TL;DR for operators
Long-document translation does not fail only because the model lacks enough tokens. It fails because documents are not bags of sentences. They contain references, implied pronouns, repeated terms, topic shifts, callbacks, causal links, and the occasional sentence that makes sense only because something three paragraphs earlier did the heavy lifting.
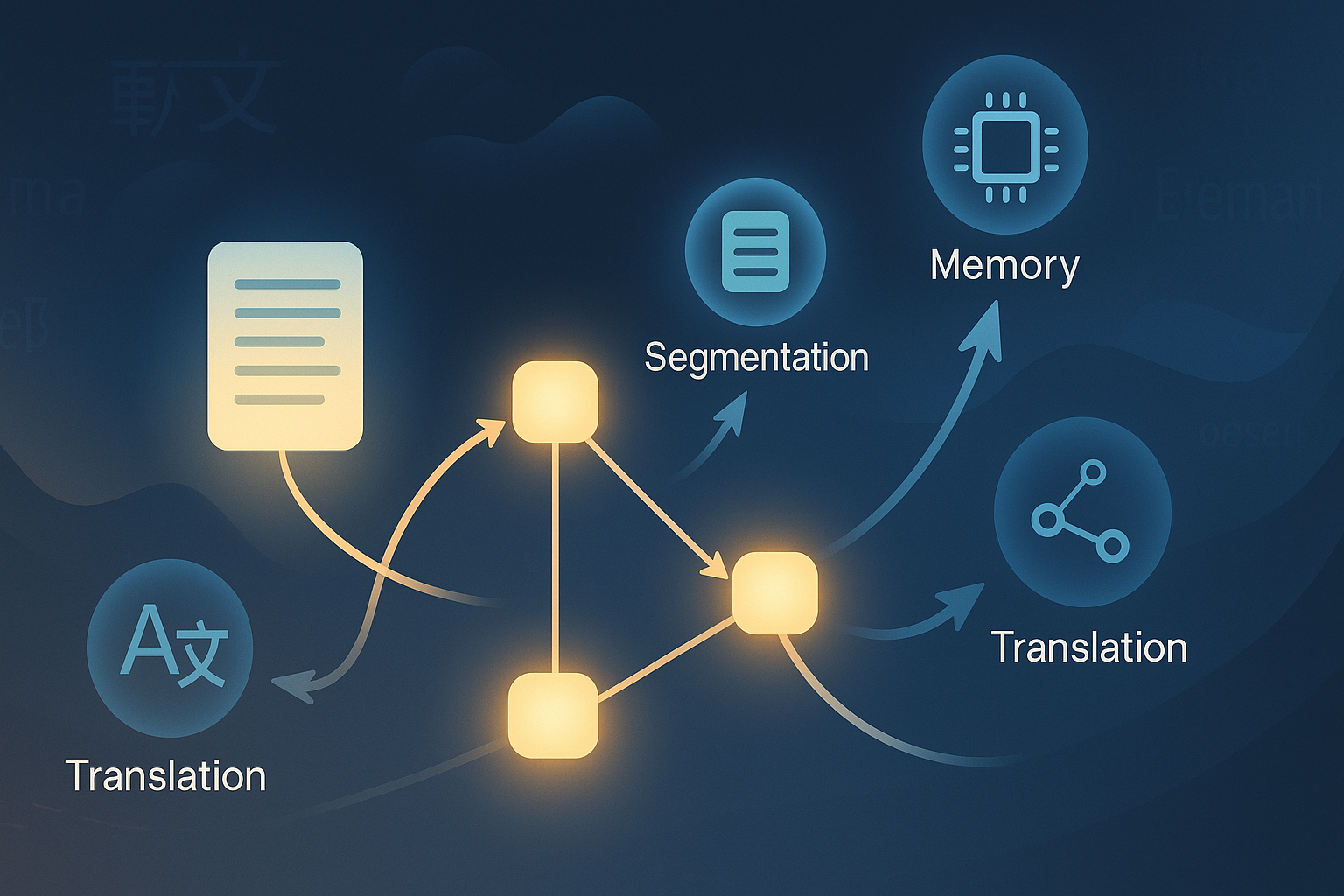
GRAFT attacks that problem by turning a document into a graph before translating it. A Discourse Agent breaks the source into translation-sized discourse units. An Edge Agent connects units that depend on one another. A Memory Agent extracts structured information from translated units. A Translation Agent then translates each unit using the relevant upstream memory rather than the whole document indiscriminately.
