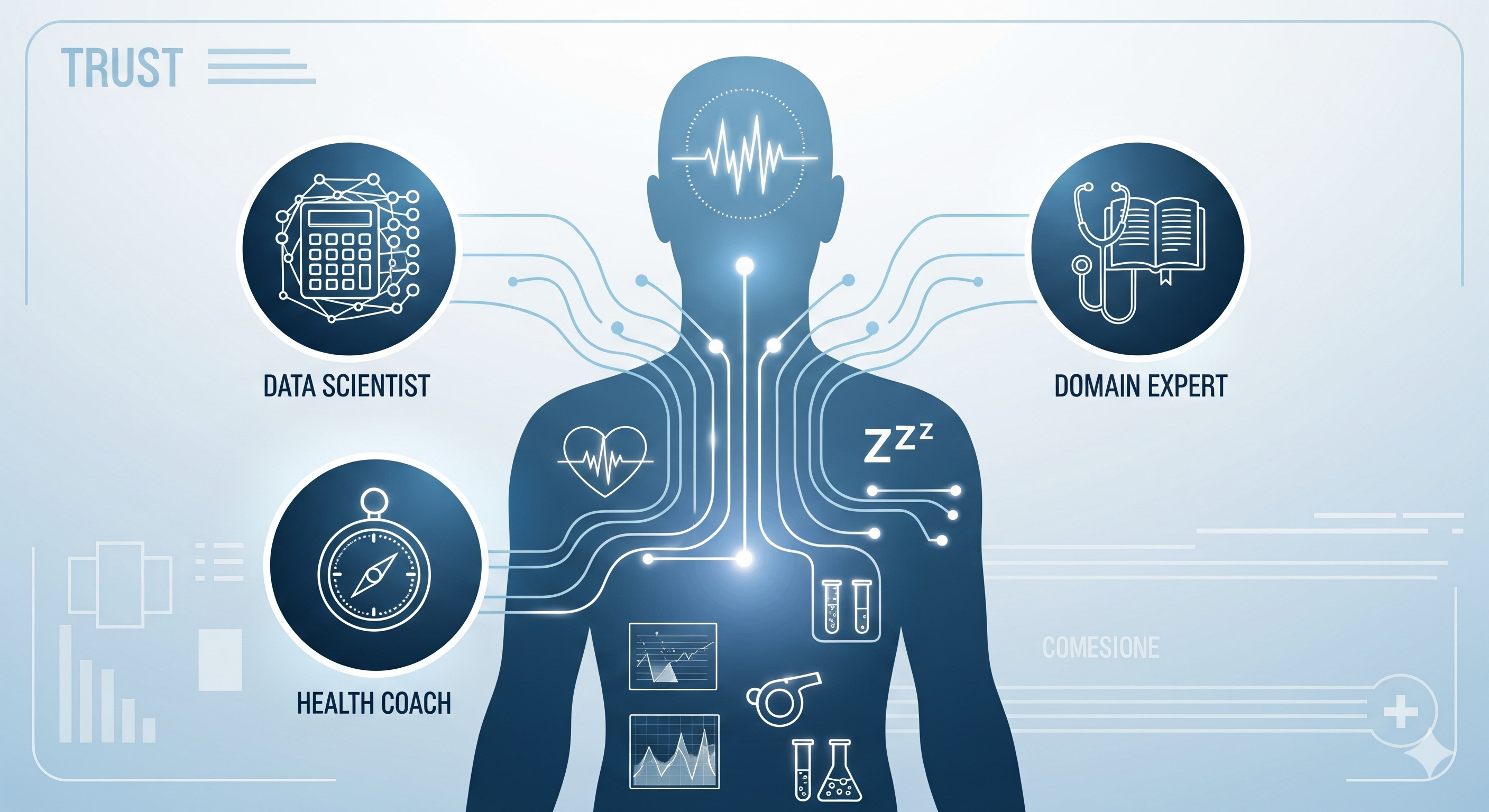
TL;DR for operators
Personal health AI is usually sold as a friendly chatbot with a fitness tracker bolted on. This paper argues for something more awkward, more expensive, and much more plausible: a coordinated system of specialised agents. One agent analyses longitudinal wearable and health-record data. One grounds advice in health knowledge and user context. One handles coaching, goal-setting, and behaviour change. An orchestrator decides who should act, who should support, what should be remembered, and how the final answer should be assembled.1
That architecture is the point. The paper is not mainly saying “LLMs can answer health questions.” Everyone has already seen that circus. It is saying that personal health support is a mixed workflow: statistical analysis, medical-context reasoning, multimodal synthesis, coaching psychology, and memory management. Forcing all of that through one conversational model is product minimalism disguised as elegance.
