A scheduler is where elegant software abstractions go to meet the unpleasant fact that CPUs are finite. Most businesses do not care which runnable task receives a slice of time first. They care that builds finish faster, services stop coughing at the 99th percentile, batch jobs do not drag the whole estate into a swamp, and nobody has to summon a kernel engineer every time a workload changes shape.
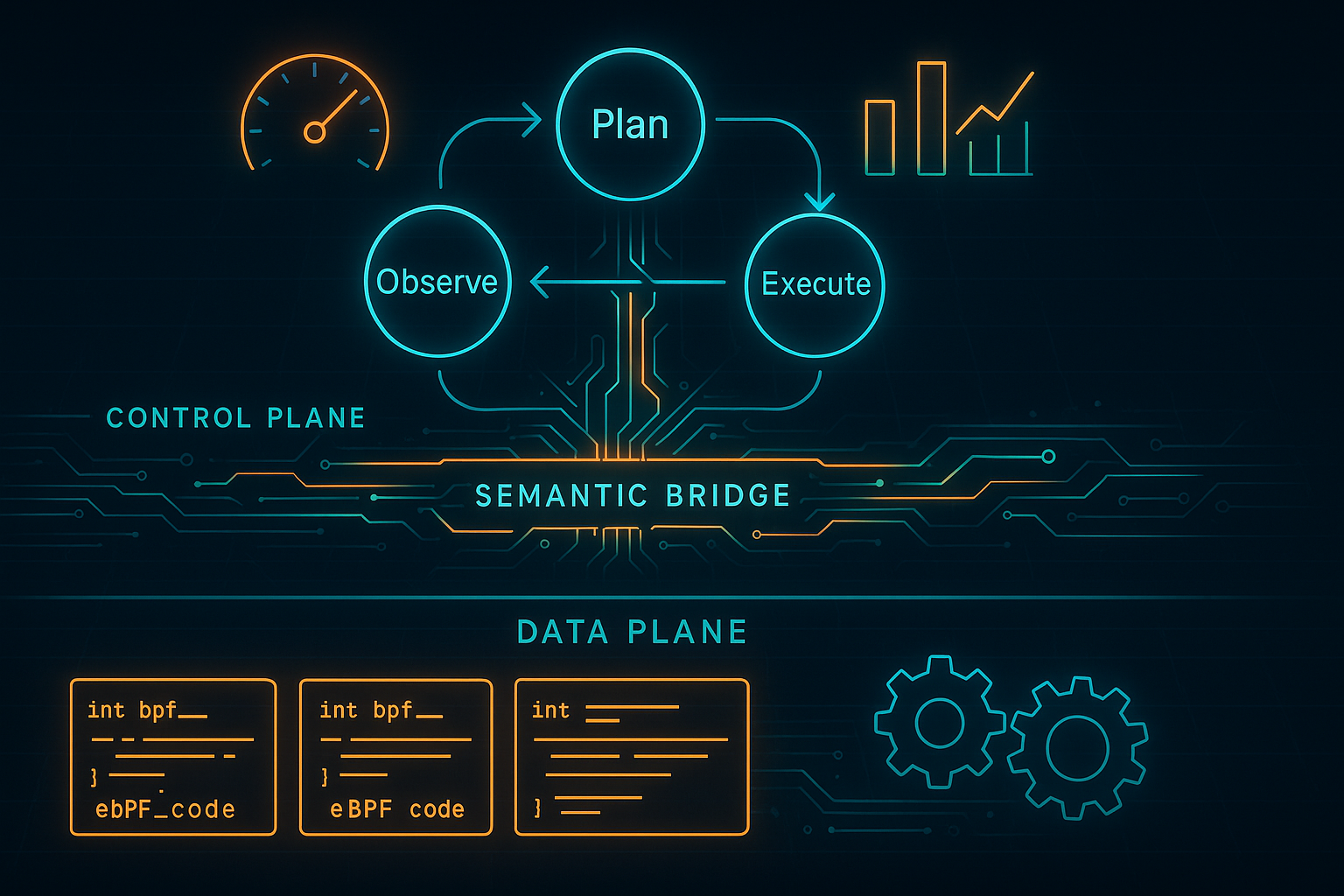
That is the practical doorway into Towards Agentic OS: An LLM Agent Framework for Linux Schedulers, which introduces SchedCP and sched-agent.1 The paper is not really about dropping an LLM into the Linux scheduler and hoping the datacentre becomes enlightened. That would be less “agentic OS” than “root-access performance séance”. The actual move is subtler and more interesting: keep the LLM out of the scheduler hot path, place it in a control plane, and give it structured tools for analysing workloads, retrieving scheduler policies, validating code, and learning from deployment feedback.
