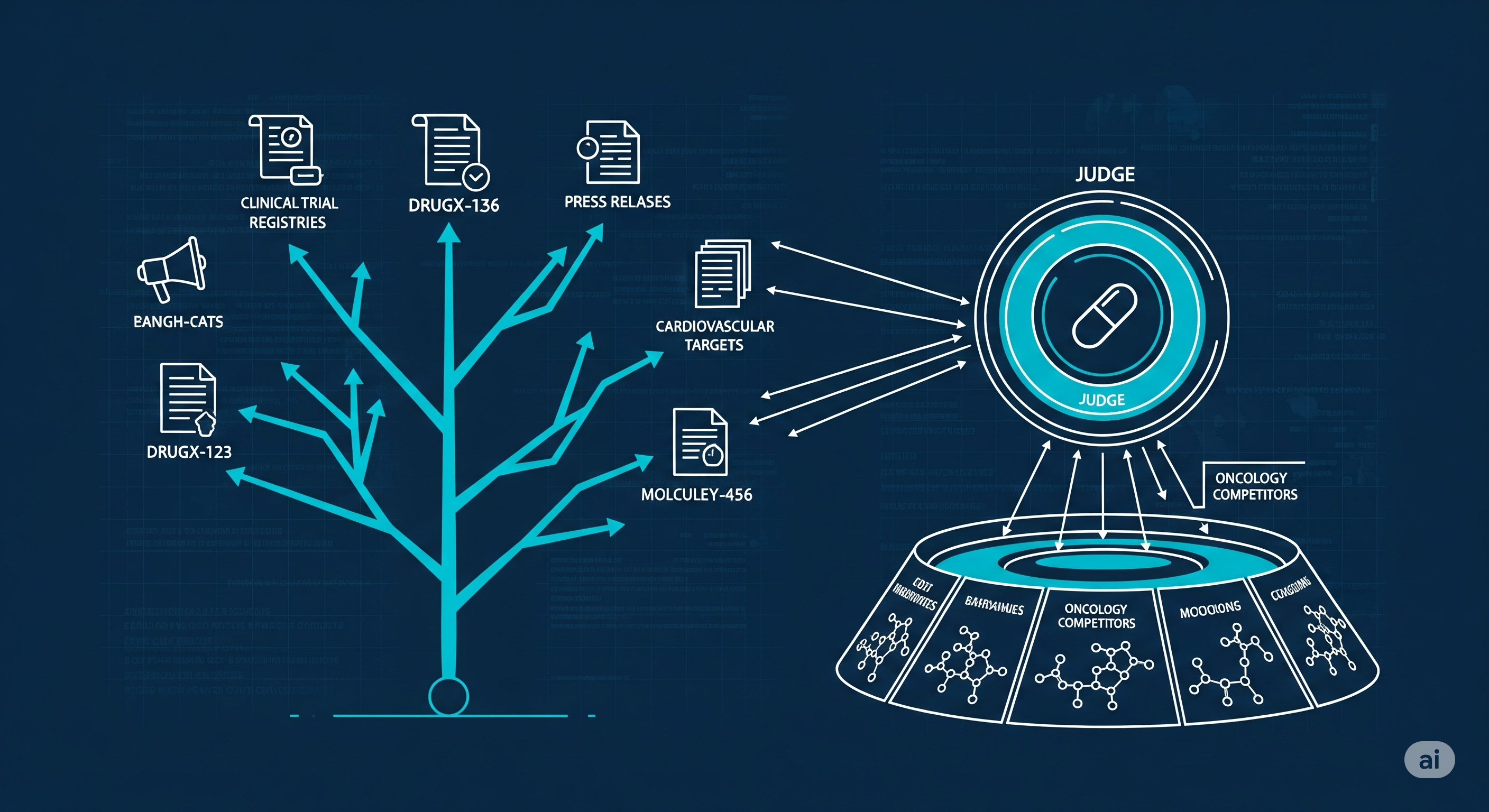
Guard Rails > Horsepower: Why Environment Scaffolding Beats Bigger Models
A demo is cheap. Ask an AI agent to build a web app, watch it spin up a cheerful interface, click a few buttons, and everyone briefly pretends software engineering has been solved. Then production begins. The app boots but stores nothing. The database schema exists but the handler quietly forgets foreign keys. The UI looks plausible until the first state transition. The test suite passes because it checked the page title, not the workflow. Somewhere, a dashboard reports “success.” Somewhere else, a user discovers the thing is an elegant cardboard storefront. ...