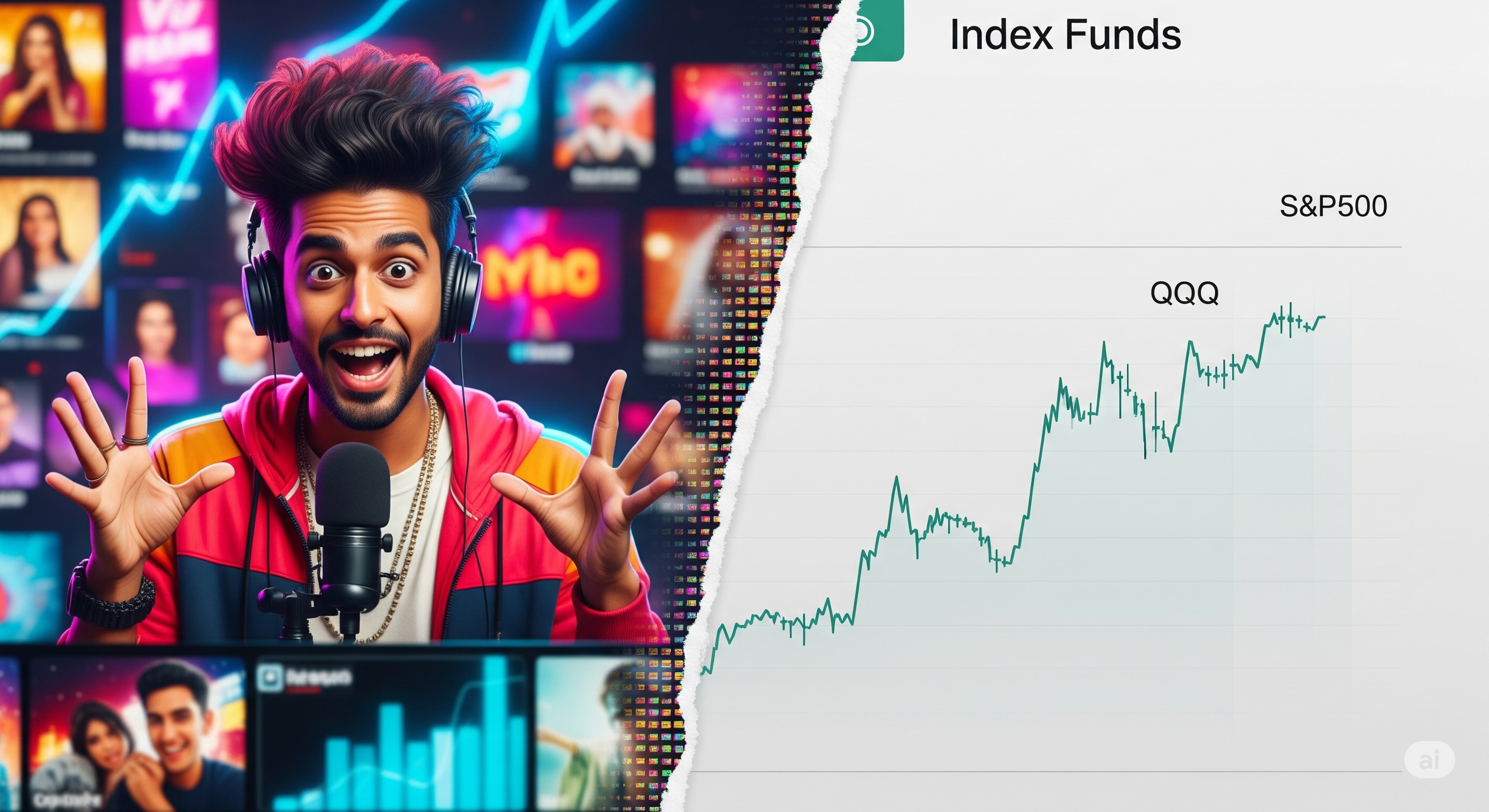
Sound and Fury Signifying Stock Picks
In an age where TikTok traders and YouTube gurus claim market mastery, a new benchmark dataset asks a deceptively simple question: Can AI tell when someone really believes in their own stock pick? The answer, it turns out, reveals not just a performance gap between finfluencers and index funds, but also a yawning chasm between today’s multimodal AI models and human judgment. Conviction Is More Than a Call to Action The paper “VideoConviction” introduces a unique multimodal benchmark composed of 288 YouTube videos from 22 financial influencers, or “finfluencers,” spanning over six years of market cycles. From these, researchers extracted 687 stock recommendation segments, annotating each with: ...