TL;DR for operators
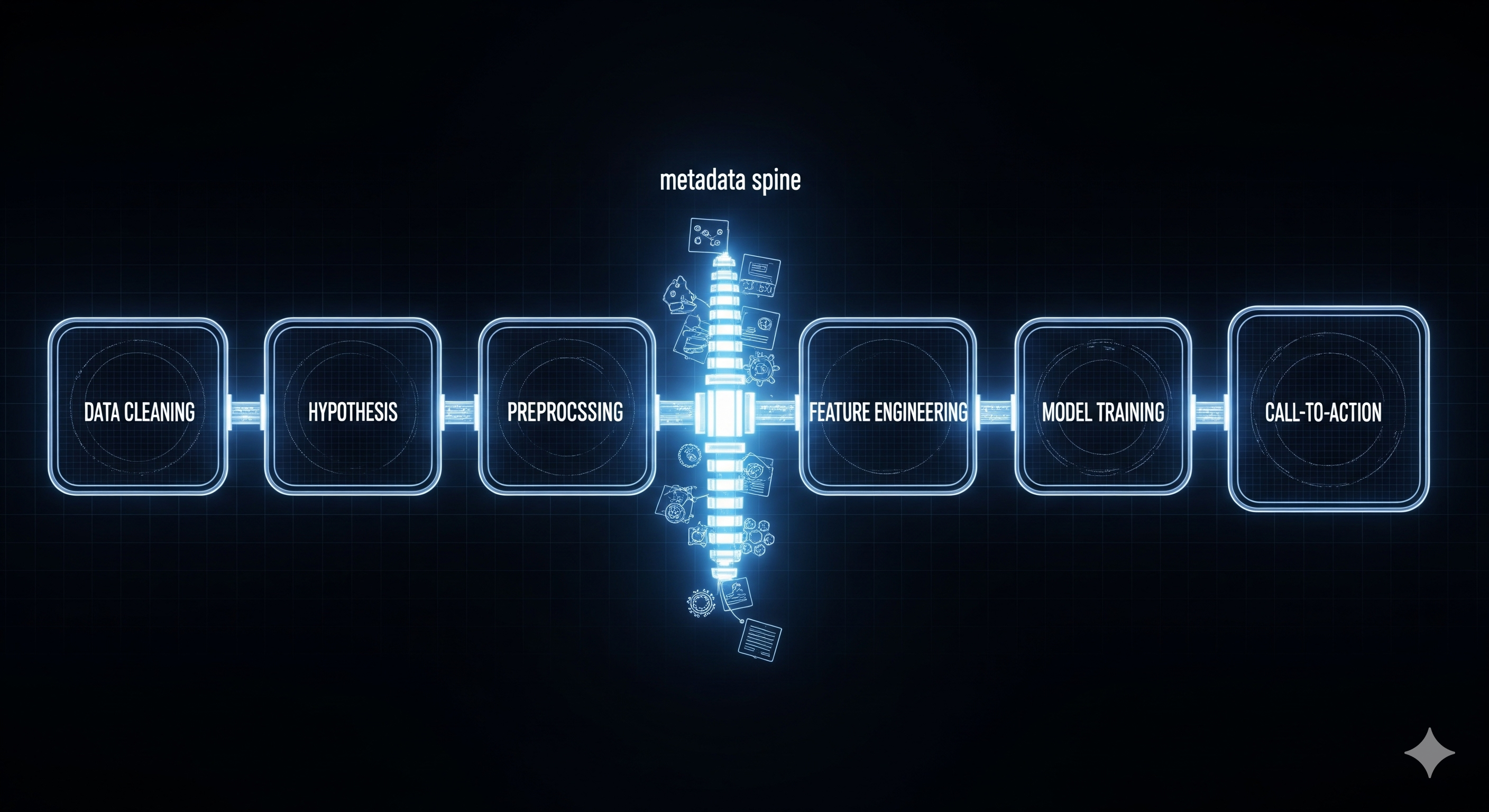
The paper introduces an “AI Data Scientist”: a six-subagent system that moves from raw tabular data to cleaned data, tested hypotheses, engineered features, trained models, and business-facing recommendations.1 The useful idea is not that another agent can write Python. Congratulations, we have met 2025. The useful idea is that hypothesis testing becomes the workflow’s organising rail.
