TL;DR for operators
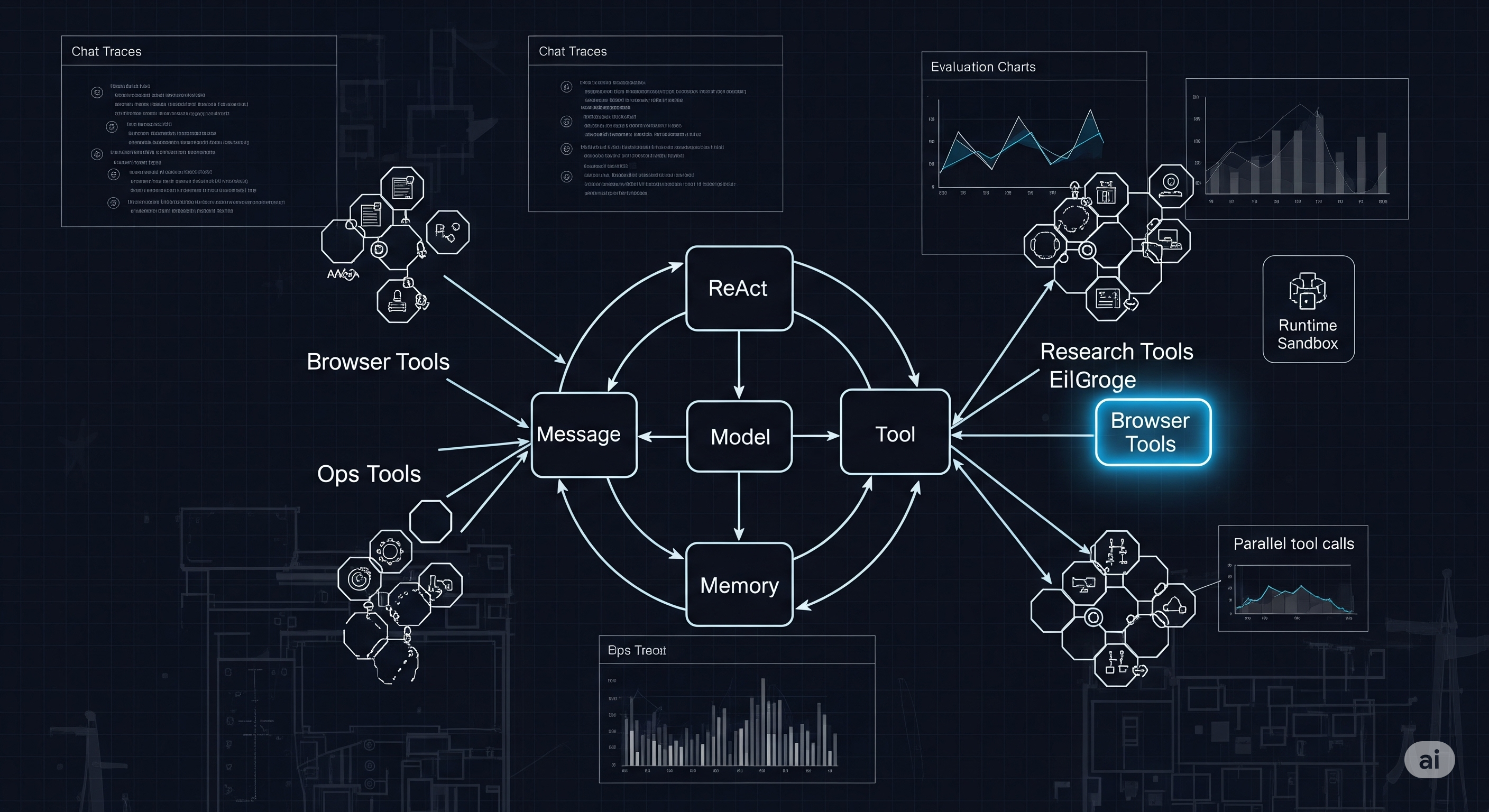
AgentScope 1.0 is best read as a production-shaping framework for agentic applications, not as a victory lap over rival agent frameworks. Alibaba’s paper describes a developer-centric stack that rebuilds agents around four core abstractions — message, model, memory, and tool — then places a ReAct-style reasoning-and-action loop on top of them.1
The useful idea is not simply “agents can call tools.” Everyone’s demo can do that, usually right before it calls the wrong function with confidence and a faint smell of burning infrastructure. The useful idea is that tool use needs governance: tools should be registered, grouped, activated selectively, traced, interrupted, evaluated, and run in isolated environments.