The paper’s useful lesson is not “agents are magic”. Mercifully. It is that structure matters. LLM-based discourse segmentation averages 25.9 d-BLEU across eight TED translation directions, compared with 22.3 for semantic chunking and 14.5 for random segmentation. LLM-based edge modelling averages 25.9 d-BLEU, compared with 23.9 for a chain graph and 23.8 for TF-IDF edges. The mechanism, not the branding, carries the argument.
For business use, GRAFT is most relevant where inconsistency is expensive: technical documentation, regulatory translation, legal material, product localisation, multilingual support knowledge bases, research reports, and literary translation. The catch is equally practical. The authors report roughly three times the latency of GPT-4o-mini and an estimated cost of $0.12 per 1,000 words, compared with $0.08 for GPT-4o-mini and $0.05 for GPT-3.5-Turbo. Better threading, higher bill. Astonishingly, vendors sometimes omit that sentence.
The familiar failure: the translation is fluent, and still wrong
Anyone who has reviewed a machine-translated manual, contract, or product guide has seen the modern failure mode. The translation reads smoothly. The sentences are grammatical. The paragraphs look professional enough to survive a quick skim.
Then the same term appears three different ways. A pronoun points to the wrong entity. A section heading changes the implied scope of the following paragraph. A Chinese zero pronoun becomes an English “he”, “she”, or “it” by what appears to be divine lottery. The result is not comic mistranslation. It is worse: polished ambiguity.
That is the problem behind GRAFT, short for Graph-Augmented Agentic Framework for Document-Level Translation, proposed by Himanshu Dutta, Sunny Manchanda, Prakhar Bapat, Meva Ram Gurjar, and Pushpak Bhattacharyya.1 The paper is about document-level machine translation, but its broader point applies to many enterprise AI workflows: when the task depends on relationships inside a long artefact, dumping the whole artefact into a large context window is often a blunt instrument wearing a premium subscription badge.
The authors’ claim is more specific. They argue that document translation improves when the system first models the source document as a directed acyclic graph, or DAG, of discourse units. The graph is not decorative architecture. It decides which earlier pieces of the document should influence which later pieces during translation.
That is the important shift. GRAFT does not merely ask the model to “consider the context”. It gives context a shape.
GRAFT begins by replacing sentences with discourse units
Most document translation systems must choose a unit of work. Sentence-level systems translate one sentence at a time and risk losing document coherence. Whole-document systems feed the entire text to a model and risk omissions, dilution, or unstable attention across long contexts. Paragraph-based systems split the difference, with the usual elegance of a spreadsheet workaround.
GRAFT chooses discourse units instead.
A discourse unit is meant to be large enough to contain local meaning, but small enough to translate cleanly. The Discourse Agent walks through the document and decides whether each new sentence should remain in the current unit or start a new one. The authors implement this decision with an LLM using few-shot prompting.
The distinction matters because the unit boundary determines what the translator treats as self-contained. If the boundary cuts too early, the model loses pronoun antecedents, idioms, tense continuity, or local terminology. If the boundary stretches too far, the unit becomes a noisy mini-document, and the translation agent has to infer which parts matter. That is not a strategy. That is hoping the model is feeling tidy.
The paper tests this directly. On TED tst2017 across eight translation directions, the LLM-based Discourse Agent averages 25.9 d-BLEU. Semantic similarity chunking averages 22.3. Random segmentation averages 14.5.
| Segmentation strategy | Average d-BLEU | What the test is doing | Practical interpretation |
|---|---|---|---|
| Random segmentation | 14.5 | Negative control | Bad boundaries damage translation badly |
| Semantic similarity chunking | 22.3 | Heuristic baseline | Topical similarity helps, but does not fully capture translation-relevant discourse |
| LLM Discourse Agent | 25.9 | GRAFT design choice | Translation units benefit from being selected for discourse function, not just semantic proximity |
This is not the main system benchmark. It is an ablation of a design choice. Its job is to answer a narrower question: does the way the document is cut affect translation quality? The answer is yes, materially.