The evidence is broad rather than surgical. The authors identify consumer health needs through query analysis, surveys, and expert input; build three specialist sub-agents; then evaluate sub-agent capabilities and the integrated Personal Health Agent across ten benchmark tasks, with more than 7,000 annotations and more than 1,100 hours of expert and end-user effort. The data science agent improves planning quality and code reliability. The domain expert agent improves personalisation and multimodal health synthesis. The health coach agent performs better on coaching flow, motivational interviewing, and feedback incorporation. The full orchestrated system is preferred over both a single-agent baseline and a static parallel multi-agent baseline.
For business readers, the lesson is not “launch an AI doctor.” Please do not put that on a slide unless legal enjoys cardio. The useful inference is narrower: wearable platforms, wellness apps, insurers, employers, and health-navigation products can move from passive dashboards to active guidance only if they separate analytics, evidence grounding, coaching, orchestration, memory, privacy, and escalation. The uncertain part is equally important: short-term preference and expert-rating results do not prove long-term behaviour change, clinical safety, regulatory readiness, or acceptable unit economics.
The real product problem is not health knowledge. It is workflow shape.
A user asks, “Am I getting fitter recently?” That sounds casual. It is not.
A competent answer may require checking resting heart rate, steps, activity intensity, sleep, time windows, missing data, baseline periods, outliers, and whether “fitness” means endurance, recovery, weight management, or something the user has not articulated. Another user asks, “What can I do to improve my sleep?” Now the problem changes. The system needs health knowledge, personal context, behavioural advice, perhaps habit formation, perhaps motivational interviewing, and perhaps a gentle reminder that caffeine at 9 p.m. is not a personality trait.
This is why the paper’s central move is architectural. The authors frame personal health support as a non-clinical, consumer wellness problem involving multimodal data from everyday devices and personal health records. They begin with user needs, not a model benchmark. Their design process identifies four broad journeys: understanding general health topics, interpreting personal data, getting actionable wellness advice, and assessing symptoms. Those journeys are then collapsed into three specialist functions: data science, domain expertise, and coaching.
That is a sensible decomposition because the failure modes are different.
A data-analysis failure may be a wrong time window, a bad aggregation, a missing-data mistake, or code that runs but calculates nonsense. A health-knowledge failure may be outdated information, poor differential reasoning, weak personalisation, or advice that ignores a known condition. A coaching failure may be premature advice, vague goals, poor listening, or a motivational tone that sounds like a wellness poster escaped from a coworking space.
One model can attempt all of these. That does not make one model the right organisational unit.
The anatomy: three agents and an orchestrator, not one chatbot in a lab coat
The Personal Health Agent is built around three specialist sub-agents.
| Component | What it is responsible for | Main operational risk if done badly |
|---|---|---|
| Data Science Agent | Converts ambiguous user questions into analysis plans, then generates and executes code over wearable and health-record data | Confident numerical nonsense |
| Domain Expert Agent | Grounds health reasoning in authoritative knowledge, personal context, symptoms, and multimodal data | Plausible but unsafe or generic advice |
| Health Coach Agent | Runs multi-turn coaching, goal-setting, feedback incorporation, and behavioural support | Advice that is technically correct but behaviourally useless |
| Orchestrator | Selects main and supporting agents, decomposes work, reflects on outputs, updates memory, and synthesises the response | Either over-calling everything or under-using the right expertise |
The orchestrator is not decorative plumbing. It is the mechanism that turns three agents into a system.
A static multi-agent setup can call every specialist and stitch the answers together. That sounds comprehensive until the user has to suffer the result: redundant questions, conflicting framing, too much information, and no clear sense of what the system is trying to do. The paper’s orchestrated design instead assigns a main agent and supporting agents based on the user’s inferred need. It then uses reflection to reconcile outputs and memory updates to preserve useful context for later interactions.
That matters because personal health is longitudinal. The question today may only make sense because of last month’s sleep trend, last week’s goal, yesterday’s barrier, or the user’s preference for small behavioural changes over heroic self-improvement theatre. Memory is not a gimmick here. It is part of the product requirement.
