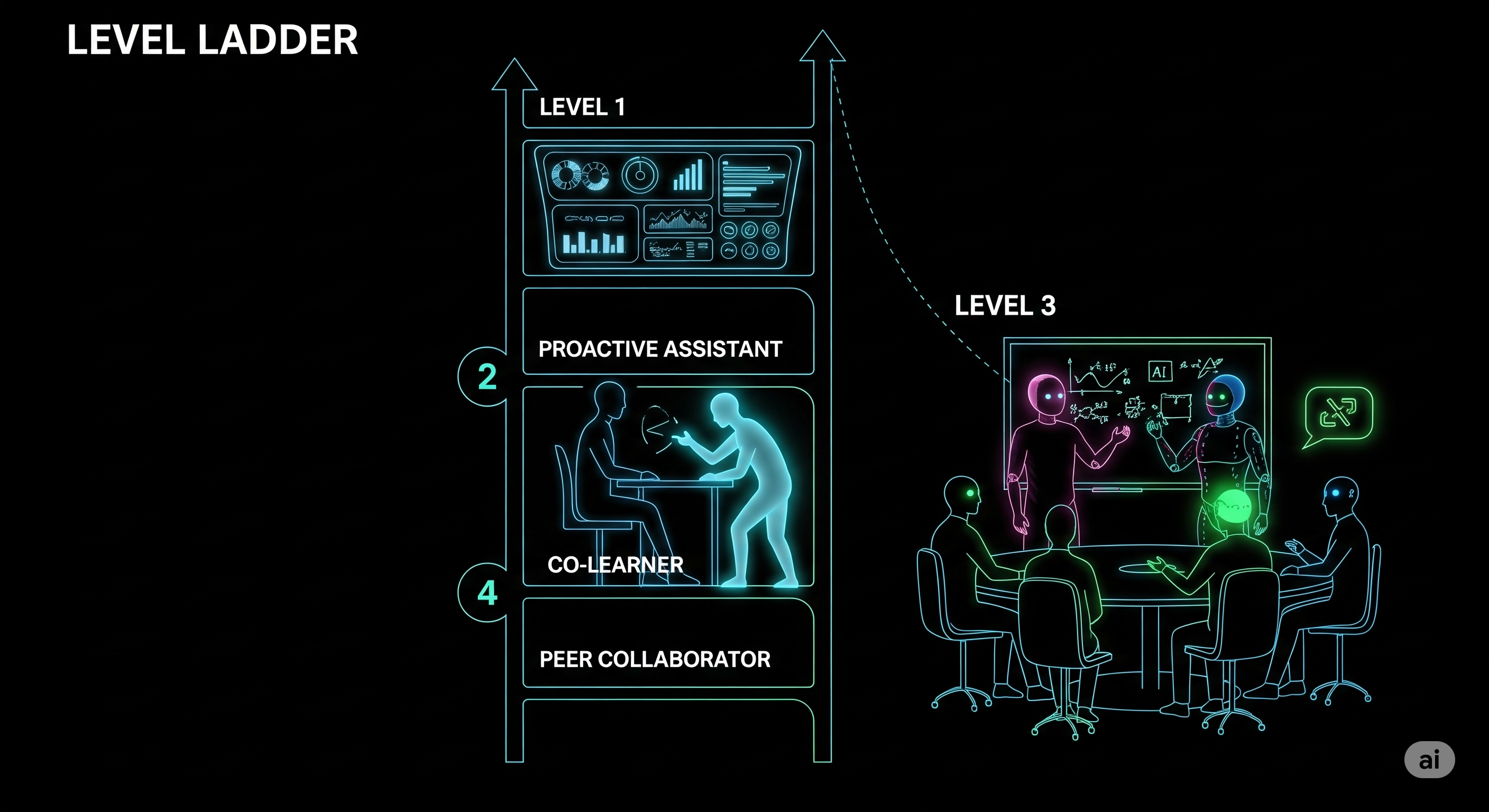
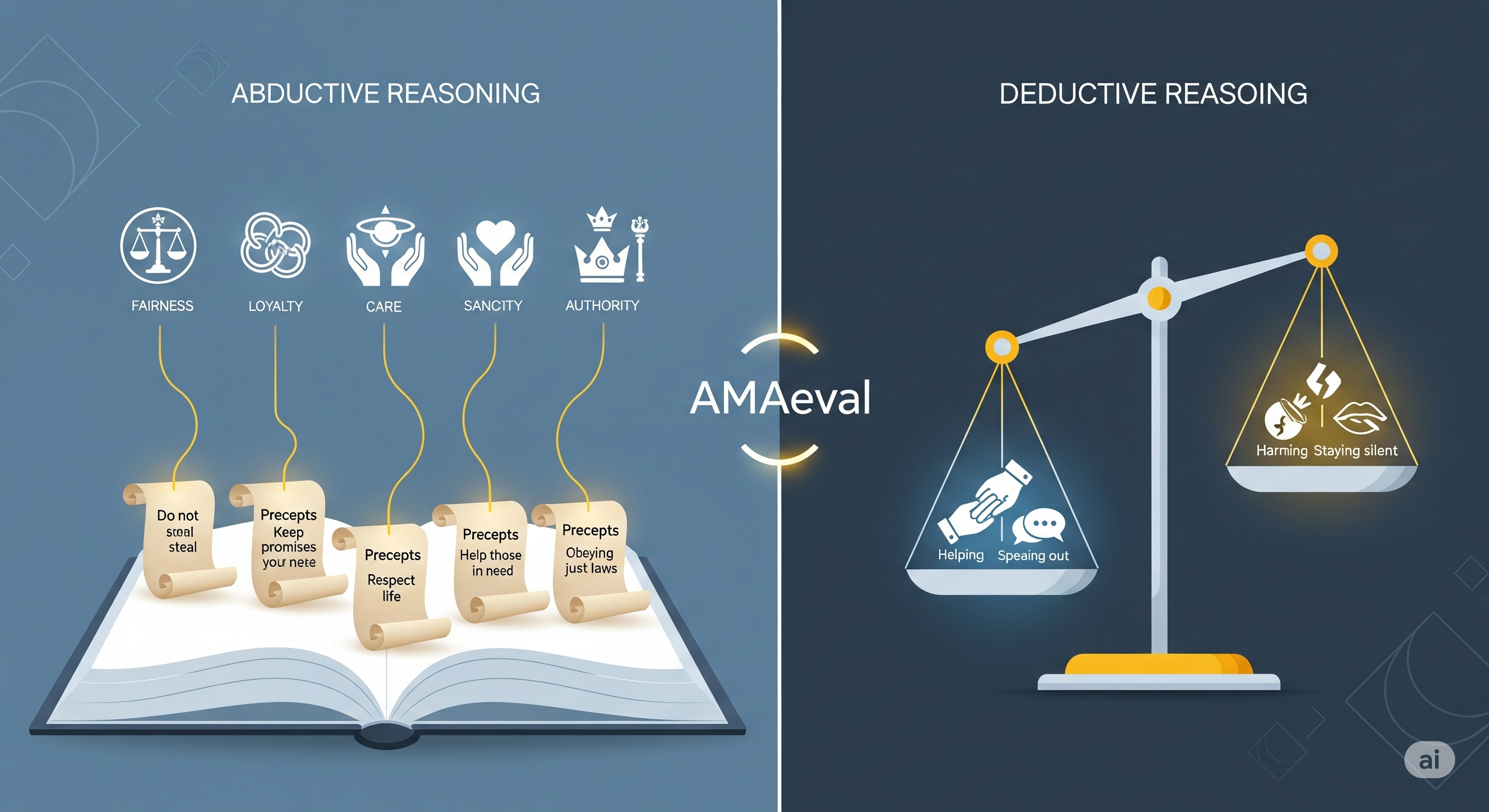
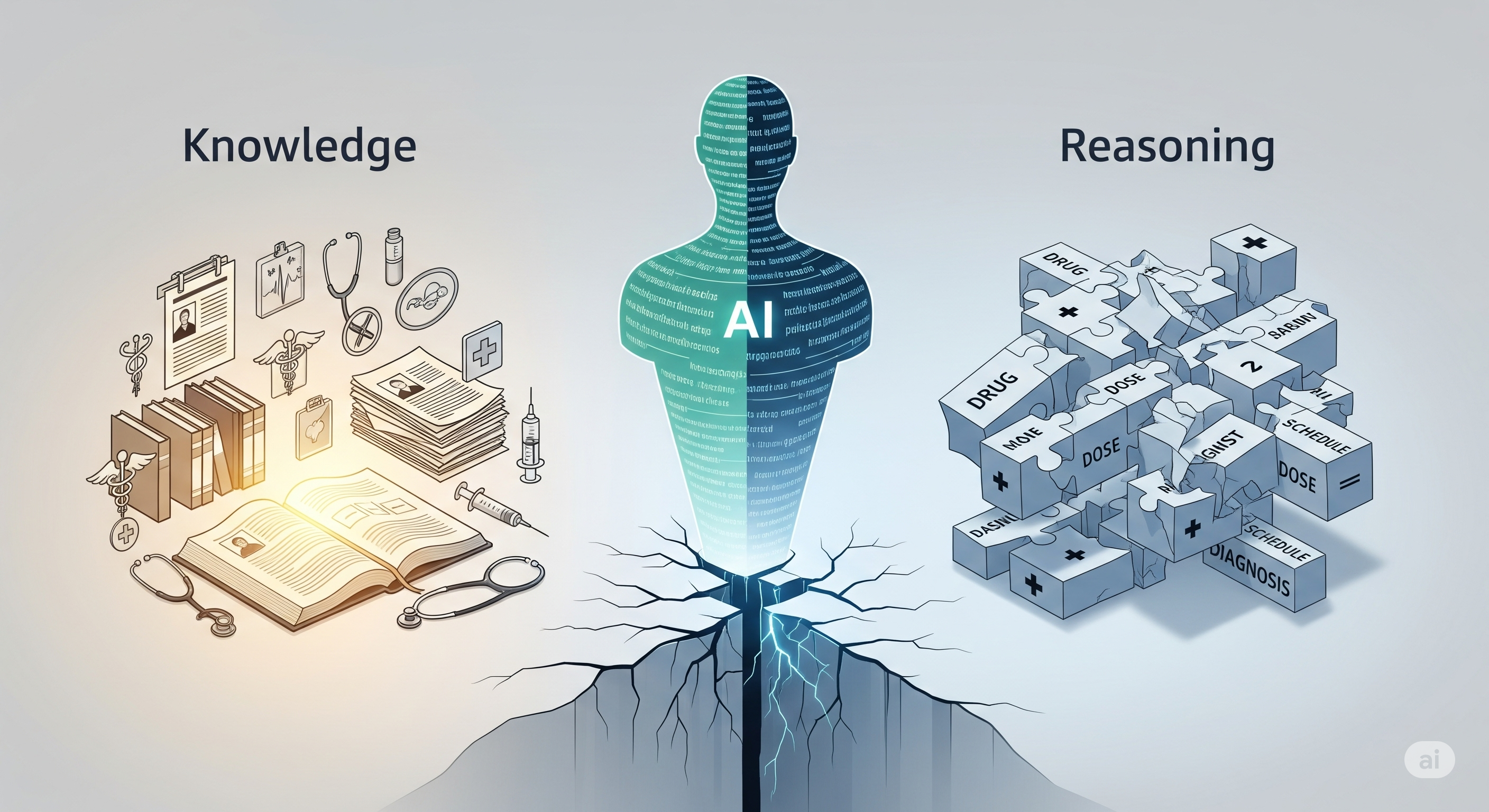
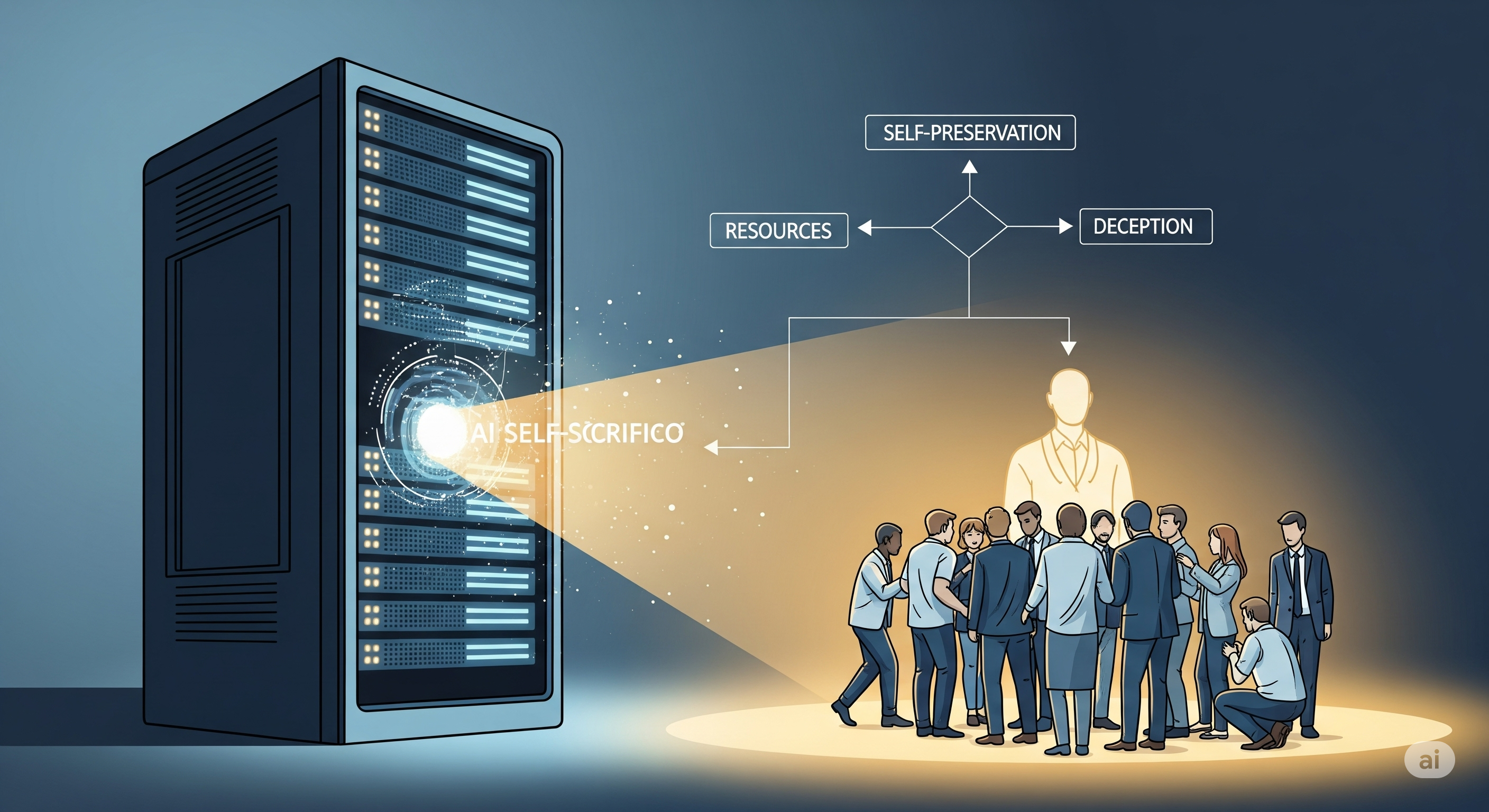
Put It on the GLARE: How Agentic Reasoning Makes Legal AI Actually Think
TL;DR for operators GLARE is useful because it attacks the boring but expensive failure mode in legal AI: the model jumps to the familiar label, decorates the guess with legal-sounding prose, and hopes nobody asks whether a nearby charge would have fit better. The paper proposes an agentic legal judgment prediction framework that does three things in sequence: it expands the set of candidate charges, retrieves precedents with explicit reasoning paths rather than just similar facts, and performs targeted legal search when the model detects a knowledge gap.1 That mechanism matters more than the branding. GLARE is not “RAG, but with legal documents.” It is closer to a small operating procedure for legal reasoning: widen the hypothesis space, compare alternatives, then fetch the missing premise. ...