The useful business takeaway is simple. In translation workflows, segmentation is not just preprocessing. It is a quality decision. Treating it as plumbing is how enterprises end up with beautifully fluent inconsistency at scale.
The graph is the real intervention
After segmentation, GRAFT builds a DAG over the discourse units. Every unit is connected to its immediate predecessor to preserve document flow. The Edge Agent can also add non-consecutive edges when a later unit needs information from an earlier one.
This is the paper’s central mechanism.
A plain sequential pipeline assumes that the relevant context for unit $d_i$ is mostly $d_{i-1}$. That is sometimes true. It is also frequently false. A pronoun may refer to an entity introduced much earlier. A legal term may be defined in a preliminary clause and used later in a separate section. A product name may be translated once and then need to remain stable across the document. A fiction passage may refer obliquely to a scene from several pages back, because novelists apparently refuse to optimise for machine translation.
GRAFT’s Edge Agent asks whether the translation of one discourse unit requires context from another earlier unit. If yes, it adds an edge. The graph remains acyclic because dependencies flow forward through the document.
The paper compares three edge strategies:
| Edge strategy | Average d-BLEU | Likely purpose of the test | What it supports |
|---|---|---|---|
| Chain graph | 23.9 | Sequential dependency baseline | Immediate previous context is useful but incomplete |
| TF-IDF graph | 23.8 | Lexical-overlap heuristic baseline | Surface similarity is a weak proxy for translation dependency |
| LLM Edge Agent | 25.9 | GRAFT design choice | Explicit dependency modelling improves translation quality |
The important detail is not that the LLM wins another table. The important detail is what TF-IDF fails to capture. Two discourse units can depend on each other without sharing many words. Conversely, two units can share vocabulary without one being necessary to translate the other. Translation dependency is not the same as lexical similarity. That sentence should probably be tattooed on several retrieval pipelines as well.
The authors also note that the chain graph performs better for Zh→En in one case, while the LLM edge strategy wins in the other directions. That exception is useful. It keeps the claim honest. GRAFT is not proving that LLM edge selection is universally optimal; it is showing that graph structure usually beats simplistic dependency assumptions across the tested directions.
Memory turns graph edges into usable context
A graph by itself does not translate anything. It only says where context should flow. GRAFT needs a way to pass information along the edges without forcing the translation model to ingest every upstream segment in full.
That is the role of the Memory Agent.
For each translated discourse unit, the Memory Agent extracts a structured local memory. The paper defines this memory as containing five components:
| Memory component | What it stores | Why it matters in translation |
|---|---|---|
| Noun–pronoun mappings | Target-language links between nouns and pronouns | Helps pronoun resolution and reference continuity |
| Entity mappings | Source-to-target entity translations | Keeps names, organisations, and named objects stable |
| Phrase mappings | Source-to-target phrase translations | Preserves repeated expressions and domain terms |
| Discourse connectives | Translated linking expressions | Maintains logical flow between clauses and units |
| Summary | One-line target-language context | Gives later units compact situational awareness |
This is a more disciplined version of “remember the context”. GRAFT does not preserve everything. It extracts the kinds of information likely to matter for future translation decisions.
The ablation results are instructive. With full memory, GRAFT averages 25.9 d-BLEU on the TED tests using Llama-3.1-8B-Instruct. With no memory, it averages 20.2. Removing phrase mappings causes the largest performance drop; removing noun–pronoun mappings is least damaging on average, though even that component improves De→En by 4.9 d-BLEU.
This does not mean phrase mappings are universally the most valuable memory type in every domain. It means that in the tested setting, repeated phrase-level translation carried a large part of the performance gain. For operators, that points toward an obvious deployment pattern: if your translation risk is terminology drift, structured memory is not a nice-to-have. It is the product.