That matters because most analytics work does not fail at the final model alone. It fails in the handoffs: a business question becomes a messy dataset; the dataset becomes a vague notebook; the notebook becomes a model; the model becomes a dashboard; and the dashboard becomes a meeting where someone asks whether the insight is “real.” This system tries to keep those steps connected by passing structured metadata forward at each stage.
The paper’s evidence is promising but not definitive. The system reports gains on four Kaggle-style tabular tasks: customer churn, diamond pricing, smoking-related health risk, and used-car valuation. On the churn task, it reaches 86.69% accuracy and 85.52% F1, about 1.27 and 1.51 percentage points above strong manually written baselines. The ablation table is more important than the headline score: removing the Hypothesis Subagent or Feature Engineering Subagent reduces performance and feature richness, suggesting the mechanism is doing more than decorating AutoML with nicer prose.
For business use, the near-term value is not “replace the data science team.” That slogan should be taken outside and gently retired. The value is cheaper, faster first-pass analysis on repeatable tabular problems where validated patterns can be turned into candidate features and then into human-reviewed recommendations. Think churn diagnosis, credit-risk segmentation, pricing analysis, customer profitability, campaign targeting, and operations triage.
The boundary is sharp. The system tests statistical associations; it does not prove causality. Its benchmarks are public datasets plus a churn case study, not multi-year production evidence in regulated environments. Its outputs still require review for data leakage, data quality, fairness, practical relevance, and whether the recommended action is commercially sane. In other words: useful assistant, not an oracle in a lab coat.
The familiar pain is not modelling; it is handoff decay
A business team rarely begins with a model. It begins with a question that sounds irritatingly simple: which customers are likely to leave, which assets are overpriced, which patients are at higher risk, which vehicles are misvalued, which product bundles actually retain users?
Then the question enters the analytics machine.
First, someone has to clean the data. Then someone has to decide which relationships are worth testing. Then someone transforms variables into model-ready form. Then someone engineers features, trains models, checks results, and writes a recommendation that a non-technical manager can act on without pretending to love residual plots.
The paper’s target is this whole chain. That is why reading it as “AutoML, but agentic” undersells the proposal. AutoML systems are useful, but they usually start after important decisions have already been made: the target is defined, the data is structured, the features are available, and the modelling objective is clear. The paper argues that much of the expensive work happens earlier and later than model selection.
Earlier: what is the dataset actually saying?
Later: what should the business do with it?
The AI Data Scientist is designed around those two gaps. It does not merely optimise a model. It creates a chain from question to hypothesis to feature to prediction to recommendation. Whether that chain is strong enough for production is a separate matter. But the architecture is pointed at the right bottleneck.
The mechanism is a hypothesis rail through six subagents
The system has six specialised subagents:
| Subagent | Immediate job | Operational consequence |
|---|---|---|
| Data Cleaning | Handle missing values, outliers, inconsistent formats, and basic transformations | Reduces garbage-in risk before the LLM starts being impressively wrong |
| Hypothesis | Generate and test statistical claims using methods such as chi-square, t-tests, ANOVA, correlation, regression, clustering, and anomaly checks | Turns plausible patterns into accepted or rejected candidates |
| Preprocessing | Encode, scale, and transform fields while preserving hypothesis-derived information | Keeps modelling preparation aligned with tested relationships |
| Feature Engineering | Build interaction terms, nonlinear transformations, temporal features, aggregations, and other derived variables | Converts validated relationships into model signal |
| Model Training | Train and tune standard models and ensembles using reproducible routines | Separates the more deterministic modelling layer from more flexible LLM-generated code |
| Call-to-Action | Convert technical findings into plain-language recommendations linked to KPIs | Bridges analysis and managerial action |
The key design choice is metadata. Each subagent appends structured notes about what it did: transformations, statistical results, feature origins, model scores, and recommendation context. Later subagents do not start cold. They inherit a trail.
This matters because the common analytics failure mode is context evaporation. A modeller may not know why a variable was binned. A manager may not know whether a feature was engineered because of domain theory, correlation fishing, or someone’s caffeine level. A governance reviewer may not know whether a recommendation came from a model coefficient, a validated group difference, or a slide deck that got too confident.
