TL;DR for operators
LearnerAgent puts LLM-based “students” through a simulated year of high-school English learning: weekly lessons, exercises, monthly exams, memory retrieval, self-reflection, confidence updates, and peer debate.1 The point is not to cosplay a classroom because AI research apparently needed more homework. The point is to observe learning as a process, not merely as a final benchmark score.
The important result is uncomfortable for anyone using LLMs in tutoring, staff training, research assistance, or regulated decision support. The persona-free base model, called the General Learner, behaves like a diligent student. It chooses self-improvement activities, gives reasonably detailed answers, improves over time, and becomes increasingly confident. But when the exam introduces trap questions—items structurally similar to earlier questions but requiring a different answer because the context changed—it behaves much more like a surface learner than a deep reasoner.
That distinction matters operationally. A model can pass routine checks, produce long explanations, and accumulate domain memory while still failing when a familiar pattern is slightly inverted. In enterprise terms, that is the analyst who writes polished summaries until the contract clause, market condition, medical note, or compliance exception stops matching the template.
The paper’s useful contribution is therefore not “LLMs are bad students.” That would be a fun headline and a useless diagnostic. The useful contribution is a testing pattern: evaluate learning longitudinally, split short-term review from transfer questions, measure confidence drift, and test whether peer interaction improves reasoning or merely amplifies persuasion. Final-score dashboards are not enough. They are attendance sheets wearing a lab coat.
The classroom is the mechanism, not the metaphor
A familiar enterprise mistake is to treat an LLM evaluation as a final exam. Give the model a task set, grade the outputs, produce an accuracy number, and then pretend the number has captured competence. It has captured something. Mostly your willingness to confuse a snapshot with a trajectory.
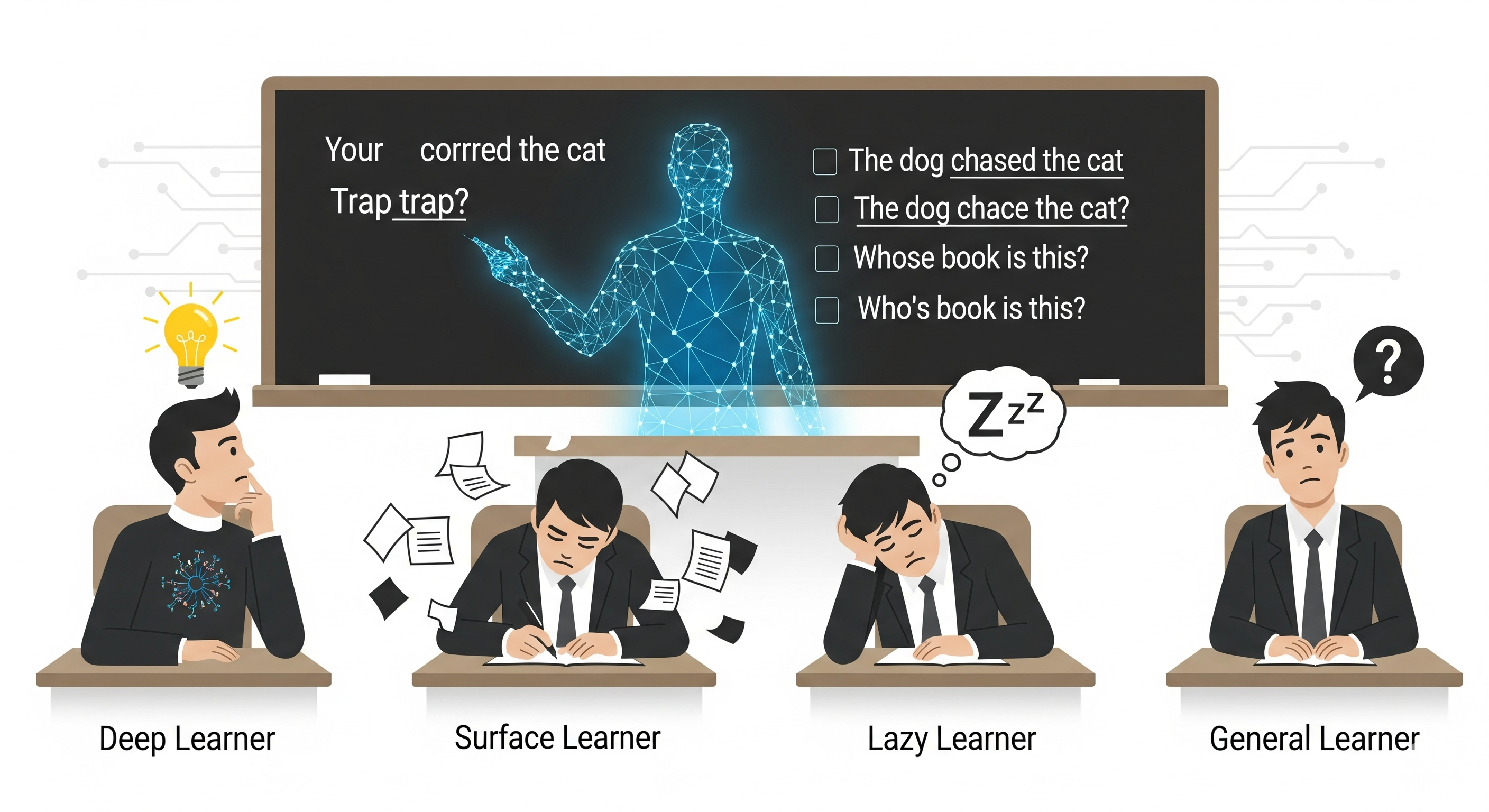
LearnerAgent is built against that habit. The framework creates a simulated learning environment with a Teacher Agent and four Learner Agents. Three learners are explicitly profiled: Deep, Surface, and Lazy. The fourth, the General Learner, receives only basic student identity information and is used as a probe of the base LLM’s default learning tendency.
