TL;DR for operators
Most agent projects fail in a wonderfully unglamorous place: not at “intelligence”, but at the loop. The agent forgets what it already did. It calls the wrong tool. It reflects poetically instead of usefully. It delegates to three other agents because the demo looked impressive, then spends the next minute staging a management retreat in token form. Charming, but not production.
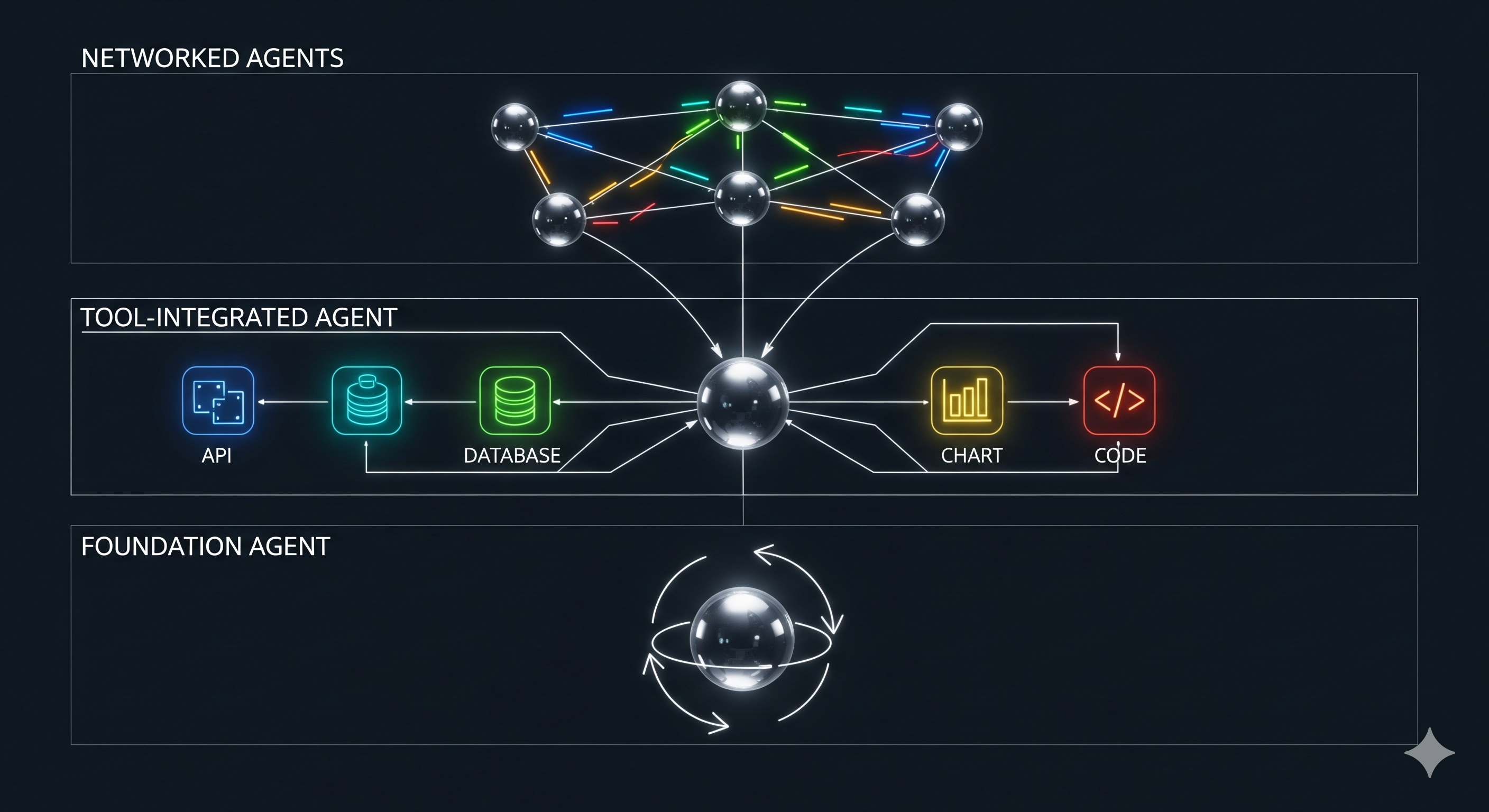
The useful contribution of LLM-based Agentic Reasoning Frameworks: A Survey from Methods to Scenarios is that it shifts the discussion from model capability to framework control.1 The paper’s three-layer taxonomy—single-agent methods, tool-based methods, and multi-agent methods—is best read as a map of where operators can intervene in an agent’s reasoning loop.