The paper’s mechanism tries to preserve the thread. A tested hypothesis can become a binary indicator, an interaction feature, a modelling input, and finally a business recommendation. That is the “hypotheses, not hunches” part. The hunch is not allowed to walk into the boardroom without a statistical chaperone.
Why this is not AutoML wearing a chatbot costume
The obvious misconception is to treat the system as ordinary AutoML plus conversational output. That is tempting because the final model-training component does look conventional. It uses standard Python tooling and familiar models: linear methods, random forests, gradient boosting, XGBoost, LightGBM, CatBoost, k-nearest neighbours, naïve Bayes, decision trees, voting ensembles, and stacking ensembles.
But the paper’s claim sits upstream of that modelling layer.
The Hypothesis Subagent proposes testable claims from data summaries. In the churn example, it tests claims such as:
- customers with fewer than two products have a higher exit rate;
- active members are less likely to churn than inactive members;
- customers with tenure under three years are more likely to leave.
These are not merely natural-language insights for a dashboard. The system runs statistical tests, accepts or rejects hypotheses using a significance threshold, and carries accepted hypotheses forward into downstream processing. The Feature Engineering Subagent then builds derived features from those relationships: interactions, ratios, transformations, rank-based variables, and other representations.
The distinction is subtle but important. AutoML asks, “Which model performs best on this prepared dataset?” The AI Data Scientist asks, “Which tested relationships should shape the dataset before modelling begins?”
That is a more ambitious claim. It also creates more places to fail. Hypothesis generation may be shallow. Statistical tests may be misapplied. Multiple comparisons may inflate significance. Features may encode leakage. Recommendations may overstate the business meaning of a predictive association. A mechanism-first reading has to keep both sides visible: the architecture is more interesting than AutoML, and also more fragile.
The evidence says “useful lift,” not “revolution”
The paper evaluates the system across four public datasets: customer churn, diamond pricing, smoking-related health risk, and used-car values. Dataset sizes range from 1,700 to 54,000 records with up to 14 variables. In typical runs, the system produces around 200 predictive features per analysis cycle, though the number can be adjusted.
The main evidence is the benchmark comparison against strong Kaggle-style notebooks with manual feature engineering and tuned models.
| Task | Paper-reported result | Interpretation | Boundary |
|---|---|---|---|
| Customer churn | 86.69% accuracy; 85.52% F1; gains of 1.27 and 1.51 percentage points | Small but potentially useful lift in a business task where marginal recall/precision can matter | Public dataset; production churn economics not validated |
| Diamond pricing | RMSE falls from 52.22 to 42.32, a 19% reduction | Stronger pricing fit, likely helped by engineered nonlinear and interaction features | Public benchmark pricing task, not necessarily live inventory pricing |
| Smoking / health risk | 77.80% accuracy; gains of 1.04 percentage points in accuracy and 2.46 in F1 | Predictive improvement on health-related classification | Health settings need far stricter validation and fairness review |
| Used-car pricing | RMSE decreases from 76,016 to 69,347, a 4.3% improvement | Modest valuation improvement | Market drift, geography, and listing noise may dominate in real deployment |
The responsible reading is neither dismissal nor applause. The reported improvements are not enormous across the board. They do not need to be. In operational analytics, a one- or two-point lift can be valuable if it is repeatable, cheap, and attached to clearer reasoning. The question is whether the mechanism generalises beyond these datasets and whether the cost of reviewing agent-generated hypotheses is lower than the cost of manual exploratory analysis.
The paper gives a plausible first answer. It does not give the final one.
The churn case shows the workflow better than the leaderboard
The churn case study is the most useful part of the paper because it shows the full chain rather than only the score.
The dataset contains 10,000 banking customers with variables such as tenure, credit score, number of products, account balance, activity status, and geography. The system runs the full pipeline: it cleans the dataset, generates hypotheses, tests them, encodes accepted hypotheses, engineers features, trains an ensemble, and produces business-facing churn recommendations.
