ReAct Without the Chaos: AgentScope 1.0 Turns Tools into Strategy
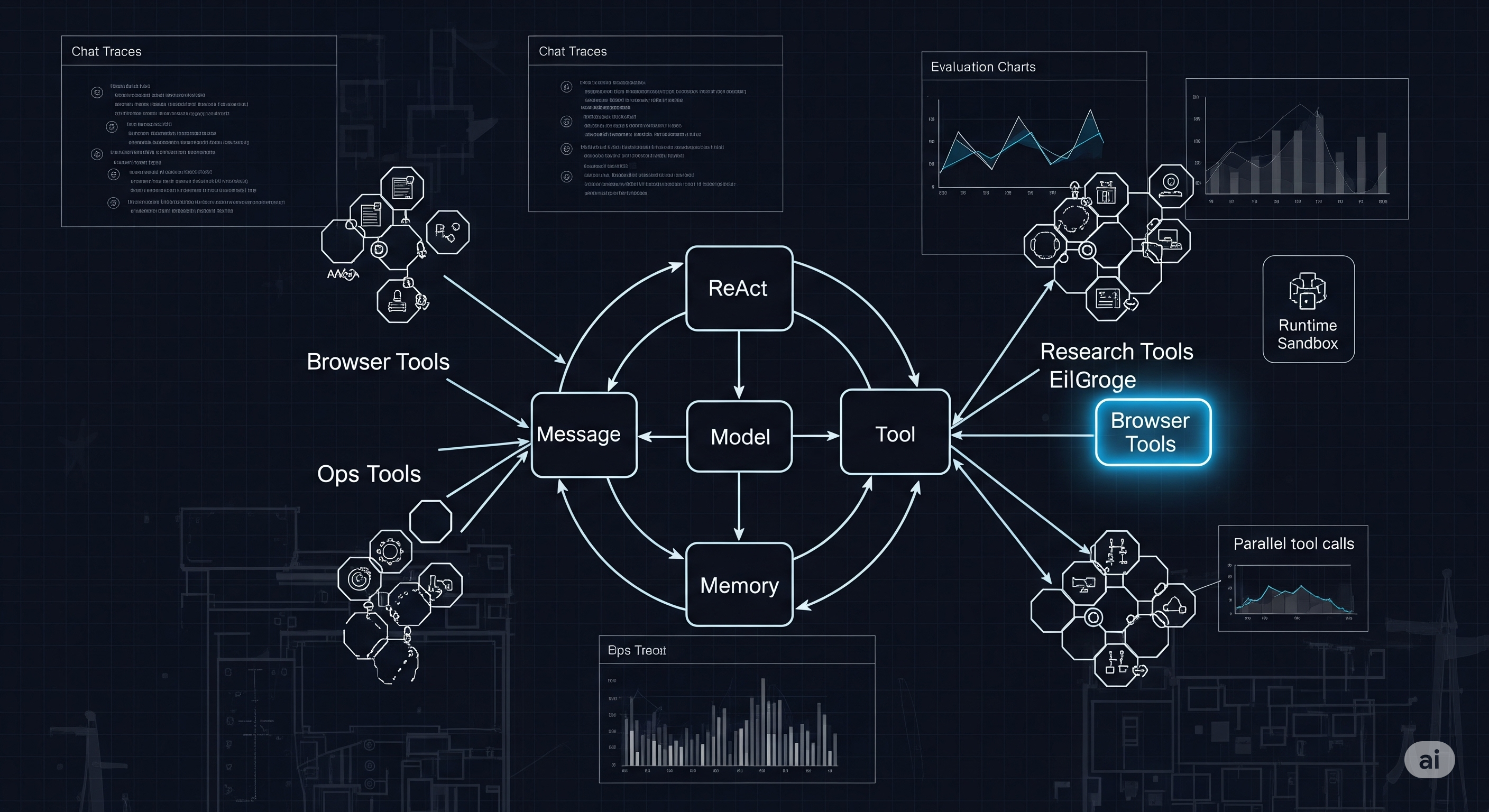
Thesis: AgentScope 1.0 is less a toolkit and more a discipline for agentic software. By pinning everything to ReAct loops, unifying “message–model–memory–tool,” and adding group-wise tool provisioning, it addresses the real failure mode of agents in production: tool sprawl without control. The evaluation/Studio/runtime trio then turns prototypes into shippable services. What’s actually new (and why it matters) 1) A crisp core: Message → Model → Memory → Tool Most frameworks blur these into ad‑hoc objects; AgentScope forces a clean, composable boundary: ...