The Data Science Agent handles the part dashboards keep dodging
Most wearable products already show charts. The user problem is that charts are not explanations.
The Data Science Agent is designed for the messy middle between raw signals and useful interpretation. Its first stage turns a natural-language query into a structured analysis plan. Its second stage generates and executes Python code, using an iterative execution loop to fix errors and produce numerical results. This is the right split. Planning and computation fail differently, so they need to be evaluated separately.
The reported planning result is not subtle: the Data Science Agent scores 75.6% on analysis-plan quality versus 53.7% for the base model. The code-generation evaluation uses 173 unit tests written by data scientists; the agent reaches a 75.5% first-attempt pass rate versus 58.4% for the baseline, and 79.0% after five retries.
The business interpretation is straightforward. If a product wants to answer questions like “Did my recovery improve after changing my training schedule?” it cannot rely on fluent text alone. It needs an analysis layer that can translate intent into data operations, handle missingness, choose time windows, and produce auditable computations.
The boundary is also straightforward. A code pass rate is not a health outcome. Unit tests can prove that a system performs defined computations more reliably; they do not prove that the chosen health interpretation is correct for every user, every device, every population, or every edge case. Useful, yes. Magical, no. We remain adults.
The Domain Expert Agent is where generic advice goes to be embarrassed
The Domain Expert Agent addresses a different problem: health language models often sound knowledgeable while ignoring context. A user with a condition, a biomarker pattern, a symptom description, and wearable trends does not need a generic paragraph on sleep hygiene. They need reasoning that connects personal context with grounded knowledge.
The paper’s Domain Expert Agent uses a multi-step reasoning-and-tool framework, including access to sources such as NCBI, web search, Data Commons, and a Python sandbox. Its evaluations cover medical knowledge, differential diagnosis, contextualisation, personalisation, and multimodal data synthesis.
The results are uneven in a useful way. On expert-level medical knowledge multiple-choice questions, the improvement is modest: 83.6% versus 81.8% for the baseline. On diagnostic conversations, top-1 accuracy is 46.1% versus 41.4% for a differential-diagnosis agent. These are not “game over” numbers. They are evidence of incremental reasoning advantage, not proof of clinical replacement.
The bigger signal appears in contextualisation and multimodal synthesis. End-users rate the Domain Expert Agent far higher on trustworthiness, and prefer it for personalisation in a large majority of cases. Clinicians also prefer its multimodal summaries across dimensions such as clinical significance, cross-modal association, comprehensiveness, and usefulness.
That distinction matters. In consumer health, the strongest product value may not come from outperforming doctors on board-style questions. It may come from reducing the gap between “your device collected a lot of data” and “here is what this combination of signals may mean for you, with evidence, context, and appropriate restraint.”
The restraint is not optional. Symptom assessment sits close to clinical territory, even when the paper frames the system for non-clinical settings. Any real deployment would need escalation rules, risk classification, audit trails, jurisdiction-specific review, and a very clear line between wellness support and medical diagnosis.
The Health Coach Agent attacks the last-mile problem: doing the thing
Data can explain. Expertise can contextualise. Neither makes the user go to bed earlier, walk after dinner, or stop treating stress as a productivity metric.
That is the Health Coach Agent’s job. It supports multi-turn coaching, goal identification, active listening, context clarification, user empowerment, concrete recommendations, and feedback incorporation. The architecture uses a personalised coaching module grounded in motivational interviewing, plus conversation-flow modules that determine when to recommend, when to clarify, and when to close.
The evaluation is smaller than the data-science and domain-expert sections, but it is still informative. In end-user evaluations, the Health Coach Agent outperforms the baseline on conversation flow, motivational interviewing, and feedback incorporation. Reported scores include 75.5% versus 64.5% for controlling conversation flow, 65.8% versus 57.1% for motivational interviewing, and 66.1% versus 60.7% for incorporating user feedback. Expert evaluations with health-coaching specialists point in the same direction.
The purpose of this evidence is not to prove that the system creates lasting behaviour change. It does not. The evaluation is better read as evidence that the agent follows coaching-relevant conversational behaviours more effectively than the baseline.
For operators, that is still important. A wellness product that stops at insight delivery is a dashboard with better manners. The economic value sits in behaviour: adherence, engagement, retention, reduced avoidable risk, better triage, or better self-management. Coaching quality is therefore not a soft feature. It is the conversion layer between information and action.
