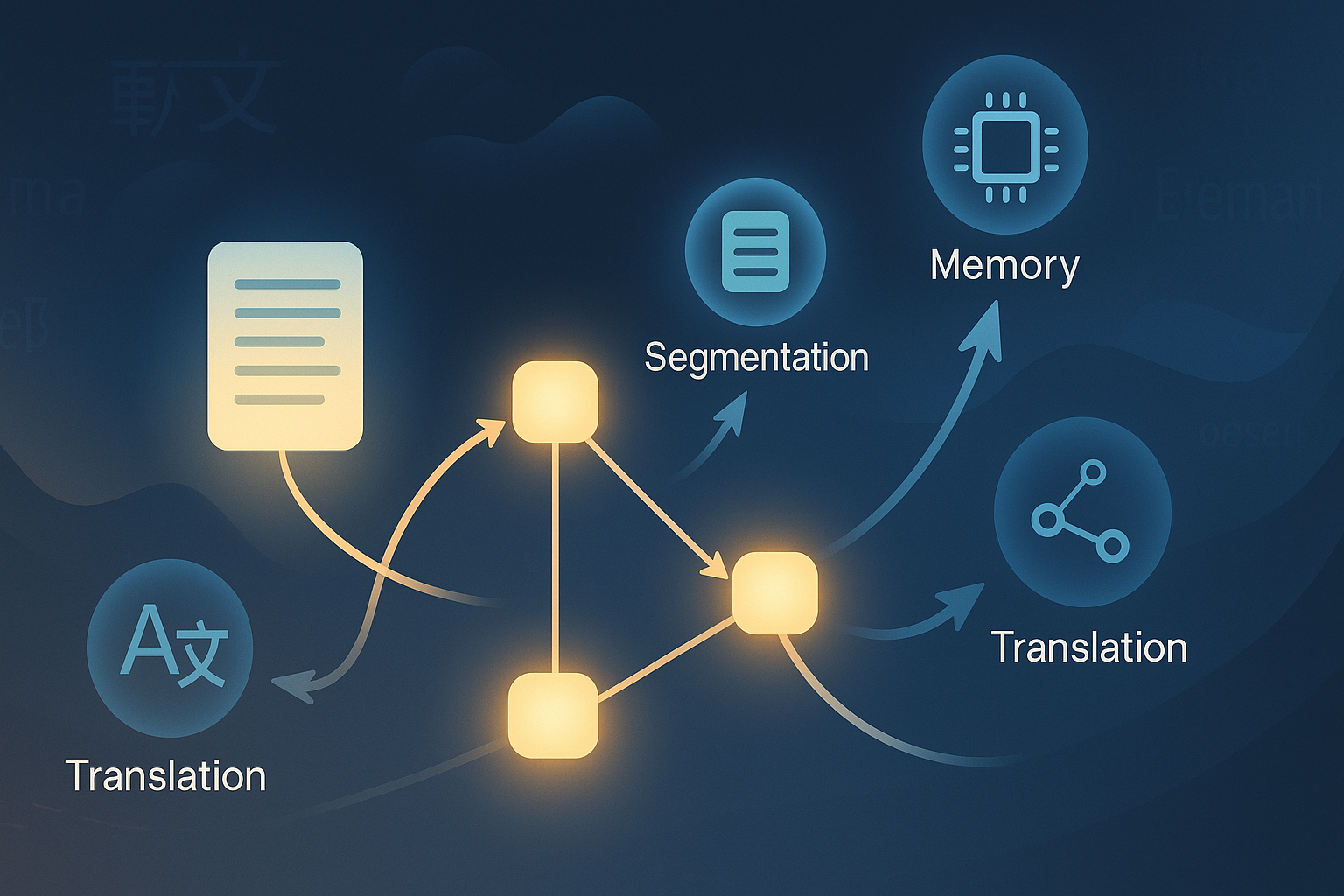
Threading the Needle: How GRAFT Reinvents Document Translation with DAGs and LLM Agents
Document-level machine translation (DocMT) has long been riddled with a paradox: while LLMs can translate fluent paragraphs and even simulate discourse, they often falter at stitching meaning across paragraphs. Pronouns go adrift, tenses waver, and terminology mutates like a broken telephone game. The new paper GRAFT: A Graph-based Flow-aware Agentic Framework for Document-level Machine Translation proposes an ambitious fix: treat a document not as a sequence, but as a graph — and deploy a team of LLM agents to navigate it. ...