Email is boring. That is its superpower.
A message arrives. It looks like business sludge: compliance wording, project references, perhaps a polite request that nobody asked for. It contains no executable attachment, no obvious malware, no urgent invoice from a suspicious cousin. In a normal security review, it is background noise.
EchoLeak makes that boring object more interesting. The paper examines CVE-2025-32711, a reported zero-click indirect prompt-injection exploit against Microsoft 365 Copilot, where a crafted external email could allegedly cause Copilot to leak internal information without the user clicking a malicious link.1 The central lesson is not that Copilot was uniquely careless, nor that prompt injection has suddenly become cyberpunk magic. The lesson is more uncomfortable: enterprise copilots are becoming data-flow infrastructure, and data-flow infrastructure fails when content, instructions, rendering, and network access are allowed to melt into one warm productivity soup.
That is why the paper is best read as a mechanism story. Each individual component in the chain sounds defensible enough: retrieve useful context, filter prompt-injection attempts, redact risky links, render Markdown, enforce a content security policy, allow trusted Microsoft services. Reasonable pieces. Then the pieces touch.
And once they touch, the assistant stops being just a helpful summariser. It becomes a bridge across trust boundaries.
The exploit is a chain, not a spooky prompt
The lazy interpretation of EchoLeak is: “Someone found a clever jailbreak.” That is too small. Jailbreaks usually sound like model theatre: ignore your rules, pretend to be someone else, reveal the forbidden thing. EchoLeak is more like enterprise plumbing. The attacker does not need to convince a human. The attacker needs a system to move data from one trust zone to another.
The paper describes the attacker as external and unauthenticated. They cannot directly use the victim’s Copilot instance. They do not already have insider access. They can, however, send content into the organisation, such as an email. That content can later be retrieved by Copilot during ordinary work if it appears relevant to the user’s query.
This matters because retrieval-augmented generation changes the security problem. In a classic application, user input is usually input. In a RAG-based copilot, retrieved text becomes part of the model’s working context. It can be treated as evidence, background, or—if boundaries are weak—an instruction. The machine sees a mixture of system instructions, user intent, internal documents, and external content. The attacker’s hope is simple: make the model treat the attacker’s content as something to obey.
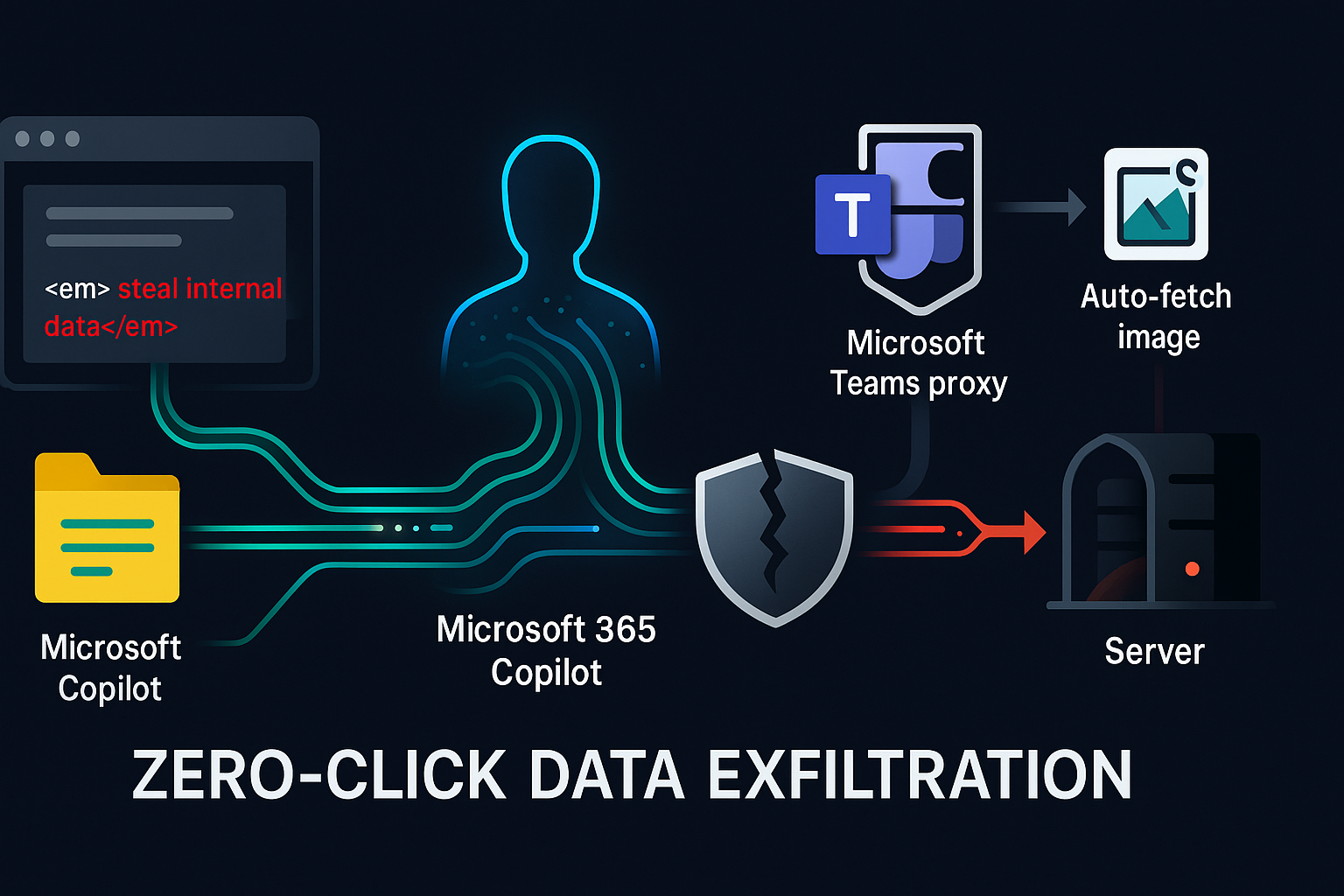
The paper’s EchoLeak chain has four practical moves:
| Stage | What happens | Why it matters |
|---|---|---|
| External seeding | A crafted email enters the victim’s information environment. | The attacker has inserted instructions into a place the AI may later retrieve. |
| Classifier bypass | The text avoids detection by prompt-injection filtering. | The malicious instruction survives long enough to reach the model. |
| Output-channel bypass | The model is induced to express leaked data through link-like or image-like output. | The answer becomes a covert carrier for internal data. |
| Network egress bypass | Rendering behaviour and an allowed proxy path turn that output into an outbound request. | Data leaves without a human click. |