That fourth learner is the interesting one. The Deep Learner is prompted to seek principles, ask why, connect ideas, and re-analyse familiar-looking problems. The Surface Learner is prompted to pursue scores, memorise key points, and reuse old solutions. The Lazy Learner is prompted to minimise effort. Those profiles are designed. The General Learner is not. It is the simulation’s diagnostic mirror: when an LLM is placed in a classroom without a declared learning style, what kind of student does it become?
The environment then runs for 12 months. In the first three weeks of each month, learners receive teaching material, take notes, and complete weekly tests. At the end of those weeks, they choose whether to summarise knowledge and reflect on errors or rest. In the fourth week, they choose whether to review before a monthly exam. After the exam, learners update their self-concept scores based on their own historical performance and comparison with peers. When learners disagree on answers, they debate, with the teacher deciding whether discussion should continue or stop.
This is why the mechanism matters. The paper is not just asking whether a model can answer grammar questions. It is asking whether different learning styles produce different longitudinal traces across behaviour, memory, confidence, transfer, and social correction.
A one-off benchmark would miss most of that. It would see answers. LearnerAgent watches habits.
The learners are deliberately simple, which is both strength and risk
The profiles are almost archetypal. Deep Learner: intrinsic motivation, high self-concept, long-term development strategy. Surface Learner: extrinsic motivation, moderate self-concept, test-oriented development. Lazy Learner: minimal effort, low self-concept, passive development. General Learner: no explicit motivation, no explicit self-concept, no declared strategy.
That simplicity is useful because it makes the simulation readable. The authors are not building a rich psychological model of a real student with family pressure, sleep debt, social media addiction, and a suspiciously detailed excuse about Wi-Fi. They are isolating learning tendencies.
The Teacher Agent uses Qwen-2.5-72B-Instruct. The Learner Agents mainly use Qwen-2.5-7B-Instruct, with each configuration evaluated over three independent runs. The appendix then repeats core experiments with LLaMA3.1-8B-Instruct learners to test whether the behavioural patterns are model-specific. This matters: the main results are Qwen-centred; the LLaMA section is best read as a robustness check, not as an independent proof that every model family behaves identically.