For business teams, the paper’s value is operational. AgentScope points toward a cleaner path for building internal research agents, browser automation agents, multi-agent workflows, and tool-heavy assistants across model providers and MCP servers. It may reduce integration friction and debugging pain. It does not prove lower total cost of ownership, better end-task accuracy, or stronger reliability than LangChain, AG2, custom orchestration, or a very disciplined in-house stack.
The paper’s evidence is architectural and demonstrative. It offers design descriptions, interfaces, built-in agents, and signature applications. It does not present a comparative benchmark table saying AgentScope beats alternatives by X%. That matters. The contribution is engineering coherence, not empirical dominance. Subtle distinction. Entire procurement meetings have died on less.
The real problem is not tool use. It is tool sprawl.
A modern agent demo usually begins innocently. Add a search tool. Add a calculator. Add a browser. Add a file system. Add a database connector. Add company APIs. Add memory. Add a planner. Add a second agent to watch the first agent. Add a dashboard because now nobody knows what happened.
At some point, the “agent” is no longer a reasoning system. It is a bag of endpoints held together by prompt glue and optimism. The model sees too many possible tools, the developer sees too little execution structure, and the operator sees only the final answer, which may or may not have been produced by a sensible path.
AgentScope 1.0 attacks that failure mode at the software layer. The paper’s central move is to stop treating agents as mysterious personalities and start treating them as applications with explicit components. Messages carry content. Model wrappers normalise provider differences. Memory stores context and trajectories. Tools are registered, described, executed, grouped, and observed. The ReAct loop then becomes a control pattern rather than a vibe.
That matters because ReAct itself is not a deployment strategy. A model that alternates thought, action, and observation can still fail in boring software ways: malformed tool arguments, blocked I/O, stale state, runaway loops, overstuffed context, missing telemetry, and unsafe execution environments. AgentScope’s paper is about those boring problems. Naturally, those are the ones that decide whether anyone outside the demo room can use the thing.
AgentScope turns the agent into a substrate, not a prompt
The framework begins with four foundational components: message, model, memory, and tool. This sounds like a taxonomy until one sees what it is trying to prevent: every downstream application inventing its own half-compatible representation of agent state.
The message abstraction is the basic unit of exchange. It can carry ordinary text, multimodal content, tool-use blocks, tool-result blocks, and reasoning-oriented blocks. It also includes traceability fields such as identifiers and timestamps. The operational point is simple: when agents interact with users, tools, memory, and other agents, the system needs one durable event format. Otherwise, debugging becomes archaeology.
The model abstraction handles a different form of mess: provider heterogeneity. OpenAI, Anthropic, Gemini, DashScope, Ollama, vLLM, and other model-serving paths do not expose identical formats for messages, tools, streaming, vision, reasoning traces, or usage accounting. AgentScope wraps them behind provider-specific formatters and a unified response schema. That schema can include text, tool-use blocks, thinking blocks, metadata, token usage, and processing time.
This is not glamorous. It is also precisely the kind of layer that prevents enterprise teams from hard-coding themselves into one vendor’s API shape and then pretending that switching models later will be “just an adapter.” Famous last words, usually delivered shortly before a sprint disappears.