The headline results are easy to quote: up to 1.79× improvement on kernel compilation, 2.11× better P99 latency and 1.60× higher throughput on schbench, 20% average latency reduction for a set of batch workloads, and 13× lower generation cost than a naive agentic coding attempt. But the numbers are not the main thesis. The main thesis is architectural: operating systems may become more adaptive not because the kernel becomes sentient, but because the interface around it becomes semantic.
The hard problem is not scheduling; it is knowing what the workload wants
Linux scheduling is already sophisticated. The default scheduler is not asleep at the wheel. The difficulty is that a general-purpose scheduler has limited access to application intent. It observes runnable tasks, priorities, CPU pressure, wakeups, and related system signals. It does not naturally know that a build workload has many short-lived compiler jobs with dependency structure, or that a batch pipeline contains one long-tail task that dominates completion time, or that a service benchmark cares more about tail latency than average throughput.
That is the semantic gap the paper targets.
Traditional learning-based schedulers can improve specific scheduling problems, but they often need humans to define the problem space first: choose features, specify knobs, build an objective function, and train against a known workload class. That is useful, but it is not quite autonomous infrastructure optimisation. The human still performs the semantic work.
LLM agents bring a different capability. They can inspect source code, commands, process names, profiling summaries, and logs, then form a natural-language hypothesis about what the workload is doing. This does not make them magically reliable. It does make them plausible candidates for the “what are we optimising?” layer.
The paper’s key separation is therefore:
| Layer | Responsibility | Failure to avoid |
|---|---|---|
| LLM agent | Infer workload intent and propose scheduling strategy | Mistaking code generation for safe systems operation |
| SchedCP control plane | Provide constrained tools, policy retrieval, validation, and deployment gates | Giving the agent raw root power |
| Linux kernel / sched_ext / eBPF | Execute verified scheduling policy efficiently | Putting LLM inference in the runtime hot path |
This is the crucial point. The LLM is not deciding every scheduling event. It is closer to a performance engineer with a toolbench: analyse, propose, validate, deploy cautiously, observe, revise. Less cyborg kernel. More intern with a badge that only opens the training room.
SchedCP makes the OS legible to agents without handing them the keys
SchedCP is implemented as a Model Context Protocol server. In plain terms, it gives an AI agent a stable interface to observe workloads and act on scheduling policy without having to improvise its own unsafe path through the operating system.
The framework has three core services.
First, the Workload Analysis Engine gives tiered access to system information. The agent can start with cheap summaries such as CPU and memory usage, then request deeper profiling through tools such as perf, top, sandboxed file inspection, application builds, or eBPF probes. This matters because context and token budgets are real. A good agentic system should not read the whole machine every time it sees a new process. It should begin with summaries, then pay for detail only when needed.
Second, the Scheduler Policy Repository stores executable eBPF scheduler programs with metadata: natural-language descriptions, target workloads, historical performance, and reusable primitives. This turns scheduler development from repeated invention into retrieval plus adaptation. For businesses, that is the difference between “every workload needs bespoke kernel wizardry” and “our infrastructure accumulates operational memory”.
Third, the Execution Verifier validates AI-generated code and configurations before deployment. The paper describes a multi-stage pipeline: the kernel’s eBPF verifier for memory safety and termination, scheduler-specific static analysis for issues such as starvation or unfairness, and dynamic validation in a secure micro-VM. Successful validation can produce signed deployment tokens for monitored canary releases, with circuit breakers to revert if performance degrades.