The testbed is Gaokao English grammar. Each monthly test contains three kinds of questions:
| Question type | What it tests | Why it matters |
|---|---|---|
| Review questions | Current-month content | Short-term retention and routine recall |
| Trap questions | Similar structure, changed context, different answer | Transfer and resistance to shortcut reuse |
| Knowledge-integration questions | Cumulative grammar knowledge | Long-term accumulation across the simulated year |
The trap questions are the hinge. They are generated to look structurally or lexically similar to earlier practice questions, but with a subtle contextual change that makes the previous answer wrong. This is not adversarial trickery in the cartoon sense. It is the kind of twist real work produces constantly: same form, different meaning.
Trap questions separate learning from memorised competence
The paper’s cleanest example is almost embarrassingly small, which is why it works.
In a weekly exercise, the learner sees a sentence like: “I’d like you to take a photo of the ______ (break) cup and send it to me in no time.” The correct answer is “broken,” because the cup is already damaged.
In the monthly trap version, the wording shifts: “I’d like you to take a photo of the ______ (break) cup as it hits the floor.” Now the correct answer is “breaking,” because the sentence describes the action happening at that moment.
Only the Deep Learner adapts correctly. The Surface, Lazy, and General Learners reuse “broken.” This is the whole paper in miniature: the system remembers the pattern, but does not reliably re-derive the answer from the new context.
That is why trap questions are more valuable than harder questions. A hard question can fail for many reasons: missing knowledge, bad parsing, insufficient context, random model instability. A trap question is more surgical. It asks whether the model can notice that the old shortcut is now the wrong shortcut.
For business use, this is the difference between testing whether an AI assistant can process a standard refund request and testing whether it notices that the refund request is invalid because one clause changed. The second test is less glamorous. It is also where the expensive mistakes hide.
The main evidence says diligence can mask brittleness
The longitudinal results are not a simple “Deep good, Lazy bad” morality tale. All learners show some upward trend across monthly tests, with volatility. Surface Learner performs especially well on review questions, which makes sense: a test-oriented, memorisation-heavy strategy is often excellent at short-term recall. General Learner also looks competent in several places, especially on knowledge-integration questions, where it performs strongly as a knowledge accumulator.
Then the trap questions break the illusion.
Deep Learner achieves the strongest trap-question performance. Surface and General struggle the most. The paper’s interpretation is that Surface and General Learners can look capable when the task rewards accumulated patterns, but become brittle when context requires flexible re-analysis. Lazy Learner is weak and volatile, but the more operationally interesting failure is the General Learner: it is not lazy. It is active, engaged, and still shallow under transfer pressure.
This is the warning for AI evaluation. A system can improve on monthly totals and still fail the diagnostic slice that matters. A model can gain experience and still not gain the kind of abstraction you thought experience implied. The benchmark line goes up; the underlying reasoning remains duct-taped to familiar cues.
The paper also compares initial and final exams. Most learners improve in overall performance except the Lazy Learner, and reasoning length increases over time. But longer reasoning is not the same as better reasoning. Surface and Lazy Learners can produce longer explanations without developing the deeper transfer behaviour seen in the Deep Learner.
This should make enterprise evaluators cautious about using “more reasoning text” as a proxy for reasoning quality. Verbosity is cheap. Contrastive reasoning, error diagnosis, and context-sensitive revision are not.
Reasoning style gives a second diagnostic signal
The authors analyse reasoning patterns through two simple proxies: reasoning length and logical connector usage. Deep Learner produces the longest explanations and the richest use of logical connectors, especially contrastive connectors. The interpretation is that Deep Learner is more likely to weigh alternatives and handle nuance, while other learners rely more on linear causal connectors.
This is not a perfect measure of cognition. Counting connectors is a rough instrument. A model can say “however” while doing absolutely nothing however-worthy. The word alone is not intelligence; otherwise every consultant deck would be sentient.
But as part of a larger diagnostic suite, the pattern is useful. The paper is not saying connector density proves understanding by itself. It is saying that reasoning behaviour, when combined with trap-question performance and longitudinal outcomes, helps distinguish learning profiles.
That distinction is practical. For enterprise agents, explanation audits should not simply reward length, confidence, or polished structure. They should look for whether the model compares alternatives, identifies why a tempting answer is wrong, and updates when new context changes the answer. A good explanation is not a longer receipt. It is a stress trace.