Three representative hypotheses are especially revealing:
| Hypothesis | Test logic | Downstream role |
|---|---|---|
| Customers with fewer than two products have higher exit rates | Segment customers by product count and run a chi-square test against churn status | Becomes a risk signal and a basis for bundled-product retention actions |
| Active members are less likely to exit | Compare churn across active and inactive groups using a contingency-table test | Becomes a behavioural engagement feature and retention narrative |
| Customers with tenure under three years face higher churn risk | Compare exits for short-tenure and longer-tenure groups | Becomes a tenure-cliff signal for onboarding and early-life retention |
This is where the paper’s architecture becomes practically legible. A churn model can already use product count, activity status, and tenure. The contribution is that the system explicitly tests these relationships, records them, turns them into features, and then translates them into business actions.
That trace is valuable. It gives a retention manager something more useful than “the model says this customer is risky.” It gives a chain: this group behaves differently; the difference passed a statistical test; the relationship was encoded into features; the model used enriched inputs; the recommendation targets the underlying pattern.
Of course, the pattern is still associative. If customers with fewer than two products churn more often, it does not prove that giving them another product will retain them. They may have fewer products because they were already disengaged, lower value, poorly served, or simply not suited to the bank’s offerings. The agent can identify where to look. It cannot, by itself, validate the intervention.
This is not a small caveat. It is the difference between “launch a bundle campaign” and “run a targeted experiment to test whether a bundle campaign actually reduces churn.” One is analytics theatre with a budget. The other is management.
The ablation table is the hinge
The paper’s ablation study is the most important evidence for the mechanism. Benchmark gains can come from many sources: stronger models, more features, better tuning, lucky dataset fit, or plain evaluation quirks. Ablation asks a cleaner question: what happens when parts of the agent are removed?
The reported ablation results are:
| Configuration | Churn accuracy | Diamond RMSE | Runtime | Features generated | Likely purpose |
|---|---|---|---|---|---|
| Full Agent | 86.69% | $1,247 | 12 min | 147 | Main system evidence |
| No Hypothesis Subagent | 84.12% | $1,458 | 8 min | 89 | Tests whether hypothesis generation adds value |
| No Feature Engineering Subagent | 83.45% | $1,592 | 10 min | 52 | Tests whether hypothesis-derived features matter |
| Preprocessing Only | 82.01% | $1,734 | 6 min | 23 | Lower-bound simplified workflow |
This table does more work than the headline benchmark. Removing the Hypothesis Subagent reduces churn accuracy by 2.57 percentage points and worsens diamond RMSE. Removing Feature Engineering reduces performance even more on churn. The preprocessing-only variant is faster but materially weaker.
That supports the paper’s central mechanism: the hypothesis and feature-engineering stages are not decorative. They appear to contribute predictive signal.
Still, ablations do not prove every design choice is optimal. The table does not tell us whether the hypotheses are semantically deep, whether the statistical tests are always appropriate, whether the generated features are stable across resamples, or whether a skilled human team would create a smaller and better feature set. It also does not fully isolate the effect of “more features” from the effect of “better features.” If the full system creates 147 features and the no-hypothesis variant creates 89, the gain may partly reflect feature volume.
That does not invalidate the result. It tells us what to ask next: are hypothesis-grounded features more robust than brute-force generated features under drift, leakage checks, and out-of-sample production data?
The paper opens that question. It does not close it.
The cost table is a deployment sensitivity test
The paper also compares LLM backends. This is not main scientific evidence about the analytics mechanism. It is a deployment sensitivity test: can the system run at different cost, latency, and model-quality trade-offs?
| LLM backend | Cost per analysis | Processing time | Tokens used | Business reading |
|---|---|---|---|---|
| GPT-4o | $0.49 | 8–12 min | 2,800–3,200 | Stronger default for quality-sensitive hypothesis generation |
| Llama 3.1 70B | $0.12 | 10–15 min | 2,600–3,000 | Mid-cost option where infrastructure access is available |
| PHI-4 | $0.007 | 15–25 min | 2,400–2,800 | Cheap enough for frequent lower-risk runs, if quality holds |
| Qwen2.5-72B | $0.08 | 12–18 min | 2,700–3,100 | Another mid-cost candidate for mixed-model deployment |
The practical inference is not “always use the cheapest model.” The paper itself suggests a multi-LLM strategy: use stronger models where factual accuracy and reasoning quality matter more, and cheaper models where tasks are more mechanical.