This is where the common misconception needs to be killed cleanly. SchedCP is not “an LLM running the scheduler”. It is an agentic control plane that proposes scheduler changes, while the system remains responsible for verification, deployment discipline, and rollback. That distinction is not cosmetic. It is the entire safety argument.
sched-agent turns optimisation into a loop, not a one-shot code generation trick
On top of SchedCP, the authors build sched-agent, a four-agent framework using Claude Code subagents. The division is simple enough, but it maps well to how performance engineering actually works.
The Observation Agent builds a workload profile. It starts from high-level process and command information, then requests deeper profiling as needed. For kernel compilation, the paper gives an example profile: CPU-intensive parallel compilation with short-lived processes, inter-process dependencies, and a makespan-minimisation goal.
The Planning Agent turns that profile into an optimisation strategy. It can configure an existing scheduler, generate a patch, or compose a new scheduler from primitives in the repository. This hierarchy is sensible. Reuse a known policy before generating fresh kernel-adjacent code. Radical innovation is lovely, but so is not setting the curtains on fire.
The Execution Agent handles development and validation. It synthesises code or configuration, submits it to the verifier, reads failures, and iterates.
The Learning Agent completes the loop. It analyses deployment outcomes, updates performance metrics, records deployment context, and documents antipatterns. This is framed as in-context reinforcement learning: the system improves its choices within the session and enriches the repository without needing model retraining.
That loop is the more durable contribution. Many organisations can get an LLM to write code once. Fewer can give it a safe, repeatable operational cycle where observation, planning, verification, deployment, and feedback are first-class components.
The baseline failure explains why the control plane exists
The authors first test a naive agentic approach: asking Claude Code to “write a FIFO scheduler in eBPF” from an empty folder, with permissions and bash access. Across three attempts, only one succeeds. One attempt produces pseudocode after six minutes. Another produces a scheduler tracer after eight minutes. The successful run takes 33 minutes, 221 API calls, more than 15 iterations, and costs about $6.
This is not an incidental anecdote. It motivates the architecture.
A general-purpose coding agent is poorly shaped for this task. It lacks the right context, does not automatically know which scheduler primitives are safe, may generate code with excessive overhead, and may require privileges that are inappropriate for autonomous operation. Worse, a scheduler bug is not like a misspelled web form label. It can degrade performance, starve tasks, or crash the system.
SchedCP addresses three failures at once:
| Naive agent failure | SchedCP response | Business meaning |
|---|---|---|
| Expensive trial-and-error generation | Repository retrieval and reusable primitives | Lower marginal cost per optimisation |
| Unsafe system access | Verifier, sandbox, signed deployment, canary, rollback | Reduced blast radius |
| Weak workload understanding | Workload Analysis Engine and specialised Observation Agent | Better match between policy and objective |
This is why the paper should not be read as another “LLM writes code” demonstration. The contribution is not that an agent can emit eBPF. The contribution is that the authors wrap code generation in an operating model.
The evaluation is promising, but it is preliminary by design
The experiments answer four questions: whether the system can configure existing schedulers, generate new schedulers for specific workloads, reduce generation cost, and improve through iterative refinement. The setup uses two machines: an 86-core Intel Xeon 6787P system with 758GB RAM running Linux 6.14, and an 8-core Intel Core Ultra 7 258V system with 30GB RAM running Linux 6.13. Agents use Claude Code with Opus 4. Each case is tested three times and averaged.
That is enough for a research prototype signal. It is not enough for a production procurement memo, unless the memo is unusually relaxed about due diligence.
