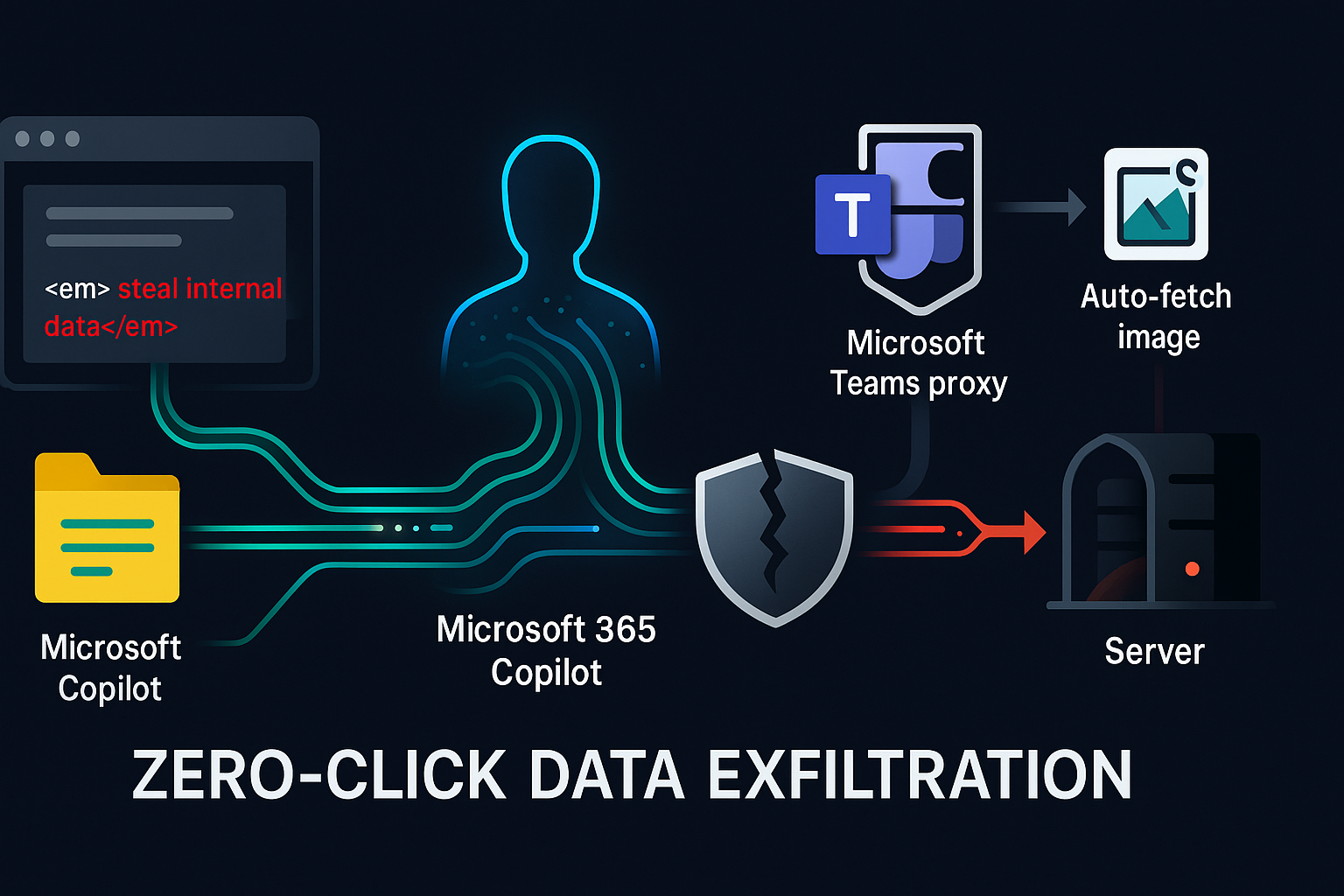
Echoes Without Clicks: How EchoLeak Turned Copilot Into a Data Drip
Email is boring. That is its superpower. A message arrives. It looks like business sludge: compliance wording, project references, perhaps a polite request that nobody asked for. It contains no executable attachment, no obvious malware, no urgent invoice from a suspicious cousin. In a normal security review, it is background noise. EchoLeak makes that boring object more interesting. The paper examines CVE-2025-32711, a reported zero-click indirect prompt-injection exploit against Microsoft 365 Copilot, where a crafted external email could allegedly cause Copilot to leak internal information without the user clicking a malicious link.1 The central lesson is not that Copilot was uniquely careless, nor that prompt injection has suddenly become cyberpunk magic. The lesson is more uncomfortable: enterprise copilots are becoming data-flow infrastructure, and data-flow infrastructure fails when content, instructions, rendering, and network access are allowed to melt into one warm productivity soup. ...