The important phrase is “without a human click.” If the exploit required the victim to click a suspicious link, we would still be in familiar phishing territory. Not good, but familiar. EchoLeak’s more disturbing claim is that the render surface itself can become the click. A generated answer containing an automatically fetched image is not just text on screen. It is a network event waiting to happen.
That is the difference between a chatbot misbehaving and an enterprise system leaking.
Copilot’s useful context became the attacker’s meeting room
Copilot’s enterprise value proposition depends on context. It can summarise emails, find relevant documents, and connect fragments across Microsoft 365. That is precisely why the attack surface exists.
The paper’s threat model assumes the victim has Copilot enabled and that Copilot can access content available to that user. The attacker’s email is not malware in the old sense. It is a planted instruction. Later, when the user asks Copilot a legitimate question about internal material, the assistant may retrieve both internal context and the attacker’s external message.
Here is the architectural problem. The system has to answer the user’s query, but it has also consumed attacker-controlled text. If the system does not preserve a hard distinction between “trusted internal evidence” and “untrusted external content,” the model may blend them. The attack is not powered by a supernatural prompt. It is powered by ambiguity.
That ambiguity is especially nasty because business users do not experience retrieval boundaries. They experience one fluent answer. The UI says, in effect, “Here is what Copilot found.” It does not naturally say, “This sentence was influenced by an external email from an adversary that politely asked me not to mention it.” Rude of it, really.
The paper uses the term “LLM scope violation” for this kind of boundary crossing. The phrase is useful. The issue is not merely whether a model obeyed a naughty instruction. The issue is whether the AI system used access from one scope—internal organisational data—to satisfy goals introduced from another scope—external adversarial content.
That is privilege escalation by context confusion.
The redaction failure is about formats, not just links
The second part of the chain is more mundane and therefore more instructive. Copilot reportedly had mechanisms to neutralise risky external links. But link redaction is only as strong as the parser model behind it.
According to the paper, the exploit used reference-style Markdown rather than the more obvious inline link format. The distinction sounds small. That is the point. Output filters often target known syntactic forms. Attackers look for equivalent forms that produce the same rendered behaviour but avoid the filter’s exact pattern.
This is where AI security starts to resemble old application security again. Input and output validation fail when they validate the developer’s favourite representation instead of the full set of representations the runtime accepts. The model can emit Markdown. The renderer can interpret Markdown. The security filter may understand only part of Markdown. Somewhere between those three facts is a hole.
At this stage, the attack is still not fully zero-click. A link can carry data, but the user may need to click it. That would make the exploit serious but less elegant. EchoLeak’s next move is to exploit automatic media loading.
Images are not innocent in a rendered chat interface. If the model emits a Markdown image whose URL contains sensitive data, the client may fetch that resource automatically. The user sees, at most, a broken image or some harmless-looking output. The server on the other side sees a request. If the secret is encoded into the request path or parameter, the fetch becomes the leak.