The full system result is really an orchestration test
The most useful comparison in the paper is not specialist agent versus base model. It is the full Personal Health Agent versus two baselines: a strong single-agent system and a parallel multi-agent system that uses the same specialists without dynamic orchestration.
That comparison isolates the managerial question. Is it enough to have the right experts in the room, or does the system need a competent coordinator?
The answer appears to be: coordination matters.
The full PHA is evaluated using 50 real-world user personas from the Wearables for Metabolic Health study and 150 multi-turn conversation scripts. End-users and health experts compare the orchestrated system against the single-agent and parallel multi-agent baselines. End-users prefer PHA for overall quality in 85.0% of cases against the single-agent baseline and 78.0% against the parallel multi-agent baseline. Experts prefer PHA for overall clinical utility in 91.0% of cases against the single-agent baseline and 86.0% against the parallel multi-agent baseline.
The parallel baseline is the important foil. It prevents the lazy conclusion that “more agents equals better.” Apparently not. More agents plus weak coordination produces noise with a project manager. The paper’s claim is more disciplined: specialist roles help when the system can decide when to use each role, how to integrate their outputs, and what context should persist.
| Test or evaluation | Likely purpose | What it supports | What it does not prove |
|---|---|---|---|
| User-need analysis from queries, surveys, and expert workshop | Design grounding | Personal health needs are diverse enough to justify role decomposition | That the identified categories cover every population or setting |
| Data Science Agent planning benchmark | Main sub-agent evidence | Better translation of ambiguous health questions into analysis plans | Correctness of downstream health recommendations |
| Code-generation unit tests | Implementation reliability test | More reliable executable analysis over structured data tasks | Real-world robustness across all devices and data formats |
| Domain Expert medical and diagnostic evaluations | Capability comparison | Better grounded reasoning and modest diagnostic gains | Clinical safety or regulatory readiness |
| Domain Expert personalisation and multimodal synthesis evaluations | Main user/expert evidence | Stronger context-aware summaries and perceived trustworthiness | Long-term health outcome improvement |
| Health Coach user and expert evaluations | Behavioural interaction evidence | Better coaching flow, motivational interviewing, and feedback incorporation | Durable behaviour change |
| Full PHA versus single-agent and parallel multi-agent baselines | Orchestration evidence | Dynamic coordination beats monolithic and static multi-agent designs | Scalable, low-cost, production-ready deployment |
This table is the paper in miniature. The contribution is not one number. It is the layering of evidence across needs, components, and system integration.
The business value is not “health advice.” It is lower-friction personal interpretation.
The obvious commercial reading is that health apps should add agents. The better reading is that personal health products need a new operating model.
Most consumer health systems are still organised around measurement. They count steps, sleep, heart rate, calories, cycle signals, glucose, blood markers, or training load. Measurement is necessary, but it leaves the user with interpretive labour. The user must decide what changed, whether it matters, what caused it, what to do, and whether the advice fits their actual life.
The paper’s architecture points toward products that absorb more of that interpretive burden.
For a wearable platform, that means moving from “Here is your trend” to “Here is the statistically defensible interpretation of your trend, given your baseline and goals.” For a wellness app, it means moving from “Here is advice” to “Here is advice adapted to your context, constraints, and readiness.” For an insurer or employer wellness programme, it means moving from generic nudges to personalised guidance with clearer evidence boundaries and escalation logic. For a health-navigation company, it means translating fragmented personal data into better-prepared conversations with clinicians, not replacing those clinicians.
The ROI logic, if it appears, will not come from chatbot novelty. It will come from reducing support burden, increasing retention, improving user trust, enabling premium personalisation, preventing avoidable confusion, and connecting users to the right next step earlier. The agent is only valuable if it makes the health journey less cognitively expensive.
What operators should copy, and what they should not
The right thing to copy is not the exact implementation. It is the evaluation discipline.
A credible personal health agent stack needs separate measurement for each function:
| Product layer | Operational metric worth tracking | Why it matters |
|---|---|---|
| Data analysis | Plan quality, code-pass rate, missing-data handling, reproducibility | Prevents fluent numerical hallucination |
| Evidence grounding | Source quality, retrieval relevance, citation traceability, contradiction handling | Prevents generic or outdated advice |
| Personalisation | Context use, contraindication awareness, preference adaptation | Prevents one-size-fits-all wellness theatre |
| Coaching | Goal specificity, user feedback incorporation, motivational strategy adherence | Converts insight into action |
| Orchestration | Correct routing, redundancy reduction, conflict resolution, memory quality | Keeps the system coherent |
| Safety and governance | Escalation accuracy, refusal quality, audit logs, privacy controls | Keeps a wellness assistant from wandering into clinical liability |
The wrong thing to copy is the public demo fantasy: a universal agent, always on, always personal, always safe, somehow cheap, compliant, and delightful. That product exists mainly in pitch decks and caffeine.
