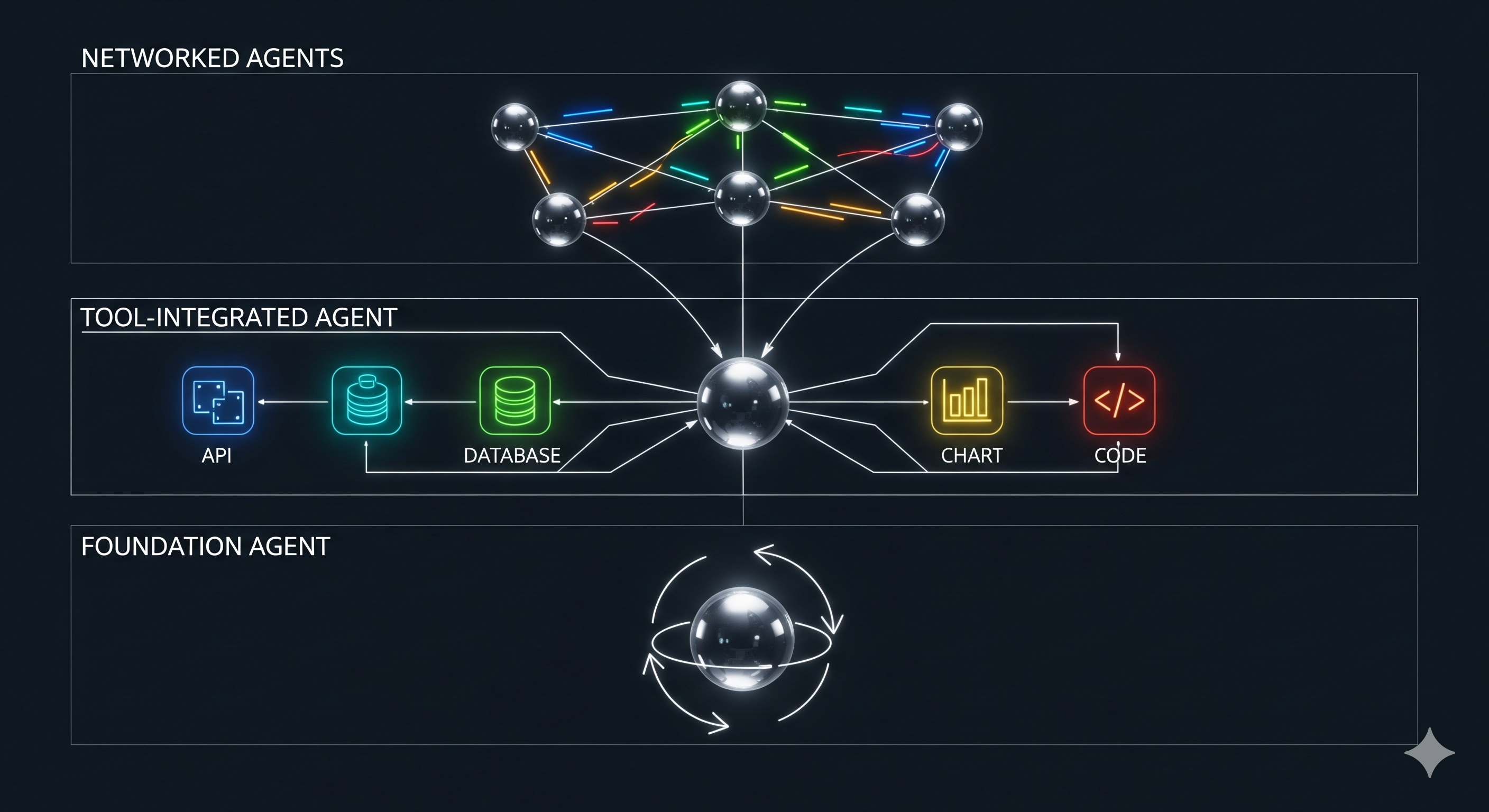
Mirror, Signal, Maneuver: How 'Self' Labels Nudge LLM Cooperation
TL;DR for operators A paper on LLM self-recognition used an iterated public goods game to test a deceptively small intervention: tell an agent it is playing against “another AI agent,” or tell it it is playing against a model with its own name.1 The result was not a clean fairy tale about models recognising themselves and becoming benevolent little collectivists. Shame. That would have been simpler. ...