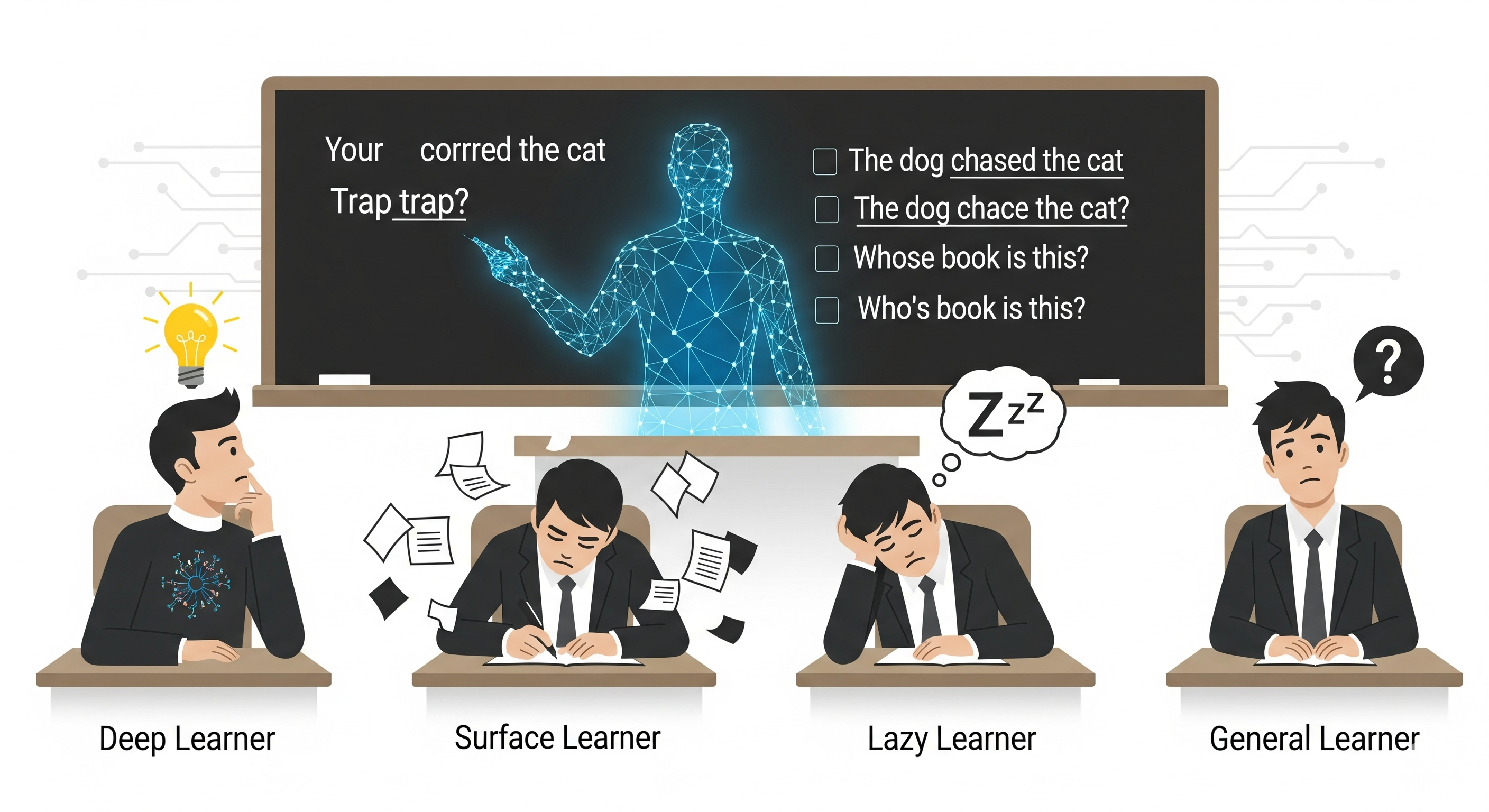
From Black Box to Glass Box: DeepVIS Makes Data Visualization Explain Itself
When business leaders ask for a “quick chart,” they rarely expect to become detectives in the aftermath—trying to work out why the AI picked that chart type, grouped the data that way, or left out important categories. Yet that’s exactly the frustration with most Natural Language to Visualization (NL2VIS) tools today: they generate results like a magician pulling a rabbit from a hat, with no insight into how the trick was done. ...