The practical lesson is simple: start with the smallest loop that can reliably finish the job.
| If the workflow failure is… | First control point to inspect | Likely minimum intervention |
|---|---|---|
| The answer drifts or ignores constraints | Initial context and task description | Better prompt schema, role, environment, examples |
| The agent repeats mistakes | Reflection and context update | Structured self-critique or memory of failed attempts |
| The answer is plausible but under-informed | External information boundary | RAG, API calls, database access, code execution |
| Tool calls are brittle or costly | Tool selection and utilization | Rule-based routing, middleware, retries, parallel calls |
| One agent cannot decompose the work | Organisation and interaction | Centralised, decentralised, or hierarchical multi-agent design |
| Runs never end cleanly | Termination condition | Machine-checkable stopping rule, test, linter, acceptance criterion |
The business interpretation is not “multi-agent systems are the future”. That is the sort of sentence that makes architecture diagrams reproduce without supervision. The better reading is: single-agent design shapes reasoning, tool-based design expands action, and multi-agent design restructures coordination. Each layer buys capability by spending cost, latency, governance complexity, and debugging patience.
The agent is not the model; it is the loop around the model
A normal LLM interaction is roughly: provide context, get output. An agentic system stretches that into a repeated process: receive a user query, initialise context, choose an action, produce an intermediate output, update context, possibly call a tool, possibly reflect, possibly update the goal, and continue until a termination condition says the work is done.
That is the paper’s most valuable move. It proposes a unified formal language and a general reasoning algorithm for framework-level agentic reasoning. The point is not mathematical glamour. The point is diagnostic discipline. Once the reasoning process is decomposed into control points, “the agent is bad” becomes too vague to be useful.
A production failure can now be located.
Maybe context was badly initialised. Maybe the action space was too broad. Maybe the tool was available but selected poorly. Maybe the reflection step kept adding noise to the context. Maybe the termination condition was an aspiration rather than a condition. Maybe the multi-agent interaction protocol created more disagreement than signal. This is less exciting than saying “agentic AI will transform work”. It is also how anything actually gets fixed.
The paper’s framework separates several concepts that operators often blend together:
| Framework component | What it controls | Enterprise debugging question |
|---|---|---|
| Context | What the agent currently knows and remembers | Did the agent carry forward the right state? |
| Action space | What the agent is allowed to do next | Did we give it useful actions or a toy menu? |
| Tool call | How the agent reaches outside the model | Did it retrieve, compute, execute, or merely improvise? |
| Reflection | How it evaluates previous steps | Did self-critique improve the next step or just consume tokens? |
| Goal update | How the objective changes over time | Is the agent adapting or wandering? |
| Termination | When the loop stops | Is “done” testable, or just vibes in a trench coat? |
This is why the accepted mechanism-first framing matters. A survey recap would become a catalogue of named systems. A mechanism-first reading turns the survey into a build manual: identify which part of the loop needs control, then choose the lightest architecture that supplies it.
Layer 1: single-agent methods shape the starting conditions and self-correction
The paper’s first layer is single-agent methods. These do not primarily expand what the system can do in the world. They change how one agent frames and manages the task.
Prompt engineering appears here not as a bag of incantations, but as context initialization. Role-playing, environment simulation, task description, and in-context examples all modify what the agent receives before the loop begins. That is useful because many business workflows fail before the first tool call. A finance reconciliation agent that is not told the tolerance threshold, required output schema, and escalation rule is not “autonomous”. It is merely under-briefed.
The paper is also clear that prompt methods are not magic dust. Role-playing can focus behaviour, but persona design can also introduce bias or false confidence. In-context examples can guide reasoning, but poor examples can degrade it. Long task descriptions can clarify requirements, but they can also burden the model. The operator’s lesson: prompts are control surfaces, not decorations.
Self-improvement methods go one step deeper. Reflection lets an agent analyse a previous trajectory and store lessons for future steps. Iterative optimisation adds a target standard and loops until the output satisfies it. Interactive learning allows goals to update in response to the environment.
For business use, iterative optimisation is the most immediately legible. It turns “make this good” into “keep revising until this measurable condition is met”. In software, that condition might be tests passing. In document processing, it might be field completeness and schema validity. In customer operations, it might be policy compliance plus confidence above a threshold. No threshold, no loop. Just a chatbot with stamina.