The important results are best read by purpose:
| Experiment | Likely purpose | What it supports | What it does not prove |
|---|---|---|---|
| Kernel compilation with configured schedulers | Main evidence for policy selection and iterative refinement | sched-agent can choose better existing schedulers for a CPU-intensive parallel workload | General improvement across all build systems or hardware |
| schbench latency and throughput | Main evidence plus feedback-driven correction | Initial choices can be wrong, but feedback can steer the agent to a better scheduler | Stable tail-latency benefit under real production traffic |
| Eight long-tail batch workloads | Main evidence for new scheduler synthesis | The agent can identify a long-tail pattern and generate an LJF-style policy | Broad success across arbitrary batch pipelines |
| Claude Opus versus Sonnet classification | Robustness/sensitivity signal | Model capability materially affects workload understanding | That cheaper or smaller models will work reliably |
| Cost reduction from naive generation | Efficiency comparison | Scaffolding sharply reduces generation time and cost | Full lifecycle cost in production operations |
The most instructive result is actually the schbench case. The initial AI configuration chooses scx_bpfland and underperforms the default scheduler: throughput falls from 910 req/s to 741 req/s, and P99 latency worsens from 40.3 ms to 46.1 ms. After three refinement iterations, the system identifies scx_rusty, reaching 1452 req/s and 19.1 ms P99 latency. That is reported as 1.60× higher throughput and 2.11× better P99 latency versus the default.
This matters because it shows the system recovering from a bad first policy. In operational settings, the ability to revise based on measurement is often more valuable than being right on the first attempt. A one-shot optimiser that occasionally guesses well is a demo. A loop that detects underperformance and changes course starts to look like infrastructure.
The kernel compilation result is cleaner. For Linux kernel tinyconfig with make -j 172, the default EEVDF scheduler averages 13.57 seconds. The first SchedCP-selected scheduler, scx_rusty, reaches 8.31 seconds, a 1.63× speedup. After iterative refinement selects scx_layered, the build reaches 7.60 seconds, a 1.79× improvement. A basic RL scheduler in the comparison sits at 13.79 seconds, slightly worse than default.
The batch workload synthesis result tests a different capability. For eight workloads with long-tail distributions, each containing 40 parallel tasks with 39 short tasks and one long task, sched-agent identifies the pattern and implements Longest Job First scheduling. The reported outcome is a 20% average latency reduction. Claude Opus classifies all eight workloads successfully at about $0.15 per analysis, while Claude Sonnet fails. Scheduler synthesis falls to 2.5 minutes and about $0.45 per workload, a 13× efficiency improvement over the naive baseline.
The model-sensitivity point should not be buried. If Opus succeeds and Sonnet fails, the system is not merely a clever wrapper around any cheap model. The control plane helps, but the semantic inference step still depends on model capability. In business terms, the bill may move from scarce kernel experts to high-end model usage. That can still be cheaper. It is not free.
The business value is semantic infrastructure tuning, not autonomous kernel magic
For businesses, the immediate lesson is not “replace platform engineers with agents”. That is the kind of conclusion one reaches by reading only the abstract and possibly a motivational poster.
The stronger interpretation is that infrastructure optimisation can become more semantic. Instead of tuning generic schedulers by hand, a platform team could expose safe system tools to an agent that asks: what kind of workload is this, what objective matters, what scheduler patterns have worked before, and how should we validate the change before it touches production?
That creates a practical pathway:
- \ast\astWorkload interpretation\ast\ast: infer whether the workload is latency-sensitive, throughput-oriented, dependency-heavy, bursty, or long-tail dominated.
- \ast\astPolicy retrieval or synthesis\ast\ast: prefer known scheduler policies when available; generate new eBPF code only when needed.
- \ast\astValidation gatekeeping\ast\ast: use static checks, eBPF verification, micro-VM testing, canaries, and rollback.
- \ast\astOperational memory\ast\ast: record what worked, where it worked, and what should not be repeated.
The ROI path is therefore not just faster builds or lower P99 latency. It is a reduction in the cost of specialising infrastructure. Kernel scheduling expertise is rare. Workload-specific optimisation opportunities are common. Any architecture that narrows that gap without increasing operational risk deserves attention.
This is especially relevant for environments with repeated workload classes: CI/CD build farms, internal analytics platforms, video processing pipelines, edge devices, scientific compute clusters, and latency-sensitive services with predictable profiles. The less repeated the workload, the weaker the repository effect. The less measurable the objective, the harder the feedback loop. Semantic tuning still needs an objective, not vibes wearing a lab coat.