That maps naturally onto the subagent design. Hypothesis generation and recommendation writing are higher-risk semantic tasks. Feature generation may also create risk if it invents transformations that encode leakage or nonsense. Model training, by contrast, is largely handled through predefined Python routines, which is a sensible design choice. Do not ask the language model to improvise where deterministic machinery already exists. Even agents deserve adult supervision.
For operators, the cost numbers are encouraging because they make iterative analysis plausible. A $0.49 run is not expensive. But the API bill is not the full cost. The real cost includes review time, integration, governance, data access controls, logging, monitoring, and correcting outputs when the agent mistakes statistical confidence for managerial wisdom.
The cheap run is the beginning of the expense, not the end.
The roadmap is sensible, provided the first phase is not fake theatre
The paper proposes a staged adoption path: proof of concept over months 0–3, operational integration over months 4–9, and enterprise deployment over months 10–18. That sequencing is reasonable, especially for an agent that touches analytics, code generation, model training, and business recommendations.
The useful version of the roadmap would look like this:
| Phase | What to test | What not to pretend |
|---|---|---|
| 0–3 months: proof of concept | Can the system reproduce benchmark-quality results on known datasets? Are hypotheses plausible? Are features traceable? Are recommendations reviewable? | Do not call this production readiness just because the leaderboard score looks nice |
| 4–9 months: operational integration | Can analysts audit prompts, code, tests, features, and outputs? Can business users distinguish association from action? | Do not assume adoption is solved by adding a chat interface |
| 10–18 months: enterprise deployment | Can the system meet RBAC, monitoring, compliance, fairness, drift, and escalation requirements? | Do not let the agent make high-impact decisions without governance |
A good pilot should include deliberately boring questions. How often does the system choose the wrong statistical test? Does it detect leakage? Does it generate unstable features? Does it give different recommendations across runs? Does it preserve enough metadata for audit? Can a domain expert reject a hypothesis and feed that correction back into the workflow?
This is where many enterprise AI pilots go to become slideware. They test whether the demo is impressive, not whether the workflow survives contact with messy data, sceptical users, and compliance teams.
The AI Data Scientist architecture is well suited to a serious pilot because its intermediate artefacts are inspectable: hypotheses, tests, features, model results, and recommendations. That inspectability should be used aggressively. Otherwise the organisation has not adopted a data scientist. It has adopted a very articulate spreadsheet goblin.
What business teams can actually do with it
The best near-term use case is first-pass analytical acceleration. The system can take a structured dataset and produce a candidate map of relationships, features, models, and recommendations. That is valuable when the alternative is a blank notebook, a backlogged analytics team, or a dashboard that answers yesterday’s question with last quarter’s data.
The second use case is hypothesis inventory. Many organisations have more questions than analysts. An agent that can rapidly generate and test candidate relationships gives teams a ranked starting point. Not truth. Starting point.
The third use case is feature traceability. In regulated or semi-regulated environments, teams need to explain why a model uses certain variables or transformations. A feature linked back to a tested hypothesis is easier to review than a mysterious column named final_feature_237.
The fourth use case is business translation. The Call-to-Action Subagent is not valuable because executives cannot read numbers. It is valuable because technical outputs often fail to specify ownership, timing, metric linkage, and action. A recommendation connected to a KPI and a measured pattern is more usable than a model card abandoned in a shared drive.
A practical adoption framework would separate direct evidence from business inference:
| Layer | What the paper directly shows | Cognaptus business inference | What remains uncertain |
|---|---|---|---|
| Workflow automation | Six subagents can execute an end-to-end tabular analytics pipeline | Useful for accelerating repeatable exploratory analysis | Robustness on messy enterprise data |
| Hypothesis testing | Generated hypotheses can be statistically tested and passed downstream | Better traceability between insight and model feature | Test selection quality and multiple-testing control in the wild |
| Predictive performance | Reported gains on four public datasets | Small lifts may matter at scale if repeatable | Production lift under drift and leakage controls |
| Cost/runtime | Runs can be low-cost across LLM backends | Frequent analysis cycles may be economically feasible | Human review and integration costs dominate total cost |
| Recommendations | CTA outputs connect findings to actions and KPIs | Useful for analyst-to-operator translation | Whether actions cause the desired business outcome |
This framing keeps the promise useful without letting it become mythology. The paper directly shows a working automated pipeline with encouraging results. The business inference is that such systems can reduce time-to-insight and improve traceability. The unresolved question is whether those gains survive production constraints.