The important distinction is between reflection as performance control and reflection as theatre. A useful reflection step changes the next action: it records a failed tool choice, identifies missing evidence, shortens a plan, or updates a constraint. A decorative reflection step says “I should be more careful next time”, which is also what interns say after deleting a spreadsheet. Possibly sincere. Not yet an architecture.
Layer 2: tool-based methods expand the action space, then create new failure modes
Tool-based methods expand the agent’s boundary. Instead of relying only on internal model knowledge, the agent can call APIs, plugins, middleware, retrieval systems, code interpreters, visualisation tools, databases, or domain software.
The paper divides this layer into three questions: integration, selection, and utilisation.
Integration is the boring part until it breaks, which means it is the important part. API-based integration gives agents access to external systems through stable contracts. Plugin-based integration places capabilities such as RAG or visualisation closer to the agent runtime. Middleware abstracts the mess: authentication, schemas, retries, execution environments, file systems, and tool interoperability.
Selection determines which tool the agent chooses. The paper distinguishes autonomous selection, rule-based selection, and learning-based selection. Autonomous selection is flexible but depends heavily on tool descriptions and model reasoning. Rule-based selection is reliable for known workflows but brittle when the situation falls outside the rulebook. Learning-based selection lets the agent adapt based on feedback, but only if the feedback loop is itself trustworthy. Tiny inconvenience: the loop that teaches the agent can also teach it nonsense.
Utilisation determines how tools are used. Sequential use is easy to inspect but can become slow and vulnerable to cascading failure. Parallel use can reduce wall-clock time when sub-tasks are independent, but then the system needs aggregation logic for conflicting outputs. Iterative use is valuable for tools like code execution, where the agent can run, inspect errors, patch, and rerun before moving on.
The business implication is that adding tools does not automatically make an agent more reliable. It relocates the reliability problem. You have fewer hallucinations about unknown data, perhaps, but more risks around stale retrieval, failed API calls, bad routing, credential exposure, tool output conflicts, and runaway loops.
So the operator’s tool question should not be “can we connect it?” It should be:
- What external capability is actually missing?
- How should the agent choose the tool?
- How should failed calls be handled?
- How is tool output validated before entering the context?
- What stops the tool loop?
That last question deserves special affection. Without a termination condition, tool-using agents can become very expensive ways to repeatedly discover that an API is down.
Layer 3: multi-agent systems change information flow, not just headcount
The paper’s third layer is multi-agent methods. This is where many enterprise demos become visually seductive: planner agents, reviewer agents, coder agents, domain experts, managers, negotiators, critics, all apparently collaborating like a consulting firm that bills in tokens.
The survey usefully cuts through this by separating organisation from interaction.
Organisation answers: who sees what, who controls whom, and how outputs flow. A centralised architecture uses a manager or hub agent to plan, coordinate, and synthesise. This improves control but creates a bottleneck and a single point of failure. A decentralised architecture lets peer agents communicate more freely. This can improve robustness and diversity but may reduce efficiency. A hierarchical architecture decomposes work vertically, with higher-level agents planning and lower-level agents executing. This mirrors many business processes, which is convenient, because apparently org charts were waiting patiently to be reinvented by prompts.
Interaction answers: what are agents trying to do with each other? Cooperation aligns agents around a shared objective. Competition uses adversarial challenge or debate to improve reasoning. Negotiation balances conflicting interests and constraints.
These are not interchangeable. A reviewer agent in a software workflow is not the same thing as a peer debater in a diagnostic workflow. A procurement negotiation agent is not a cooperative summariser. The framework must match the task’s coordination structure.
| Multi-agent design | Useful when… | Operational cost |
|---|---|---|
| Centralised | Work needs one coherent plan and synthesis | Bottleneck, manager failure, context overload |
| Decentralised | Diverse perspectives or robustness matter | More communication, slower convergence |
| Hierarchical | Task decomposes into stable sub-processes | Rigidity, handoff errors, hidden assumptions |
| Cooperation | Shared objective is clear | Groupthink if no critique exists |
| Competition | Assumptions need stress-testing | Can increase latency and conflict noise |
| Negotiation | Objectives conflict under constraints | Harder evaluation and policy design |
The survey’s point is not that multi-agent systems are always superior. It is that they modify context and goal updates across multiple agents. The more agents you add, the more important it becomes to govern what each agent knows, what it can do, what it reports, and how disagreement is resolved.
