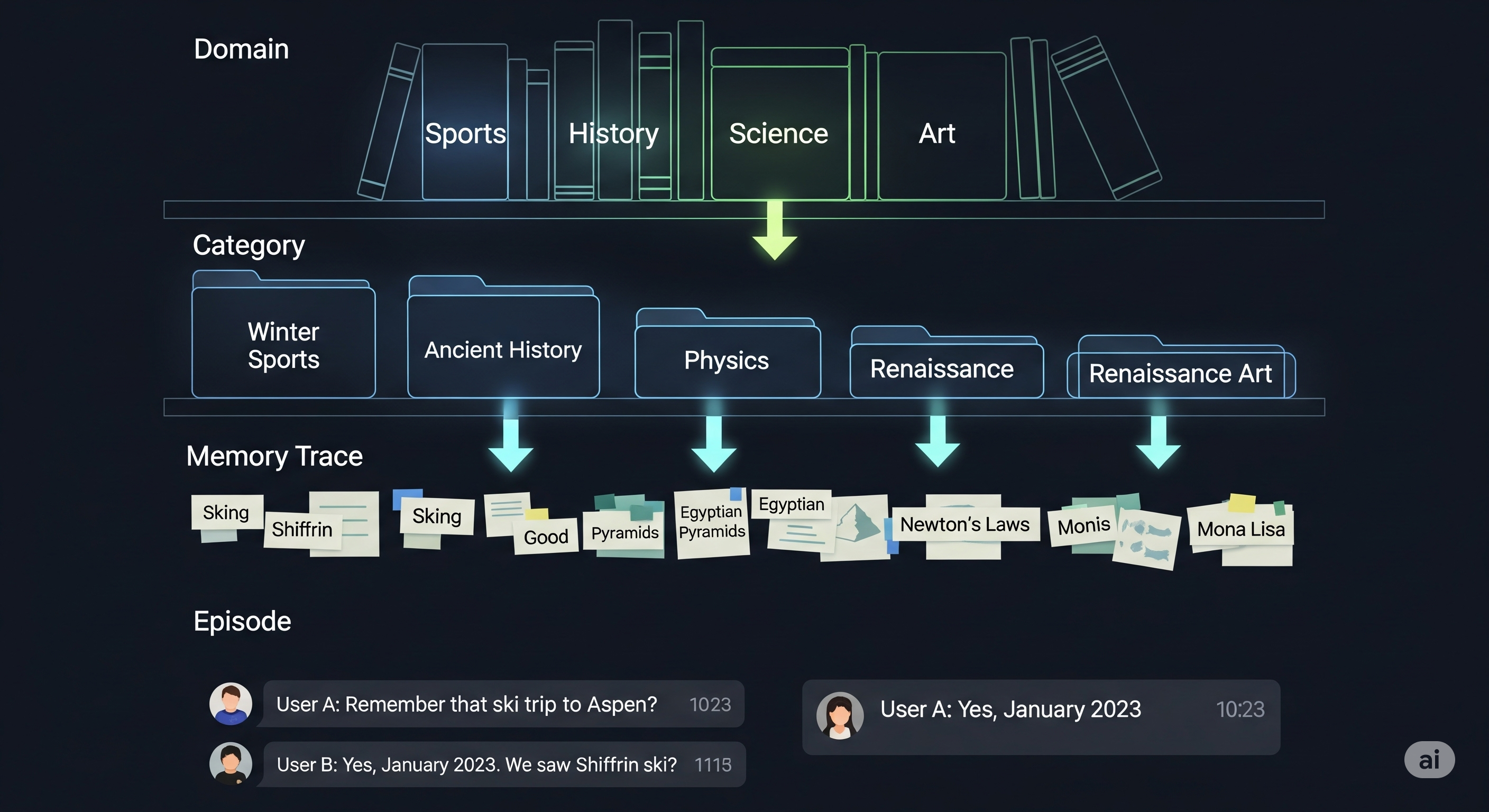
Memory With a Pulse: Real-Time Feedback Loops for RAG Systems
Ask an enterprise chatbot the wrong question on the wrong day and the problem is rarely that the language model has forgotten how to write English. The problem is that it has been handed the wrong pile of evidence. That is the expensive little defect inside many retrieval-augmented generation systems. The model may be fluent. The corpus may be current. The vector database may be humming along like a well-funded filing cabinet. Yet the answer still disappoints because the system chose the wrong snippets, placed a useful document too low, missed a newly relevant runbook, or treated yesterday’s user intent as if it were carved into basalt. ...