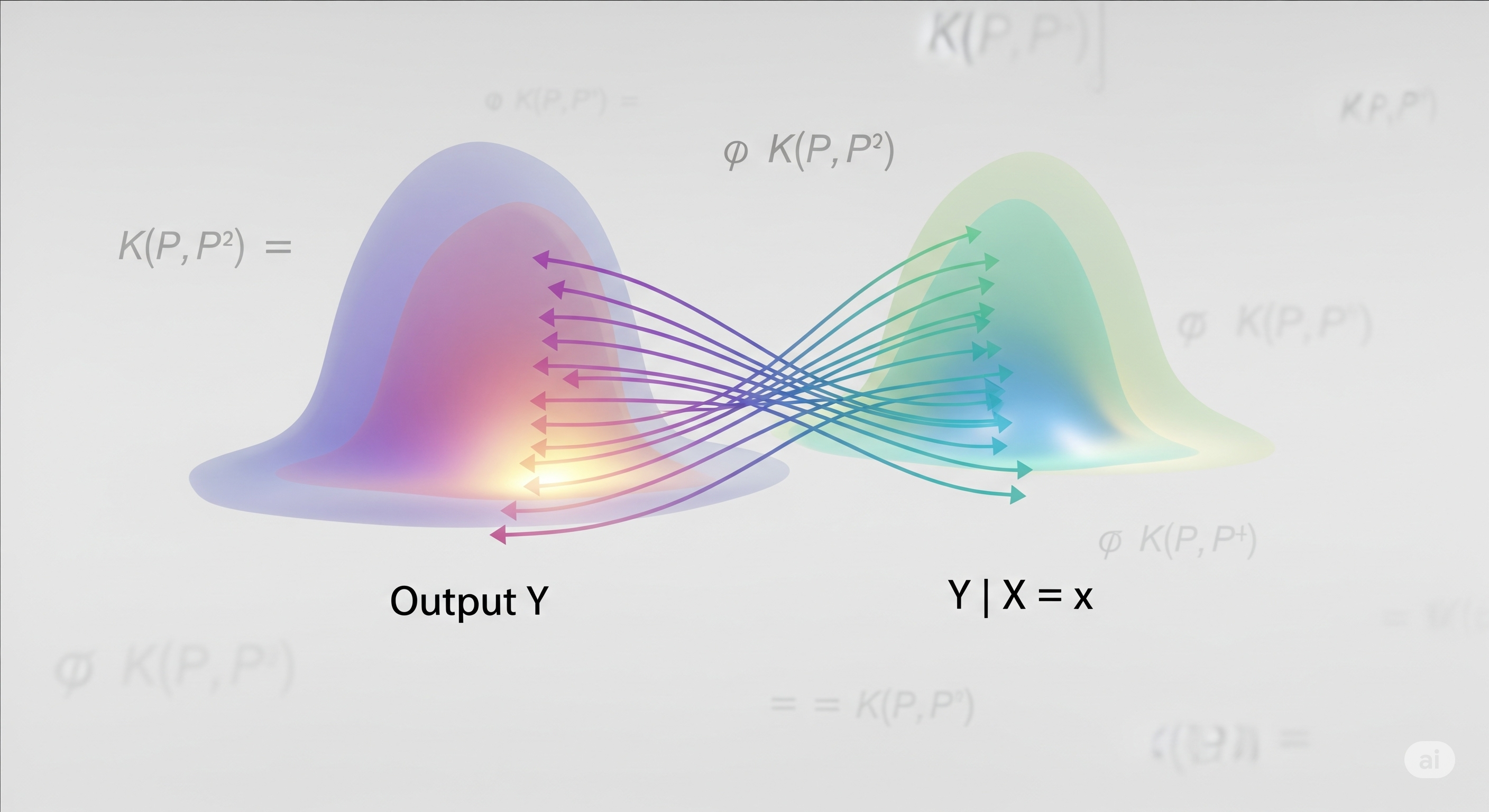
From Sobol to Sinkhorn: A Transport Revolution in Sensitivity Analysis
In a world where climate models span continents and economic simulators evolve across decades, it’s no longer enough to ask which variable affects the output the most. We must now ask: how does each input reshape the entire output distribution? The R package gsaot brings a mathematically rigorous answer, harnessing the power of Optimal Transport (OT) to provide a fresh take on sensitivity analysis. ...