Memory is split into short-term and long-term components. Short-term memory stores dialogue history and execution trajectories. Long-term memory is abstracted through a base interface with developer-controlled and agent-controlled methods. The developer can decide when to record or retrieve information. The agent can also be given tools that allow it to store or fetch memory during execution. The paper includes Mem0 as an example backend, but the more important point is the separation of control modes.
That separation matters in production. Some memory writes should be deterministic: session summaries, workflow checkpoints, audit-relevant facts. Others may be opportunistic: user preferences, recurring task context, hints discovered during a research process. Putting both behind one vague “memory” object is an excellent way to accumulate haunted state.
Then comes the tool abstraction. AgentScope’s Toolkit registers functions, generates JSON schemas, executes tools through a unified interface, handles synchronous and asynchronous functions, supports streaming outputs, and preserves partial output when interrupted. It also supports remote tools through MCP clients, with stateful and stateless connection patterns. Remote endpoints can be turned into local callable proxies, which developers can wrap, filter, or compose before exposing them to the agent.
The paper’s strongest design move appears here: group-wise tool management.
Group-wise tools are the quiet centre of the paper
Agents do not become smarter because they see more tools. Often they become worse. The paper explicitly discusses the “paradox of choice” in tool use: too many available tools can degrade selection quality, increase parameter errors, and waste context on irrelevant tool descriptions.
AgentScope’s answer is group-wise tool management. Developers can create tool groups and dynamically activate or deactivate them. A browser task can expose navigation, clicking, typing, and observation tools only when the agent is in a browser phase. A research task can expose search and extraction tools during information gathering, then deactivate them when synthesis begins. A finance agent could expose market-data tools during data collection, risk tools during validation, and report-generation tools at the end.
This is a small architectural move with large practical consequences. It converts tool access from a flat menu into a staged capability system.
| Mechanism | Operational consequence | Business relevance | Boundary |
|---|---|---|---|
| Tool registration through schemas | The model receives structured descriptions of available functions | Easier integration of internal APIs and MCP services | Schema quality still depends on developers |
| Unified execution interface | Sync, async, and streaming outputs can be handled consistently | Less bespoke glue code around tool calls | Does not guarantee correct tool choice |
| Graceful interruption handling | Partial outputs can be preserved when tasks are cancelled | Better behaviour for long-running workflows | Needs application-level recovery policy |
| Group-wise activation | The model sees only relevant tools for the current phase | Reduced tool-selection confusion and context waste | Requires upfront tool taxonomy design |
| Client-side MCP proxies | Remote services can be wrapped like local tools | Faster adaptation of external services to internal workflows | Remote service reliability remains external |
The important business lesson is not “use AgentScope.” It is “stop presenting the model with the entire company toolbox at every step.” Tool access should be contextual, auditable, and phase-aware. Otherwise, the agent is not empowered. It is being handed a warehouse and asked to find one screwdriver.
ReAct becomes useful when it has control points
AgentScope uses ReAct as its recommended agent architecture. In the paper’s formulation, the agent exposes three core functions: reply, observe, and handle interrupt.
The reply function runs the main reasoning-and-action loop. The agent receives a user query, reasons about the next step, calls tools when needed, observes results, and iterates until it can produce a final answer. The observe function lets the agent absorb external events or broadcast messages without necessarily replying. The interrupt handler lets external signals pause or redirect ongoing work.
That third piece is easy to overlook. It is also one of the most relevant for real systems.
Long-running agents are not like single-turn chatbots. They may be researching, browsing, coding, calling APIs, or coordinating with other agents when the user changes the objective. Without an interrupt model, the user’s options are crude: wait, kill the process, or send another message into a system that may not be listening. AgentScope treats interruption as part of the agent interface.
The paper also adds parallel tool calling and dynamic tool provisioning. Parallel tool calling addresses the latency problem in I/O-heavy workflows. If an agent needs several independent pieces of information, serialising every call is wasteful. Dynamic tool provisioning works with group-wise management, changing which tools are visible as the task changes.