The paper actually points in the opposite direction. Proper personal health support is modular, evaluated, and operationally heavy. The moment the system uses personal health records, biomarkers, symptoms, and longitudinal behaviour, the product stops being a chatbot feature and becomes a governed workflow.
The boundary: impressive prototype, not a licence to practise medicine
The paper is careful about scope. It is concerned with non-clinical, daily personal wellness support. Google’s accompanying research write-up also states that the work is a conceptual research framework and not a description of a product, service, or feature currently available or in development; any real-world application would require separate design, validation, and review.2
That distinction should survive translation into business strategy.
First, preference evaluations are not clinical outcomes. Users and experts may prefer an answer because it is more personalised, coherent, or complete. That does not mean it improves sleep, reduces metabolic risk, changes adherence, or prevents harm over months.
Second, scripted or benchmarked conversations are not the same as messy deployment. Real users omit details, misunderstand advice, present contradictory data, ignore recommendations, share sensitive information, and sometimes ask questions that should trigger urgent care. Delightful UX is not a safety case.
Third, multi-agent systems introduce governance complexity. Dynamic orchestration improves response quality in the paper, but it also creates harder audit questions: which agent contributed what, which sources were used, how conflicts were resolved, why memory was updated, and when the system should have escalated.
Fourth, cost and latency are not decorative implementation details. Calling several agents, using tools, running code, retrieving evidence, reflecting, and updating memory may be acceptable in research evaluation. It may be painful at consumer scale unless carefully optimised.
Fifth, privacy is central. Longitudinal wearable data, health questionnaires, biomarkers, symptoms, goals, barriers, and coaching history form a rich personal profile. A system that remembers enough to be helpful also remembers enough to be dangerous if mishandled. The product requirement is not merely encryption. It is data minimisation, consent, retention policy, auditability, and user control over memory.
The strategic lesson: anatomy before autonomy
The paper’s most useful contribution is not that it makes personal health AI look more capable. It makes the category look more expensive to do properly.
That is a compliment.
A personal health agent cannot be treated as a model wrapper with a pastel interface. It needs an anatomy: one part for analysis, one part for expertise, one part for coaching, and one part for coordination. It needs evaluations that test each organ separately before declaring the body alive. It needs memory that helps without quietly becoming a liability warehouse. It needs escalation boundaries before symptom conversations become amateur triage.
For operators, the near-term play is not to promise an AI clinician. The better play is to build bounded personal interpretation: help users understand their own data, connect it to grounded knowledge, translate it into realistic action, and know when the system should stop.
That is less glamorous than “AI doctor.”
It is also much closer to something that could survive contact with users, regulators, and reality. A rare little trio.
Cognaptus: Automate the Present, Incubate the Future.
-
A. Ali Heydari, Ken Gu, Vidya Srinivas, Hong Yu, Zhihan Zhang, Yuwei Zhang, Akshay Paruchuri, Qian He, Hamid Palangi, Nova Hammerquist, Ahmed A. Metwally, Brent Winslow, Yubin Kim, Kumar Ayush, Yuzhe Yang, Girish Narayanswamy, Maxwell A. Xu, Jake Garrison, Amy Armento Lee, Jenny Vafeiadou, Ben Graef, Isaac R. Galatzer-Levy, Erik Schenck, Andrew Barakat, Javier Perez, Jacqueline Shreibati, John Hernandez, Anthony Z. Faranesh, Javier L. Prieto, Connor Heneghan, Yun Liu, Jiening Zhan, Mark Malhotra, Shwetak Patel, Tim Althoff, Xin Liu, Daniel McDuff, and Xuhai “Orson” Xu, “The Anatomy of a Personal Health Agent,” arXiv:2508.20148v2, 2025. https://doi.org/10.48550/arXiv.2508.20148 ↩︎
-
Xuhai “Orson” Xu and Ali Heydari, “The anatomy of a personal health agent,” Google Research Blog, September 30, 2025. https://research.google/blog/the-anatomy-of-a-personal-health-agent/ ↩︎