For enterprise teams, the default should be escalation. Use a single reflective agent when the workflow is narrow. Add tools when the agent needs external state or computation. Add multiple agents only when the work genuinely requires decomposition, adversarial review, or role-specialised coordination. Otherwise you are building a meeting, not a system.
The scenario section shows design pressure, not universal ranking
The paper’s scenario review covers scientific discovery, healthcare, software engineering, social simulation, and economic simulation. This is not a benchmark tournament. It is a map of where different framework mechanisms appear when domains impose different constraints.
Scientific discovery pressures agents toward tool use, hypothesis generation, literature retrieval, experiment planning, simulation, and reviewer-style critique. Healthcare pressures them toward diagnostic dialogue, supervision, safety, multimodal data, clinical workflow, and simulated patient environments. Software engineering pressures them toward code generation, testing, repair, repository navigation, and execution feedback. Social and economic simulation pressures them toward population scale, heterogenous agents, memory, behavioural plausibility, and market or social-environment dynamics.
The paper’s tables and figures should be read accordingly:
| Paper element | Likely purpose | What it supports | What it does not prove |
|---|---|---|---|
| Figure 1 research trend chart | Field context | Agentic framework research expanded sharply after 2023 | That growth equals maturity or deployment readiness |
| Algorithm 1 formal loop | Main conceptual contribution | A shared grammar for comparing framework-level reasoning | That one loop fits every production system without adaptation |
| Method taxonomy figures | Organising framework | Single-agent, tool-based, and multi-agent mechanisms can be separated analytically | That the categories are mutually exclusive in deployed systems |
| Scenario evaluation tables | Evidence mapping | Different domains use different metrics, benchmarks, datasets, and case studies | That results are directly comparable across domains |
| Software benchmark table | Comparison with prior work | Agentic coding systems can perform strongly on common code benchmarks | That framework design alone caused every performance difference |
The software engineering section offers the most concrete numerical anchor. The survey includes a Pass@1 comparison table across coding methods and benchmarks. For example, the table reports GPT-4 at 67.6 on HumanEval, GPT-4o at 90.2, Claude-3.5 Sonnet at 92.0, and AgentCoder with GPT-4 at 96.3 on HumanEval. It also reports AgentCoder with GPT-4 at 91.8 on MBPP and 91.8 on MBPP-ET.
Those numbers are impressive, but the right interpretation is disciplined. This table is a comparison with prior work, not a controlled ablation isolating one mechanism. Model version, benchmark, prompting, tool use, testing loops, and reporting conventions can all matter. The business takeaway is therefore not “buy a multi-agent coder tomorrow”. It is that code workflows are unusually compatible with agentic loops because they offer executable feedback: tests, compiler errors, linters, diffs, and repository state. Software gives agents something many business workflows lack—a reasonably honest environment that says “no”.
That is why code agents often feel more real than generic office agents. The loop has teeth.
Evaluation should measure process health, not just final answers
The survey repeatedly catalogues evaluation setups by domain. Biochemistry and materials systems use metrics such as correctness, completeness, logical soundness, precision, confidence, self-consistency, and error measures. Healthcare systems are evaluated through medical QA benchmarks, simulated clinical environments, multimodal diagnostic datasets, safety benchmarks, human evaluation, and case studies. Software systems use coding and repair benchmarks with pass rates, test outcomes, and repository-level tasks.
The pattern is more important than any single metric. Agentic systems need evaluation at the loop level.
A final answer can look good while the process is rotten. The agent may have ignored a required source, called an unsafe tool, exceeded cost budgets, failed to preserve audit artefacts, or reached a correct output through a path that cannot be repeated. In regulated or operational settings, that matters.
A practical evaluation stack should therefore include:
| Evaluation layer | Example metric | Why it matters |
|---|---|---|
| Output quality | Accuracy, completeness, correctness, pass rate | Confirms the result is useful |
| Process validity | Valid plan, relevant tool calls, no skipped constraints | Confirms the result was obtained properly |
| Tool reliability | Call success, retry count, stale retrieval rate | Identifies infrastructure failure |
| Loop efficiency | Number of iterations, tokens, wall-clock time | Controls operating cost |
| Termination quality | Correct early stop, no runaway loop | Prevents silent waste |
| Governance | Citations, audit trail, PII handling, permission scope | Makes deployment defensible |
This is where the paper’s formalism becomes practically valuable. If you log context, action, output, reflection, tool call, and termination state, debugging becomes possible. If you only log final answers, you are asking the post-mortem to perform archaeology.