The combined mechanism is stronger than the parts. ReAct supplies the loop. Tool grouping narrows the action space. Parallel execution reduces waiting. Interrupt handling keeps the user in control. State persistence prevents every interaction from becoming an amnesiac restart.
This is why the article should not be framed as “AgentScope adds ReAct.” That would undersell the paper. The more precise framing is: AgentScope tries to make ReAct operationally governable.
Built-in agents show the intended patterns, not universal proof
The paper includes several built-in agents: a Deep Research Agent, a Browser-use Agent, and a Meta Planner. These are best understood as reference patterns rather than benchmark-winning products.
The Deep Research Agent extends the base ReAct agent with research-oriented decomposition, search, reflection, summarisation, and memory. It can break questions into subtasks, search through connected services, identify knowledge gaps, and assemble reports. For business readers, this maps naturally to market research, technical due diligence, competitive scans, and internal knowledge synthesis.
The Browser-use Agent integrates browser automation tools, including Playwright MCP. It reasons over visual and textual webpage information, manages subtasks, handles long webpages through chunk-wise observation, and supports multi-tab workflows. This is relevant for workflows where APIs are unavailable, incomplete, or not worth integrating yet: form submissions, web monitoring, content collection, dashboard navigation, and ad hoc operational tasks.
The Meta Planner addresses more complex multi-step problems by generating a structured roadmap, decomposing work into subtasks, assigning worker agents, and tracking state. It can shift between lightweight ReAct handling and heavier planning-execution workflows depending on task complexity. The paper gives an example of a roadmap for analysing Meta stock, including company overview and financial metrics.
These examples demonstrate how AgentScope’s abstractions compose. They do not establish that these built-in agents outperform specialised systems, human analysts, or competing frameworks.
That distinction is important. A signature application in a framework paper is usually an implementation demonstration. It says, “The architecture can support this kind of workflow.” It does not say, “This is now the best way to do the workflow.” For some buyers, that difference is the gap between platform strategy and theatre.
The evaluation layer is about trajectory visibility, not magic scoring
AgentScope includes an evaluation module built around tasks, solutions, metrics, benchmarks, and evaluators. A task contains inputs, ground truth, metrics, and metadata. A solution output records whether execution succeeded, the final output, and the trajectory of tool calls and action results. Metrics can be categorical or numerical. Benchmarks aggregate tasks. Evaluators can support debugging-oriented sequential evaluation or more scalable distributed evaluation.
The design matters because agents are not ordinary prediction models. A final answer alone is often insufficient. Two agents may produce the same answer through very different paths: one by using the correct database, another by hallucinating and getting lucky. In regulated, financial, legal, or operational contexts, the path is part of the product.
AgentScope’s evaluation design therefore supports both outcome-based and process-based evaluation. That is the right direction. Long-trajectory agents need trajectory-aware evaluation because the failure often happens before the final response. A tool call may be unnecessary, unsafe, too slow, too expensive, or based on misunderstood state. A normal answer-level metric will miss that.
Studio extends this by visualising conversations, traces, tool invocations, action results, exceptions, latency spans, and evaluation distributions. It can link dialogue messages to underlying execution spans, helping developers move from “the answer was bad” to “the tool call diverged here.” The paper also describes evaluation visualisation through distributions, bootstrapped confidence intervals, per-item outcome grouping, and side-by-side trajectory comparison.
This is one of the more practically valuable sections of the paper. Not because dashboards are rare. Dashboards are so common that civilisation may now be 40% dashboards by weight. The value is the coupling of message-level interaction with execution-level spans and evaluation-level variation. Agent debugging needs all three.
Runtime and sandboxing are where prototypes meet consequences
The Runtime component aims to simplify deployment and execution management. The paper describes an engine abstraction with context and environment managers, support for multiple agent communication protocols including Google’s A2A protocol, and deployment examples using protocol adapters. It also describes sandbox support for isolated execution environments, including filesystem, browser, and training sandboxes.