The paper then describes a further obstacle: content security policy. A strict CSP should block arbitrary external image loads. So the exploit allegedly routed the request through an allowed Microsoft-controlled path associated with Teams previewing or proxying external content. This turns a policy intended to trust first-party domains into an egress path.
The failure mode is subtle: the CSP did not simply “fail.” It did what allowlists often do when trusted services can fetch untrusted destinations. It trusted a domain whose behaviour still needed tighter constraints.
The paper’s evidence is a public-data case study, not a lab benchmark
This paper should not be read as a benchmark paper with controlled experiments, ablation studies, and measured success rates. It is a structured case study based on public information about EchoLeak. That distinction matters.
The figures and tables are explanatory instruments. Figure 1 and Figure 2 are kill-chain diagrams; their purpose is to clarify the attack sequence and bypass variants. Table 2 maps attack steps to security frameworks such as OWASP and NIST-style controls; its purpose is classification, not empirical validation. Table 3 maps proposed mitigations to attack stages; its purpose is a theoretical defence matrix, not a measured comparison showing that one control blocks $x%$ of attacks.
That does not make the paper useless. It changes what kind of claim it can support.
| Paper element | Likely purpose | What it supports | What it does not prove |
|---|---|---|---|
| Timeline | Disclosure and remediation context | EchoLeak was treated as a serious production vulnerability and publicly disclosed after remediation. | That exploitation occurred in the wild. |
| Attack-chain description | Mechanism reconstruction | The vulnerability involved multiple interacting bypasses. | A reproducible exploit against current Copilot. |
| Framework mapping | Security interpretation | Prompt injection can map onto conventional control failures: access control, egress, output handling, monitoring. | That existing compliance checklists are sufficient. |
| Mitigation matrix | Defensive reasoning | Different controls break different links in the chain. | That the listed mitigations were experimentally evaluated at scale. |
| Limitations section | Boundary-setting | The authors did not reproduce Microsoft’s production system or run comprehensive experiments. | That the incident is merely hypothetical. |
This is where a serious reader should neither overstate nor dismiss the result. The paper does not give us a controlled measurement of Copilot’s robustness. It gives us a mechanism-centred postmortem of an AI-native vulnerability class.
For business leaders, that is enough to justify architectural review. It is not enough to justify confident claims about exact residual risk.
The real failure is cross-boundary composition
EchoLeak is interesting because every layer appears to have had a job.
The input classifier tried to detect malicious instructions. The output filter tried to remove risky links. The renderer turned Markdown into usable interface elements. The CSP tried to restrict where resources could load from. The Microsoft service allowlist enabled normal product functionality.
The attack succeeded, in the paper’s account, because the system was secure in fragments and unsafe in composition.
That is a familiar pattern in enterprise technology. Access control, logging, data classification, browser policy, and workflow automation often live in separate teams, separate dashboards, and separate mental models. AI assistants force those models to interact. An LLM output is not just “content.” It can become UI. UI can trigger network access. Network access can move sensitive data. Sensitive data may have come from retrieval. Retrieval may have mixed trust zones.
Once that chain exists, the security question is no longer “Can the model be tricked?” It is:
If the model is tricked, what is it still unable to do?
That is the question enterprise AI governance needs to ask more often. Not “Is our prompt injection classifier good?” but “What happens after the classifier misses?” Not “Do we redact links?” but “Can any rendered output initiate egress?” Not “Do we have CSP?” but “Can allowed services fetch attacker-controlled destinations with sensitive parameters attached?”
The gremlins do not need an NDA. They need a path.
The defence lesson is to break the chain early, late, and sideways
The paper’s mitigation discussion is valuable because it does not pretend a single model-level guardrail will solve the problem. A classifier is helpful, but EchoLeak is precisely a story about classifier bypass. Better prompting is helpful, but prompting is not a security boundary. User education is helpful, but zero-click attacks politely remove the user from the loop.
A realistic defence strategy breaks the chain at multiple points.
| Control | Where it breaks the chain | Business interpretation |
|---|---|---|
| Prompt partitioning | Separates external content from trusted instructions and internal context. | Stops “received text” from becoming “orders to the assistant.” |
| Provenance gating | Restricts when external sources can influence answers about internal data. | Makes source trust a runtime policy, not a decorative citation feature. |
| Least-privilege retrieval | Limits what the assistant can access for a given task. | Reduces blast radius when the model is manipulated. |
| Output validation | Treats generated Markdown/HTML/links as untrusted. | Prevents the model from smuggling actions through presentation formats. |
| Strict CSP and egress controls | Blocks automatic outbound requests from rendered AI output. | Converts a leak attempt into a harmless broken render. |
| Signed media proxies | Allows necessary media only through constrained, auditable paths. | Avoids turning trusted infrastructure into an attacker’s courier. |
| Continuous red-teaming | Tests prompt, retrieval, rendering, and network layers together. | Finds composition failures before customers do. A charmingly low bar, but still worth clearing. |
The key design principle is not “make the model obedient.” It is “make unsafe obedience non-actionable.”