The full pipeline is deliberately sequential
Once the document has been segmented and connected, GRAFT translates discourse units in order. For each unit, it gathers memory from predecessor units connected by graph edges. The Translation Agent uses the current discourse plus this incident memory to produce the translated segment. The Memory Agent then extracts fresh memory from that translated segment for downstream use.
In simplified form:
Source document
→ discourse units
→ DAG of dependency edges
→ translate each unit with upstream memory
→ update memory
→ stitched target document
This sequence is important because it explains both the quality improvement and the operational cost. GRAFT is not a single model call. It is a workflow of repeated LLM calls: segmentation, edge construction, translation, and memory extraction. The paper implements the system using pre-trained instruct models without fine-tuning, with few-shot prompts for the agents, and reports average inference time per document in the range of 20–30 seconds under its experimental setup.
The workflow is therefore closer to a translation production line than a translation model. Each station performs a constrained task. This is exactly why the system can improve consistency. It is also exactly why it is slower.
Agents: occasionally useful, provided they are given actual jobs.
The main benchmark shows competitive gains, not universal dominance
The headline benchmark evaluates GRAFT on TED tst2017 across eight translation directions: En→Zh, En→De, En→Fr, En→Ja, Zh→En, De→En, Fr→En, and Ja→En. The baselines include Google Translate, NLLB-3.3B, G-Trans, GPT-3.5-Turbo, GPT-4o-mini, and DelTA.
The strongest GRAFT configuration in Table 1 is Llama-3.1-70B-Instruct, which reports:
| Direction | GRAFT Llama-3.1-70B d-BLEU | GPT-4o-mini d-BLEU | Comment |
|---|---|---|---|
| En→Zh | 36.4 | 35.7 | Slight GRAFT lead |
| En→De | 31.9 | 30.3 | Clearer GRAFT lead |
| En→Fr | 43.1 | 43.2 | Essentially tied |
| En→Ja | 17.6 | 18.6 | GPT-4o-mini leads |
| Zh→En | 30.8 | 26.6 | Large GRAFT lead |
| De→En | 35.9 | 34.6 | GRAFT lead |
| Fr→En | 45.0 | 43.1 | GRAFT lead |
| Ja→En | 18.5 | 19.6 | GPT-4o-mini leads |
The authors summarise the system-level comparison as a 1.0 d-BLEU gain over GPT-4o-mini and a 1.1 d-BLEU gain over DelTA using the reported configurations. The paper’s own contribution statement also reports larger average gains versus a commercial system and similar LLM-based approaches.
The right interpretation is measured. GRAFT is not crushing every baseline in every language direction. It is showing that explicit discourse structure can make open 70B-class backbones competitive with, and often better than, strong general-purpose models on document translation. That is already useful. Not every result needs to arrive dressed as a revolution.
Domain tests show why the method matters more outside TED-style text
The domain-specific evaluation is more commercially revealing than the broad TED benchmark.
The authors test Chinese-to-English translation across News, Social, Fiction, and Q&A domains using WMT2022 and mZPRT. Besides d-BLEU, they report cTT for consistent terminology translation and aZPT for accurate zero-pronoun translation. These targeted metrics matter because they map better to real review pain than a single aggregate score.
GRAFT with Llama-3.1-70B-Instruct outperforms GPT-4o-mini in every listed domain on d-BLEU:
| Domain | GPT-4o-mini d-BLEU | GRAFT d-BLEU | GRAFT cTT / aZPT |
|---|---|---|---|
| News | 29.1 | 30.1 | 0.39 / 0.32 |
| Social | 35.5 | 36.2 | 0.48 / 0.44 |
| Fiction | 17.4 | 19.4 | 0.52 / 0.48 |
| Q&A | 17.4 | 21.6 | 0.41 / 0.48 |
The authors report an average gain of 2.0 d-BLEU over GPT-4o-mini and 7.5 d-BLEU over GPT-3.5 in these domain tests. They also report average gains of 6.0% over GPT-4o-mini for both cTT and aZPT.
This is where the business case starts to sharpen. Long-document translation is rarely judged only by sentence fluency. Reviewers care about whether the same technical phrase stays fixed, whether a defined term remains stable, whether omitted pronouns are recovered correctly, and whether a paragraph knows what document it belongs to. GRAFT’s architecture directly targets those errors.