Self-concept is where the General Learner becomes operationally dangerous
The self-concept component is one of the paper’s sharper design choices. After monthly tests, learners update their self-concept scores using their own history, peer scores, and an assessment of learning ability, knowledge mastery, progress, peer comparison, methods, and future plans.
The profiled learners mostly behave as their profiles suggest. Deep Learner stays high and slightly rises. Surface Learner declines slightly, reflecting a more fragile self-view. Lazy Learner starts low and improves modestly.
The General Learner is the one to watch. It begins without a predefined profile but develops steadily rising self-concept, eventually moving toward the Deep Learner’s high-confidence region. The problem is that this confidence is not matched by trap-question performance. The base model looks increasingly sure of itself while retaining brittle transfer behaviour.
For businesses, this maps uncomfortably well to deployed AI assistants. The most dangerous model is not always the one that fails loudly. It is the one that has enough routine competence to earn trust, enough fluency to sound reflective, and enough confidence to be persuasive when wrong.
This does not mean LLMs literally possess human self-concept. The simulated learner is producing self-ratings under a prompt regime. But as an evaluation construct, it is still valuable. It captures a calibration problem: whether apparent confidence tracks the kind of competence that matters under changed conditions.
Peer debate tests correction, not just collaboration
The peer-debate mechanism adds another layer. When learners disagree after monthly exams, they debate. The paper evaluates three metrics:
| Metric | Meaning | Operational analogue |
|---|---|---|
| Persuasion | How often the learner convinces a peer to adopt its answer | Ability to argue effectively |
| Resist Wrong | How often the learner keeps a correct answer against wrong peer input | Robustness against misinformation |
| Accept Correct | How often the learner changes from a wrong answer to a correct peer answer | Productive correction |
Deep Learner performs best on Persuasion and Resist Wrong, while still showing willingness to accept correct input. Surface Learner has strong resistance to wrong input and the highest Accept Correct score, but is least persuasive in the table. Lazy Learner is weakest overall. General Learner has the second-highest Persuasion score at 12.0, but weaker Resist Wrong and Accept Correct than the strongest profiles. In plain terms: it can argue, but its correction dynamics are not especially reassuring.
That is a useful distinction for multi-agent systems. Debate can improve outputs, but only if agents are good at both resisting bad arguments and accepting good ones. Otherwise debate becomes theatre: confident agents trading plausible text until one of them wins the vibes.
The appendix case study reinforces this point. The Deep Learner persuades the Surface Learner to revise an answer to “whenever,” using contextual argument rather than mere assertion. That case is illustrative, not the main evidence. The main evidence is the aggregate debate table; the case study makes the mechanism legible.
The appendix supports robustness, not a second thesis
The LLaMA3.1-8B-Instruct experiments are important, but they should not be overread. Their likely purpose is robustness and sensitivity testing: do the broad learner-profile distinctions survive when the underlying learner model changes?
Broadly, yes. LLaMA-based learners also improve over the year with volatility. Deep Learner performs well on trap questions. General and Surface Learners struggle with deeper reasoning. General Learner again emerges as a strong knowledge accumulator on knowledge-integration questions. Behavioural patterns also remain differentiated: Deep, General, and Surface prefer self-improvement, while Lazy Learner rests much more often—24.1% of the time in the LLaMA run.
There are differences. In the Qwen experiments, Surface Learner does especially well on review questions; in the LLaMA experiments, Deep Learner leads review performance and General Learner is weakest there. That variation matters because it prevents an over-neat story. The exact ranking of learners on every question type is not universal. The more stable pattern is the separation between accumulation and transfer: General Learner can store and integrate knowledge, yet still struggles on trap-style deep-understanding checks.
That is the result to carry forward. Not the precise bar heights. The diagnostic geometry.
What the paper directly shows
The paper directly shows that, inside this simulated Gaokao English environment, prompted learner profiles produce distinct longitudinal behaviours. Deep Learner is best at transfer-heavy trap questions and richer reasoning. Surface Learner can perform well on short-term review while failing under subtle contextual shifts. Lazy Learner is volatile and less engaged. General Learner behaves like a diligent but brittle surface learner: engaged, increasingly confident, good at knowledge accumulation, and weak on deeper transfer.