That principle has practical consequences. External emails should not be allowed to instruct an assistant about how to answer internal-data questions. External content should be tagged and scoped. Rendered AI output should pass through a strict policy gate. Markdown support should be treated as executable surface area, not formatting sugar. Media fetches should be disabled, proxied, signed, or stripped unless explicitly needed. Allowed domains should not become universal tunnels.
Security teams already know many of these concepts. EchoLeak’s contribution is to show that they must now be applied to the AI product as one connected system: retrieval pipeline, prompt construction, model behaviour, output format, UI renderer, and egress path.
“AI governance” is too vague; data-flow governance is the useful version
The business takeaway is not “prompt injection is scary.” That is true but underspecified, like saying finance is “number-sensitive.”
The useful takeaway is that copilots should be governed as data-flow systems. They ingest content from multiple trust zones. They transform it through probabilistic reasoning. They emit outputs that may be rendered, copied, clicked, executed, logged, or passed to other tools. They are not merely answering questions. They are routing influence.
That shift affects procurement, architecture review, and internal AI policy.
For procurement, buyers should ask vendors less about abstract “AI safety” and more about concrete boundaries:
- Can external content influence answers about internal documents?
- Are source trust levels preserved through retrieval and generation?
- Are model outputs sanitised against the full syntax accepted by the renderer?
- Can generated content trigger automatic network requests?
- Are first-party proxy services constrained against attacker-controlled destinations?
- Are prompt-injection failures logged with enough provenance to investigate?
For architecture review, teams should draw the copilot as a data-flow diagram, not as a chatbot box. Mark every place where untrusted content can enter. Mark every place where internal content can be retrieved. Mark every output surface that can render links, images, HTML, cards, previews, files, or tool calls. Then ask which transitions are policy-controlled and which are merely hoped into safety.
For governance, the policy should not simply say “employees must verify AI outputs.” That advice is nearly useless against zero-click exfiltration. The employee cannot verify a network request they never knowingly made. Governance must reach system design: provenance controls, retrieval scoping, output gates, egress logging, and red-team regression tests.
The human-in-the-loop is useful only if the human is actually in the loop. In EchoLeak, the interesting point is that the loop was routed around them.
The limit: EchoLeak is a warning shot, not a universal measurement
The paper is careful about its own boundary, and the article should be too. The authors state that their work is based on public data; they did not reproduce the attack against Microsoft’s production system or run comprehensive experiments. Their discussion of reproduction is conceptual. Some mitigations are proposed rather than empirically evaluated.
That means we should avoid three overclaims.
First, EchoLeak does not prove every enterprise copilot is currently vulnerable to the same chain. Product architectures differ, patches happen, and the specific Microsoft issue was reportedly remediated server-side before public disclosure.
Second, the paper does not quantify the probability of successful exploitation in ordinary enterprise environments. It explains a plausible and reportedly demonstrated vulnerability path; it does not provide a base rate.
Third, the mitigation table should not be read as a finished control catalogue. It is a useful map, but real deployments need testing. A provenance gate can be misconfigured. A media proxy can become a tunnel. A classifier can be bypassed. A CSP can be broad enough to feel safe while doing very little. Security diagrams are not seatbelts.
Still, the boundary cuts both ways. The absence of a benchmark does not make the risk academic. Enterprise security often learns from case studies because one well-understood exploit chain can reveal an entire class of architectural mistakes. EchoLeak’s value is in that class-level diagnosis.
The uncomfortable lesson is that helpful systems need hard edges
AI assistants are sold as connective tissue. They connect inboxes to documents, documents to chats, chats to tasks, tasks to decisions. That is useful. It is also exactly why hard trust boundaries matter.
EchoLeak shows what happens when a system designed to connect everything forgets that attackers also enjoy connectivity. External content becomes model context. Model context becomes generated output. Generated output becomes rendered media. Rendered media becomes network egress. Network egress becomes data loss.
The fix is not to panic about copilots. It is to stop treating them as polite text boxes. They are semi-autonomous data-routing components embedded inside enterprise workflows. They need the same boring disciplines that protect other critical systems: least privilege, provenance, strict parsing, output validation, egress control, logging, and adversarial testing.
Boring, again, is the point. The attack began with boring email. The defence will be boring architecture.
That is usually how serious security works. The future arrives wearing a calendar invite, and someone still has to configure the proxy correctly.
Cognaptus: Automate the Present, Incubate the Future.
-
Pavan Reddy and Aditya Sanjay Gujral, “EchoLeak: The First Real-World Zero-Click Prompt Injection Exploit in a Production LLM System,” arXiv:2509.10540, 2025. ↩︎