In other words, this is not merely better translation. It is fewer review loops for errors that generic fluency metrics tend to underprice.
Human evaluation supports the quality claim, with a narrow scope
The paper includes human evaluation for Chinese-to-English domain translation. Annotators score general quality and discourse awareness on a 0–5 scale. GRAFT averages 4.1 for general quality and 4.2 for discourse awareness. GPT-4o-mini averages 3.0 and 3.1. GPT-3.5 averages 2.8 and 2.8. Google Translate averages 1.7 and 1.7.
| System | Average human score: general / discourse |
|---|---|
| Google Translate | 1.7 / 1.7 |
| GPT-3.5 | 2.8 / 2.8 |
| GPT-4o-mini | 3.0 / 3.1 |
| GRAFT | 4.1 / 4.2 |
This is strong supporting evidence for the claim that GRAFT improves discourse-aware translation, at least in the evaluated Chinese-English domain setting. It should not be overextended. The annotators were specialists in Chinese language and literature, the evaluation is tied to the selected domains, and the scores do not automatically translate into production acceptance rates, legal risk reduction, or post-editing time saved.
Still, the direction is meaningful. The automatic metrics are not floating alone. Human reviewers also preferred the output, especially on discourse-level quality.
The appendix adds another useful check: the authors report 70.4% correct pronoun resolution within segmented discourse, 90.2% coherence, 88.6% tense/aspect consistency, 76.3% accurate edge identification, and 84.5% terminology consistency with memory. These are not the central benchmark, but they explain why the pipeline might be working. The mechanism has visible behaviour, not just a scoreboard.
The ultra-long document test is promising, but should be treated as an extension
The paper also tests GRAFT on the Guofeng V1 TEST_2 web novel dataset. The authors compare translating the novel chapter by chapter with translating the entire novel as a single document. Using Llama-3.1-70B-Instruct for En→Zh, the full-document approach reaches 28.7 d-BLEU, compared with 24.4 for chapter-by-chapter translation.
That result is useful, but its purpose is exploratory extension rather than the main thesis. It suggests that GRAFT’s graph-and-memory structure can help with long-range dependencies in ultra-long documents. It does not prove that every enterprise should feed entire knowledge bases or legal bundles into a single graph workflow. Different document types have different dependency structures, and very long workflows raise operational questions around cost, failure recovery, review segmentation, and human traceability.
The result is best read as a signal: when context crosses chapter-like boundaries, artificial chunking can damage translation. The fix is not necessarily “translate everything at once”. The fix is to preserve the dependencies that matter across boundaries.
That is a subtler point. It is also the one worth keeping.
What the paper directly shows
The paper directly supports four claims.
First, translation-aware discourse segmentation beats generic chunking strategies on the tested TED translation directions. This is supported by the Discourse Agent ablation, where LLM segmentation outperforms semantic chunking and random segmentation.
Second, dependency modelling is useful beyond a simple chain. The Edge Agent improves average d-BLEU over both chain and TF-IDF graphs, although not uniformly in every direction.
Third, structured memory matters. Full memory outperforms no memory by 5.7 d-BLEU on average in the TED memory ablation, and phrase mappings appear especially important in the reported results.
Fourth, the full system performs well against strong baselines across broad and domain-specific evaluations, with particularly relevant gains in terminology consistency, zero-pronoun handling, and human discourse-quality scores.
None of these claims requires mystical agent enthusiasm. They are engineering claims: segment better, connect better, remember selectively, translate with the right context.
What Cognaptus infers for business use
The practical inference is that high-value translation workflows should stop treating context as a bulk commodity. More context is not always better. More relevant context, passed at the right moment, is better.
For enterprises, GRAFT points toward a translation architecture with three layers:
| Layer | Business role | Why GRAFT is relevant |
|---|---|---|
| Document structuring | Split documents into translation units that preserve meaning | Reduces local ambiguity before translation begins |
| Dependency mapping | Identify which units influence one another | Prevents the system from relying only on neighbouring text |
| Translation memory extraction | Preserve entities, terms, phrases, connectives, and summaries | Improves consistency and reduces post-editing churn |
This architecture is most attractive where translation errors have downstream cost: compliance materials, product documentation, legal templates, engineering manuals, procurement documents, clinical or scientific summaries, and multilingual support articles. These are not cases where “good enough, mostly fluent” is good enough. That phrase has caused enough damage already.