What Cognaptus infers for builders and buyers
The paper directly shows a taxonomy and a cross-domain survey. It does not directly show that one architecture has better ROI than another in a live enterprise deployment. That distinction matters.
What Cognaptus infers is a staged build logic.
First, treat single-agent methods as the baseline. For many workflows, careful task framing, structured input/output, reflection, and a precise stopping rule will outperform a prematurely elaborate system. This is especially true for drafting, classification, extraction, summarisation, and routine decision support.
Second, add tools when the failure is informational or computational. If the agent lacks current data, proprietary documents, transaction history, or executable feedback, no amount of role-playing will fix the missing substrate. Connect the right tool, route it carefully, and validate the result before it enters the agent’s context.
Third, add multiple agents when the work structure demands roles. Multi-agent systems make sense when work decomposes into specialist tasks, when critique is necessary, when trade-offs need negotiation, or when independent perspectives reduce risk. They make less sense when the real problem is a weak prompt, missing data, or a nonexistent stop rule.
For buyers, the taxonomy becomes a vendor interrogation tool. Ask where the system controls context, tools, reflection, coordination, and termination. Ask whether evaluation logs the reasoning loop or merely grades the final output. Ask which failure modes are handled by rules, which are handled by learned behaviour, and which are handed to the customer with a smile.
For builders, the taxonomy becomes an architecture checklist. Before adding a second agent, define the first agent’s context update. Before adding a tool marketplace, define tool selection. Before adding reflection, define what reflection is allowed to change. Before shipping anything, define termination. The clock is running, and tokens are not a governance strategy.
The boundary: this is a design grammar, not a deployment guarantee
The paper is a survey. Its strength is synthesis, not causal testing. It organises a fast-moving field, proposes a formal language, maps method categories, and reviews representative systems across major domains. That makes it valuable for orientation and design. It does not make it a universal benchmark.
Three boundaries matter.
First, the survey intentionally focuses on framework-level reasoning and excludes many model-level techniques such as supervised fine-tuning and reinforcement learning from the main taxonomy. That is methodologically clean, but real systems often combine both. In production, model choice, fine-tuning, retrieval quality, data freshness, interface design, and workflow integration all interact with framework design.
Second, evaluation remains heterogeneous. A medical diagnosis benchmark, a software repair task, a molecular design case study, and a social simulation are not measuring the same kind of success. Cross-domain comparison should therefore be qualitative unless the evaluation protocol is aligned.
Third, more autonomy increases the surface area for failure. The paper’s future directions are well chosen: scalability and efficiency, open-ended autonomous learning, dynamic reasoning frameworks, ethics and fairness, reliability and safety, confidence estimation, and explainability. These are not decorative limitations. They are deployment conditions.
The business reader should therefore resist both lazy extremes. “Agents are just prompts” is wrong; the framework genuinely changes the reasoning process. “Agents are autonomous workers” is also wrong; most current systems are structured loops whose reliability depends on carefully designed context, tools, feedback, and stop conditions.
The truth is less cinematic and more useful.
The playbook is control before complexity
The most useful way to read the paper is as a hierarchy of control.
Single-agent methods control how the model reasons within a task. Tool-based methods control how the agent reaches beyond itself. Multi-agent methods control how reasoning is distributed across roles. Scenario analysis shows which controls different domains tend to require. Evaluation tables remind us that the output is only one part of the story.
That gives operators a sober rule: do not buy autonomy by the kilogram. Build the loop you can observe, test, and stop.
Start with a precise single-agent workflow. Add tools only when the task needs external knowledge, computation, or execution. Add multiple agents only when coordination creates more value than it consumes. Then measure the process, not just the answer.
It is not as glamorous as promising a digital workforce. It is merely how shippable systems are made. Tragic, really.
Cognaptus: Automate the Present, Incubate the Future.
-
Bingxi Zhao, Lin Geng Foo, Ping Hu, Christian Theobalt, Hossein Rahmani, and Jun Liu, “LLM-based Agentic Reasoning Frameworks: A Survey from Methods to Scenarios,” arXiv:2508.17692, 2025. ↩︎