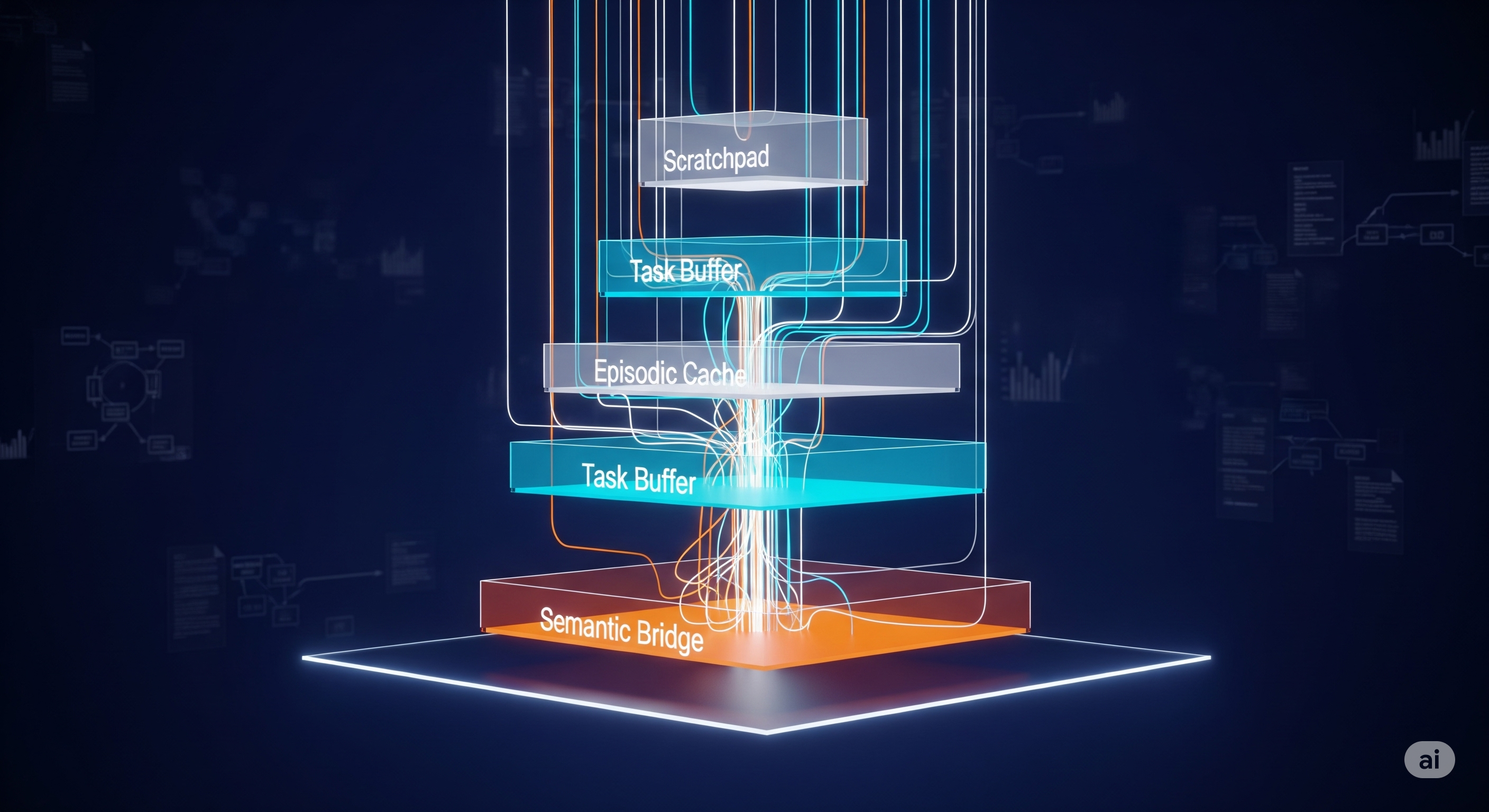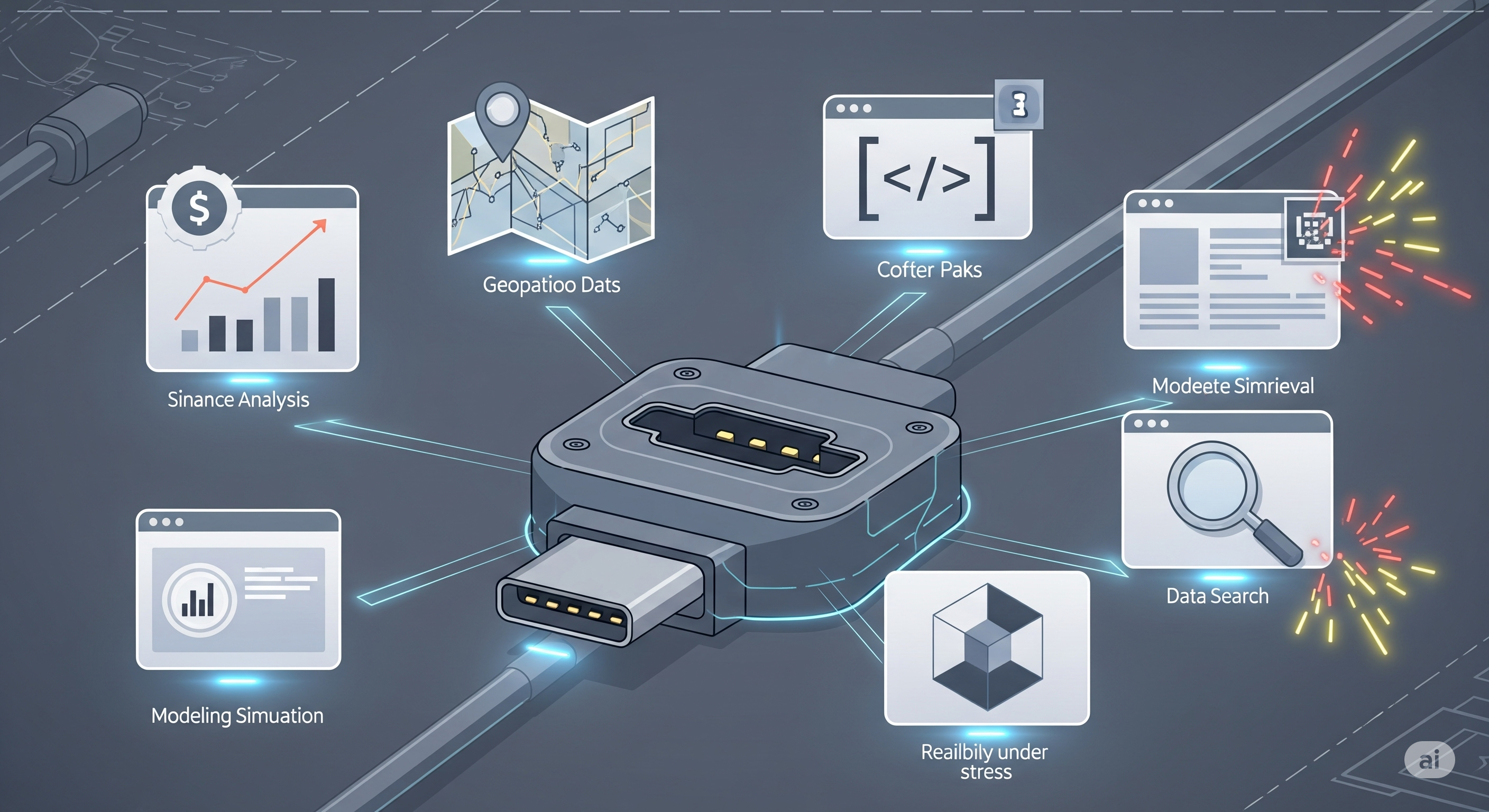
USB‑C for Agents, Stress‑Tested: What MCP‑Universe Really Reveals
The pitch: a unified plug—and a tougher test The Model Context Protocol (MCP) is often described as the “USB‑C of AI tools”: one standardized way for agents to talk to external services (maps, finance data, browsers, repos, etc.). MCP‑Universe, a new benchmark from Salesforce AI Research, finally stress‑tests that idea with real MCP servers rather than toy mocks. It derives success from execution outcomes, not multiple‑choice guesswork—exactly what enterprises need to trust automation. ...