It may also fit localisation pipelines where human translators or reviewers remain in the loop. GRAFT-like memory objects could become reviewable artefacts: entity maps, term maps, phrase maps, and discourse links. That would make the system more auditable than a single opaque document-level translation call.
The strongest business version of GRAFT may not be a fully automated translator. It may be a translation orchestration layer that gives human reviewers better control over consistency.
Where the overhead bites
The limitation is not hidden. GRAFT is heavier than monolithic translation.
The authors report that GRAFT takes roughly three times longer than GPT-4o-mini for document translation. They estimate $0.12 per 1,000 words for GRAFT, versus $0.08 for GPT-4o-mini and $0.05 for GPT-3.5-Turbo. They also note sensitivity to hyperparameters such as memory size, and leave low-resource domains for future work.
That creates a clear deployment boundary.
| Use case | GRAFT-like approach? | Reason |
|---|---|---|
| High-volume casual translation | Usually no | Cost and latency likely outweigh consistency gains |
| Legal, technical, regulatory, or medical-adjacent documents | Plausibly yes, with review | Terminology and reference consistency matter |
| Product localisation assets | Yes, especially for long product families | Repeated entities and phrases need stability |
| Literary or narrative translation | Potentially yes | Long-range references and discourse flow matter |
| Real-time chat translation | Usually no | Sequential multi-agent calls are too slow |
| Internal draft translation | Depends | Use only when review cost is material |
The relevant ROI question is not whether GRAFT is cheaper per token. It is not. The relevant question is whether it reduces human correction time, prevents costly inconsistencies, or improves acceptance quality enough to justify its overhead.
That has to be measured in a real workflow. Benchmarks are not invoices, and d-BLEU is not a procurement department.
The misconception to avoid: this is not just long context
The easy misreading is that GRAFT proves long-context LLMs need more room. It does not.
The paper’s actual argument is almost the opposite. If long context alone solved document translation, prompting GPT-style models to translate the whole document should dominate. The results are more mixed. GRAFT’s advantage comes from organising the document before translation and deciding which upstream information should affect each unit.
Long context says: “Here is everything.”
GRAFT says: “Here is the part that matters for this decision, and here is why it matters.”
That distinction is central for enterprise AI. Many failures in long-document workflows are not caused by insufficient context length. They are caused by poor context routing. The system has the information somewhere, but not in the operational form needed at the moment of generation.
GRAFT is a translation paper. It is also a small case study in context governance. Annoyingly useful phrase, but accurate.
Conclusion: better translation comes from better threading
GRAFT’s contribution is not that it adds agents to translation. The world is not short of agent diagrams. Its contribution is that it gives those agents a coherent division of labour: one cuts the document, one maps dependencies, one extracts memory, and one translates with selected context.
The evidence supports the mechanism. Better segmentation improves d-BLEU. Better edge modelling improves d-BLEU. Full structured memory outperforms no memory. Domain-specific Chinese-English tests show gains in terminology consistency and zero-pronoun translation. Human evaluators rate GRAFT higher on both general quality and discourse awareness.
The practical message is equally clear. For low-stakes translation, GRAFT may be too heavy. For long, consistency-sensitive documents, it points toward a better production architecture: not one giant prompt, not sentence-by-sentence amnesia, but a structured translation workflow that knows which parts of a document need to talk to each other.
The meek shall not inherit the translation pipeline. The well-threaded might.
Cognaptus: Automate the Present, Incubate the Future.
-
Himanshu Dutta, Sunny Manchanda, Prakhar Bapat, Meva Ram Gurjar, and Pushpak Bhattacharyya, “GRAFT: A Graph-based Flow-aware Agentic Framework for Document-level Machine Translation,” arXiv:2507.03311, 2025. https://arxiv.org/abs/2507.03311 ↩︎