The paper’s evidence supports a prototype, not a platform contract
The limitations are not embarrassing; they are simply important.
The evaluation uses three-run averages, two machines, a limited set of workloads, and one primary agent stack based on Claude Code with Opus 4. The authors also state that future evaluation requires a complete benchmark. That is a fair boundary. Scheduler performance can be highly sensitive to hardware, kernel version, workload shape, contention pattern, and deployment environment.
There is also a broader systems question. Canarying and rollback help contain risk, but scheduler changes can interact with production behaviour in ways micro-VM tests may not fully capture. A policy that helps one workload can harm colocated workloads. A build farm is a friendlier domain than a mixed-tenant production cluster with noisy neighbours and unclear ownership of performance regressions.
The safety architecture is directionally right, but its completeness is not yet proven. The paper describes eBPF verification, scheduler-specific static analysis, dynamic validation, signed deployment tokens, canaries, and circuit breakers. Those are the right nouns. The harder future work is demonstrating that these controls catch the failures that matter under adversarial, messy, and high-load conditions.
The model dependency is another boundary. The batch workload experiment reports that Claude Opus classified all eight workloads while Claude Sonnet failed. That tells us semantic reasoning quality is not interchangeable. Businesses should treat the LLM as part of the system design, not a commodity plug-in that can be swapped casually after procurement asks for a cheaper line item.
The deeper shift: operating systems become tool-using environments for agents
SchedCP is framed around Linux scheduling, but its larger implication is about the shape of agentic infrastructure.
The authors describe SchedCP as analogous to an environment in reinforcement learning: it provides state, actions, and rewards. That analogy is useful. A capable agent needs more than language ability. It needs a world model it can inspect, tools it can use, constraints it cannot bypass, and feedback that tells it whether a change helped.
Many current enterprise AI deployments get this backwards. They start with a powerful model and then bolt on permissions, logs, policies, and rollback after something goes wrong. SchedCP starts from the opposite direction: define the control plane first, then let the agent operate inside it.
That design pattern may generalise beyond scheduling. Databases, caches, queueing systems, autoscalers, CI pipelines, and observability stacks all contain similar semantic gaps. The system can measure symptoms, but it often cannot infer intent. Humans can infer intent, but they are expensive, inconsistent, and usually busy in meetings named “quick sync”. Agentic control planes are an attempt to package that interpretive layer without giving up operational discipline.
The paper’s best contribution is not claiming that LLMs are ready to run operating systems. It shows how to make operating systems agent-readable and agent-actionable while preserving a line between reasoning and execution.
Conclusion: the control plane is the product
SchedCP’s lesson is simple, and slightly inconvenient for anyone hoping for a one-line AI miracle: the intelligence is not only in the model. It is in the interface.
A naive coding agent given root-adjacent scheduling work is expensive, unreliable, and unsafe. A control-plane agent with workload analysis, policy memory, execution verification, canary deployment, and feedback learning becomes much more plausible. The paper’s early results suggest real performance upside: faster kernel builds, better schbench tail latency and throughput, and lower batch workload latency. They also show the limits clearly: small evaluation, model sensitivity, preliminary benchmarks, and production safety still to be proven.
For business readers, the important phrase is not “Agentic OS”. It is “semantic service”. SchedCP turns scheduler tuning into a service that can understand workload intent, search accumulated policy knowledge, propose changes, and validate them before deployment. That is not magic. It is plumbing. Fortunately, infrastructure has always been mostly plumbing. The clever part is deciding where the valves go.
\ast\astCognaptus: Automate the Present, Incubate the Future.\ast\ast
-
Yusheng Zheng, Yanpeng Hu, Wei Zhang, and Andi Quinn, “Towards Agentic OS: An LLM Agent Framework for Linux Schedulers,” arXiv:2509.01245, 2025, https://arxiv.org/abs/2509.01245. ↩︎