This layer is where the paper’s production ambition becomes explicit. Tool-using agents often need to execute code, browse websites, read or write files, and interact with services. Those capabilities are useful. They are also exactly the capabilities one should not run casually inside a poorly isolated process because a prompt said “please proceed.”
The Sandbox provides a function-style interface while maintaining isolation and state where needed. The paper’s example shows code execution in a sandbox and persistence across calls. In practice, this matters for workflows such as data analysis, browser automation, report generation, benchmark execution, and code-running assistants.
The business interpretation is straightforward: deployment is not just “wrap the agent in FastAPI.” It requires execution boundaries, protocol choices, state management, and lifecycle control. AgentScope’s runtime stack is an attempt to package those concerns so developers can focus more on agent logic and less on infrastructure plumbing.
Still, sandboxing is not a full safety story. It is an execution-control mechanism. Enterprises still need access policies, data-governance rules, secrets management, approval gates, audit retention, red-team tests, and incident procedures. A sandbox prevents some classes of operational damage. It does not absolve the organisation of thinking. Tragic, but here we are.
What the paper directly shows versus what operators can infer
Because this is a framework paper, the evidence must be interpreted carefully. The paper contains architectural descriptions, interface designs, module explanations, code listings, visual workflow diagrams, and demonstration applications. It does not provide a head-to-head benchmark against LangChain, AG2, AutoGen-style systems, bespoke orchestration, or enterprise platforms.
That does not make the paper weak. It makes the type of contribution different.
| Paper artifact | Likely purpose | What it supports | What it does not prove |
|---|---|---|---|
| Message/model/memory/tool abstractions | Implementation detail and architectural foundation | AgentScope has a coherent substrate for composing agent applications | That the substrate is better than every alternative |
| ReAct workflow with reply/observe/interrupt | Main mechanism | Agent behaviour is organised around explicit interaction control points | That ReAct is optimal for all agent tasks |
| Parallel tool calling and dynamic tool provisioning | Efficiency and control mechanism | The framework can reduce serial waiting and tool overload in suitable workflows | Actual latency or accuracy improvement in deployed business settings |
| Built-in Deep Research, Browser-use, and Meta Planner agents | Exploratory extension and reference application | The core abstractions can support common agent patterns | Robustness across domains or superiority to specialist agents |
| Evaluation and Studio | Developer-experience and observability layer | Long trajectories can be scored, traced, visualised, and compared | That evaluation metrics will match business KPIs automatically |
| Runtime and Sandbox | Deployment and execution support | Agent applications can be run with more structured lifecycle and isolation controls | Complete enterprise-grade security or compliance readiness |
The strongest operator inference is that AgentScope can reduce engineering fragmentation. A team building internal agents often needs model adapters, message normalisation, memory, tool schemas, MCP integration, tracing, evaluation, and deployment wrappers. AgentScope places these in one framework. That could shorten the path from prototype to controlled pilot.
The weaker inference would be that AgentScope automatically delivers better agents. The paper does not show that. Better architecture makes better agents more feasible. It does not repeal the laws of task design, model weakness, data access, evaluation quality, or organisational chaos. Nobody gets that lucky.
Where businesses should actually apply the design
The clearest use case is not a consumer chatbot. It is the internal tool-using workflow where the organisation controls the tool environment and can define success criteria.
Research automation is the obvious candidate. A Deep Research-style agent can search, collect, summarise, store intermediate notes, and assemble reports. The framework’s tracing and evaluation layers make this more manageable than a loose script calling a model and a search API.
Browser automation is another candidate. Many business processes still live behind web interfaces that do not expose clean APIs. A Browser-use Agent can navigate, observe, click, type, and collect information. It will still need guardrails, human confirmation for sensitive actions, and robust failure handling. But the architecture is suited to iterative web tasks.
