
Flame Tamed: Can LLMs Put Out the Internet’s Worst Fires?
A comparison-based reading of new research on LLMs as online mediators, separating moderation, model performance, human style, and practical deployment boundaries.
A comparison-based reading of new research on LLMs as online mediators, separating moderation, model performance, human style, and practical deployment boundaries.

A mechanism-first reading of Invasive Context Engineering, a training-free proposal for keeping LLM control instructions alive inside long conversations and agentic reasoning loops.
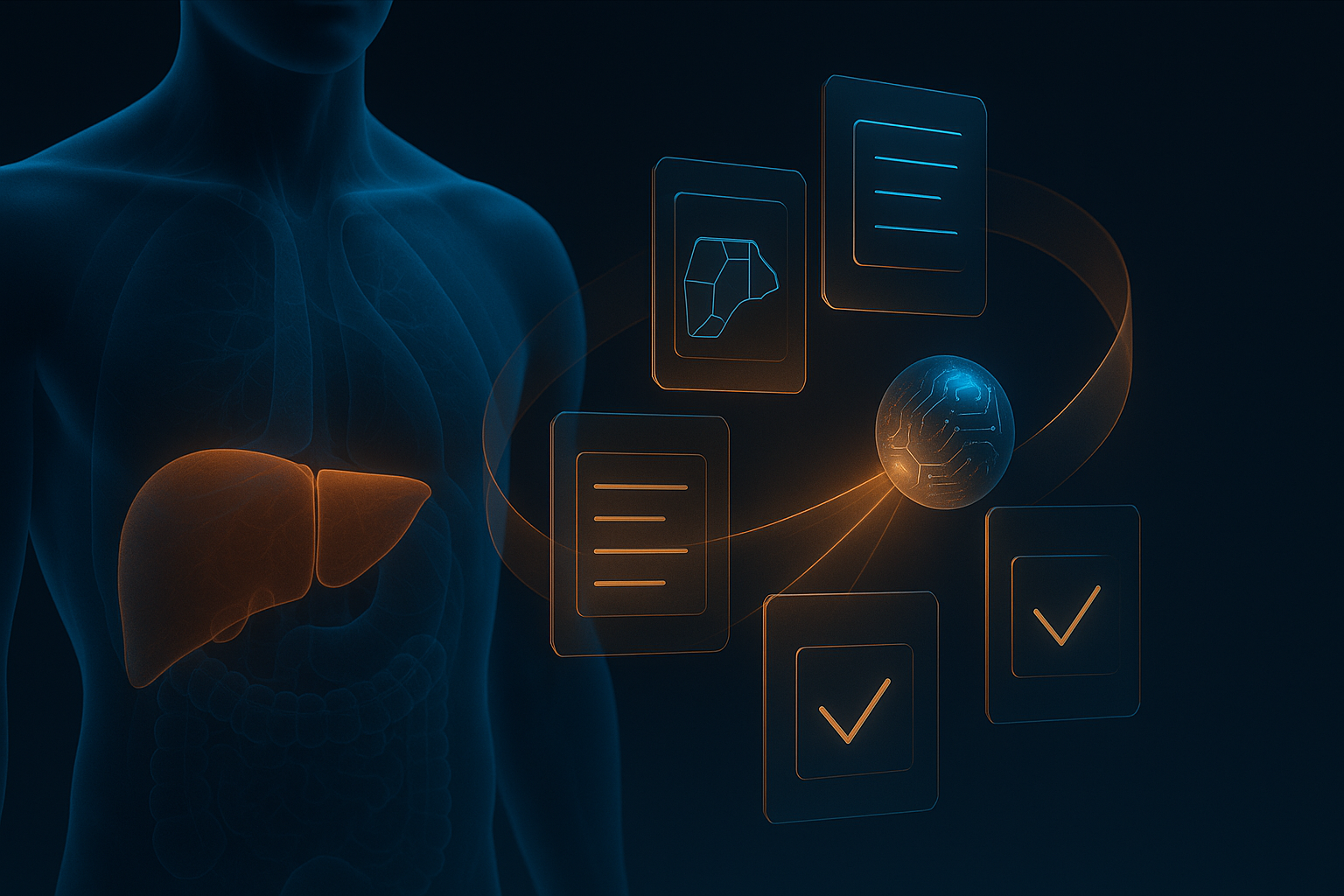
A mechanism-first look at why Radiologist Copilot matters less as a report generator and more as a workflow engine for high-stakes medical AI.

A mechanism-first reading of Martingale Score, a new unsupervised way to detect when LLM reasoning becomes prior-protecting rather than truth-seeking.

A mechanism-first look at how skill-specific n-gram models turn chess move prediction from optimal play into human behavior modeling.

A mechanism-first reading of LLM Chess, showing why interactive benchmarks expose failures that static reasoning tests often miss.

A mechanism-first reading of why reinforcement learning helps models compose memory and context only after supervised training has built the right atomic skills.

Chain-of-Ground shows that GUI grounding can improve not only by training larger models, but by forcing multimodal models to revisit their own visual hypotheses.

A mechanism-first analysis of how a GPT-2-style transformer partially learns arithmetic structure from rooted-tree Dyck words—and why that is a benchmark lesson, not a factoring breakthrough.

A mechanism-first reading of learned-rule-augmented LLM evaluators, and why the next AI judge may need better rubrics before bigger brains.