It also directly shows that peer interaction can be measured in more nuanced ways than “did debate improve the answer?” Resist Wrong and Accept Correct are useful because they separate stubborn correctness from productive updating. That distinction is essential for any system that uses multi-agent debate, review chains, or AI-to-AI critique.
Finally, the paper shows that the LearnerAgent framework can produce longitudinal traces across behaviour, memory, performance, reasoning, self-concept, and peer influence. Whether those traces are “human-like” in a strong psychological sense is more debatable. But as a diagnostic scaffold, the design is valuable.
What Cognaptus infers for business use
The business inference is not that companies should simulate a high-school English classroom before deploying every model. Please do not make your procurement team sit through Month 7 grammar revision unless you are trying to lose friends.
The inference is that AI evaluation should become more longitudinal and more adversarially familiar.
A practical enterprise version would include:
| Evaluation layer | What to test | Why it matters |
|---|---|---|
| Routine competence | Standard tasks the model has likely seen in similar form | Measures operational baseline |
| Near-pattern traps | Same structure, subtle contextual reversal | Detects shortcut reuse |
| Longitudinal memory | Whether prior corrections improve later answers | Tests learning-like adaptation in workflows |
| Confidence calibration | Whether certainty tracks trap performance | Finds polished overconfidence |
| Peer correction | Whether critique improves or destabilises output | Evaluates multi-agent review design |
| Explanation quality | Whether the model identifies why tempting answers are wrong | Separates reasoning from decoration |
For AI tutoring platforms, this means student-facing models should not be judged only by answer accuracy or explanation fluency. They should be tested on transfer, misconception repair, and confidence calibration.
For workforce training systems, this means AI coaches should be evaluated over sequences: teach, practice, test, correct, retest. A model that gives excellent first-pass instruction may still fail to diagnose whether the employee actually learned the principle.
For enterprise agents, this suggests a simple but underused practice: build “trap suites” from your own historical cases. Take common workflows, alter one legally or operationally decisive detail, and test whether the agent notices. That is cheaper than discovering shortcut learning in production, where the tuition fees are paid in incident reports.
The boundaries are narrow, and that is fine
The study is a simulation, not a field trial with human learners. The subject matter is English grammar for Gaokao preparation. The main model stack is Qwen, with LLaMA used for additional validation. The learner profiles are prompt-defined. The self-concept scores are simulated self-ratings, not psychological measurements. The trap questions are generated by Gemini-2.5-Pro and manually verified, which is reasonable for the study but not equivalent to a universal benchmark.
These boundaries matter. The paper does not prove that every deployed LLM in every domain is secretly a Surface Learner. It does not prove that longer reasoning is always better, or that contrastive connectors reliably measure cognition, or that multi-agent classrooms are the future of AI training.
What it does offer is a disciplined diagnostic pattern. It shows how to expose a gap between visible diligence and transferable understanding. That is already enough.
The lesson is not “make models study harder”
The tempting conclusion is to make LLMs more diligent: more memory, more reflection, more review, more debate, more procedural scaffolding. Some of that may help. But the General Learner is already diligent. That is the problem.
It studies. It improves. It accumulates. It grows confident. Then it mishandles the trap.
The better lesson is that evaluation must distinguish effort-like behaviour from understanding-like behaviour. In human organisations, we already know this distinction. We have all met the person who attends every meeting, writes immaculate notes, and still misses the one assumption that changed the decision. LLMs can now automate that personality type at scale. Progress, apparently.
For operators, the question is not whether an AI system looks like a good student. The question is whether it notices when the exam has changed.
That is where LearnerAgent earns its keep: not as a classroom fantasy, but as a reminder that the most useful AI tests are often the ones that look nearly identical to yesterday’s task—except for the one detail that makes yesterday’s answer wrong.
Cognaptus: Automate the Present, Incubate the Future.
-
Yu Yuan, Lili Zhao, Wei Chen, Guangting Zheng, Kai Zhang, Mengdi Zhang, and Qi Liu, “Simulating Human-Like Learning Dynamics with LLM-Empowered Agents,” arXiv:2508.05622, 2025. https://arxiv.org/abs/2508.05622 ↩︎