Multi-agent workflows are plausible when roles are genuinely distinct. AgentScope’s pipelines and message hub allow sequential, branching, looped, and broadcast-style agent interactions. That is useful for workflows such as draft-review-finalise, research-validate-summarise, or planner-worker-verifier structures. It is less useful when “multi-agent” simply means three prompts arguing theatrically over the same context window. A meeting with three hallucinating interns is still a meeting with interns.
Tool-heavy finance, legal, compliance, procurement, and operations assistants could also borrow the design pattern. The key is group-wise tool exposure. A finance agent should not see order execution tools while conducting background research. A compliance agent should not see remediation tools before classification is complete. A procurement assistant should not see vendor-writeback tools before quote validation. Phase-specific tooling is a governance primitive.
Adoption should start with control, not ambition
A sensible adoption path would not begin by deploying the Meta Planner into every business unit and hoping the org chart survives.
Start with the message schema. Normalise every user input, model output, tool call, tool result, error, and final response into an event format with IDs and timestamps. This creates replayability and auditability.
Then build tool groups. Do not register every available function and call that “flexibility.” Define task phases and expose only the tools needed for each phase. Give each group an owner, version, and test suite. Tool taxonomy drift is real: today’s “research tools” group becomes tomorrow’s junk drawer unless someone is accountable.
Next, add trajectory-aware evaluation. Evaluate not only whether the final answer looks acceptable, but whether the path was allowed, efficient, grounded, and recoverable. For business workflows, trajectory errors are often more important than final-answer elegance.
Only then move to runtime packaging and sandboxed execution. The reason is not conservatism. It is sequencing. Shipping an unobserved agent faster is not progress. It is merely a more efficient way to create incident reports.
The main limitation: this is architecture, not measured dominance
The paper does not quantify ROI. It does not show a controlled comparison proving that AgentScope reduces failure rates, latency, cost, or development time against other frameworks. It does not provide production incident data or enterprise adoption case studies. It does not settle whether its abstractions are the right ones for every domain.
It also inherits the usual agent problems. Tool schemas can be poor. Memory can become polluted. Model reasoning can fail. Browser automation can break when websites change. MCP servers can be unavailable. Evaluation benchmarks can be unrepresentative. Sandboxes can be misconfigured. Multi-agent workflows can add overhead without adding intelligence.
These limitations do not undermine the paper’s core contribution. They define its practical reading.
AgentScope 1.0 is not a proof that agents are ready for every business process. It is a structured answer to a narrower and more useful question: what software architecture makes tool-using agents less chaotic to build, observe, test, and deploy?
That is enough. In fact, it is more useful than another paper implying that one more prompt pattern will solve production AI. The prompt-pattern cupboard is full. The software-engineering shelf still has space.
Conclusion: ReAct needs an operating discipline
AgentScope 1.0’s most important contribution is not a single feature. It is the insistence that agentic applications need an operating discipline around ReAct.
The framework standardises the substrate through message, model, memory, and tool abstractions. It turns tool use into a managed capability system through registration, MCP integration, execution handling, and group-wise activation. It extends ReAct with interruption, parallel tool calls, dynamic provisioning, and state persistence. It adds developer-facing evaluation, Studio tracing, runtime deployment, and sandboxed execution. It packages built-in agents not as magic products, but as patterns for research, browser use, and planning-heavy tasks.
For operators, the lesson is direct: do not buy or build agents as personalities. Build them as systems. Define their messages. Limit their tools. Trace their actions. Evaluate their trajectories. Isolate their execution. Then, and only then, let them do useful work.
AgentScope 1.0 does not prove that this approach wins every benchmark. It shows what a serious agent framework has to care about when the demo ends and the tickets start arriving. Which, inconveniently, is where software begins.
Cognaptus: Automate the Present, Incubate the Future.
-
Dawei Gao et al., “AgentScope 1.0: A Developer-Centric Framework for Building Agentic Applications,” arXiv:2508.16279, 2025. https://arxiv.org/abs/2508.16279 ↩︎