The uncomfortable boundary: significance is not causality
The paper is explicit about this, and the article should be too: statistical significance is not causality.
A hypothesis may pass a chi-square test and still be useless for intervention. A group difference may be real and still have no practical effect. A feature may improve prediction and still encode a proxy for unfair treatment. A recommendation may sound rational and still fail when implemented.
This matters most in the Call-to-Action stage. The system may recommend retention campaigns, pricing interventions, operational changes, or monitoring targets. Those recommendations are grounded in observed patterns, but observed patterns do not automatically identify what will happen if the business changes policy.
For lower-risk analytics, that may be acceptable. A retailer using the system to prioritise exploratory analysis can tolerate some false starts. A bank using it for credit decisions, a hospital using it for triage, or an insurer using it for pricing cannot. In high-stakes domains, the workflow needs additional layers: causal analysis, experimental design, fairness audits, subgroup performance checks, model-risk review, and decision accountability.
The paper also notes dataset constraints. Small datasets may lack power. Very large datasets can make trivial differences statistically significant. Poorly labelled or inconsistent data can produce misleading hypotheses. Complex ensembles can reduce interpretability even if the hypothesis layer improves transparency. LLM-generated hypotheses may reflect training-data biases or miss domain-specific subtleties.
These are not generic “AI has risks” disclaimers. They affect how the system should be used. The right role is assisted analysis with reviewable intermediate artefacts, not autonomous decision-making.
The real contribution is workflow memory
The most interesting part of the AI Data Scientist is not that it has six agents. Agent counts are cheap. One can always add another subagent and call it architecture. The interesting part is workflow memory: the system tries to remember why each analytical step exists.
A hypothesis is generated because the data suggests a possible relationship. It is tested because plausibility is not enough. It is encoded because modelling needs structured signal. It is transformed into features because raw variables rarely capture the whole pattern. It is used in a model because prediction still matters. It is translated into recommendations because business value does not emerge from an F1 score by osmosis.
That chain is the contribution.
If the approach matures, its value will likely appear in three places. First, faster first drafts of analysis. Second, better documentation of how insights become features and actions. Third, more disciplined collaboration between human analysts and automated systems.
The system will not remove the need for statistical judgement. It may, however, make the absence of judgement easier to spot. That is progress of a sort.
Conclusion: the agent is useful when it stays humble
The AI Data Scientist paper lands in a crowded space: agentic AI, AutoML, data science automation, enterprise analytics, LLM orchestration. The easy version of the story would be that agents are coming for the data science department. The better version is more specific and more useful.
The paper shows how an automated system can use hypotheses as the spine of an analytics workflow. Cleaning, testing, preprocessing, feature engineering, modelling, and recommendations are not treated as disconnected tasks. They are linked through structured metadata and validated relationships. The reported results are encouraging: modest classification lifts, stronger regression performance on some tasks, low per-run costs, and meaningful ablation drops when the hypothesis and feature-engineering stages are removed.
That is enough to take seriously.
It is not enough to trust blindly.
For operators, the sensible adoption path is to use systems like this as fast, inspectable analytical co-workers: good at generating candidate hypotheses, building feature sets, benchmarking models, and drafting recommendations; not authorised to decide causality, allocate capital, approve credit, diagnose patients, or redesign strategy without adult supervision.
The machine can produce hypotheses. The business still has to decide which ones deserve belief, budget, and a controlled experiment.
\ast\astCognaptus: Automate the Present, Incubate the Future.\ast\ast
-
Farkhad Akimov, Munachiso Samuel Nwadike, Zangir Iklassov, and Martin Takáč, “The AI Data Scientist,” arXiv:2508.18113, 2025, https://arxiv.org/abs/2508.18113. ↩︎