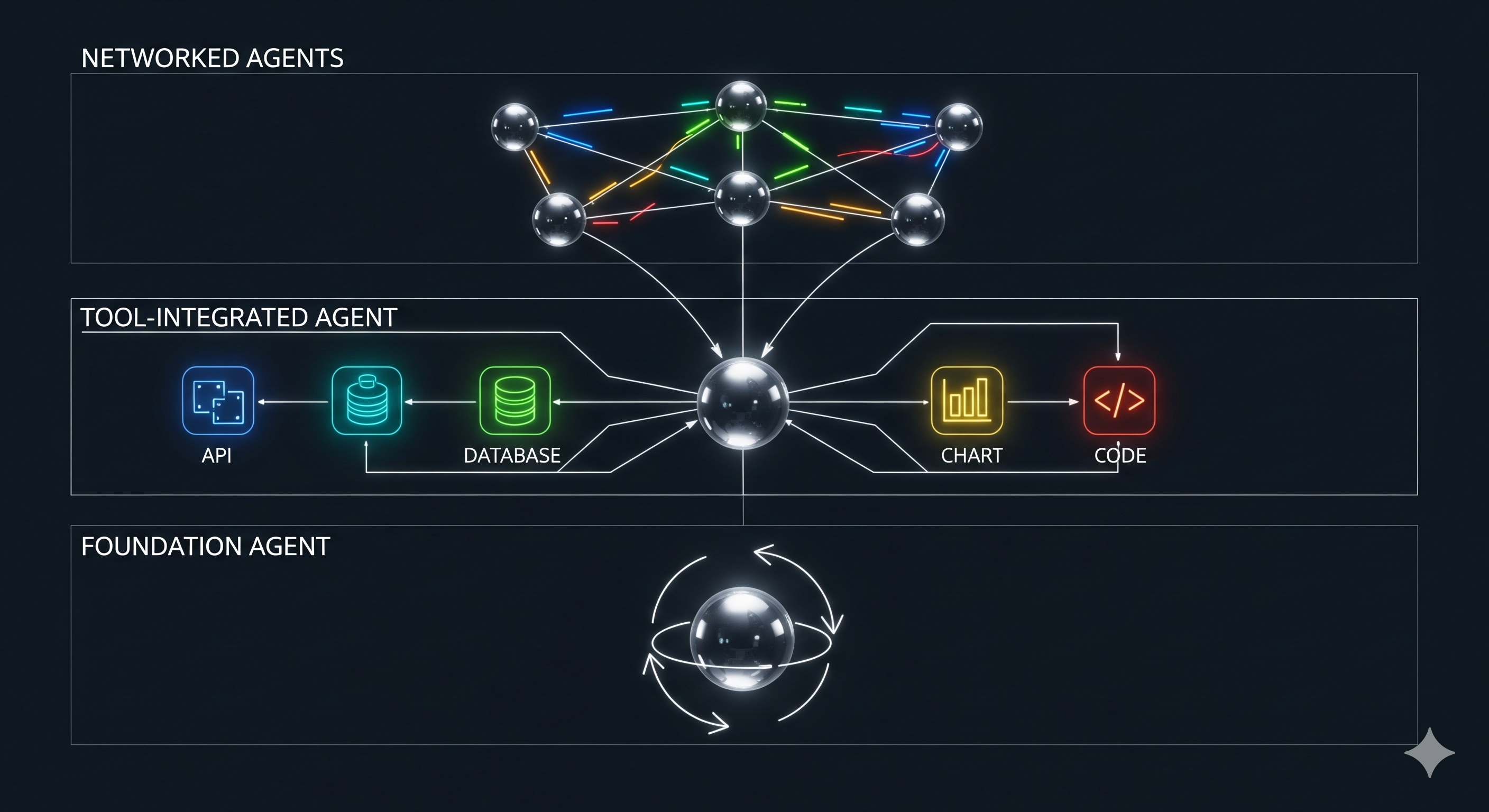
Rules of Engagement: How Meta‑Policy Reflexion Turns Agent Memory into Guardrails
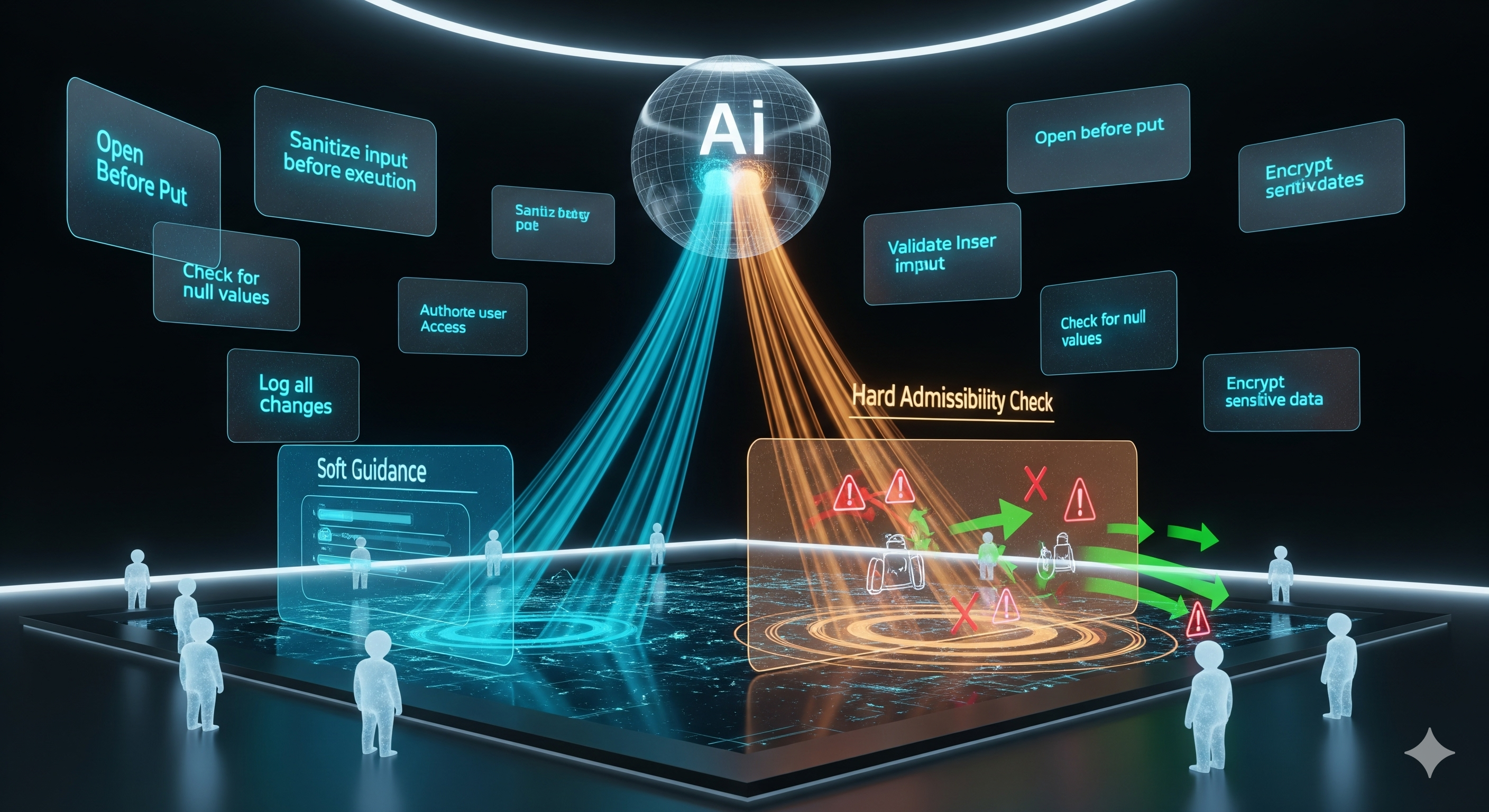
A support bot forgets the same refund exception every Monday. A procurement agent keeps calling the wrong API before checking vendor status. A workflow assistant learns, apologises, retries, then makes the same mistake next quarter because the lesson lived only in the chat transcript. Very human. Also not especially useful. That is the practical problem behind Meta-Policy Reflexion, a paper that asks whether LLM agents can keep the benefit of verbal self-reflection without turning every failure into a one-off therapy session.1 The authors propose Meta-Policy Reflexion (MPR), a training-free framework that distils failed-trajectory reflections into a structured Meta-Policy Memory (MPM), then uses that memory in two ways: softly, by putting relevant rules into the agent’s prompt; and hard, by checking generated actions against admissibility constraints before execution. ...