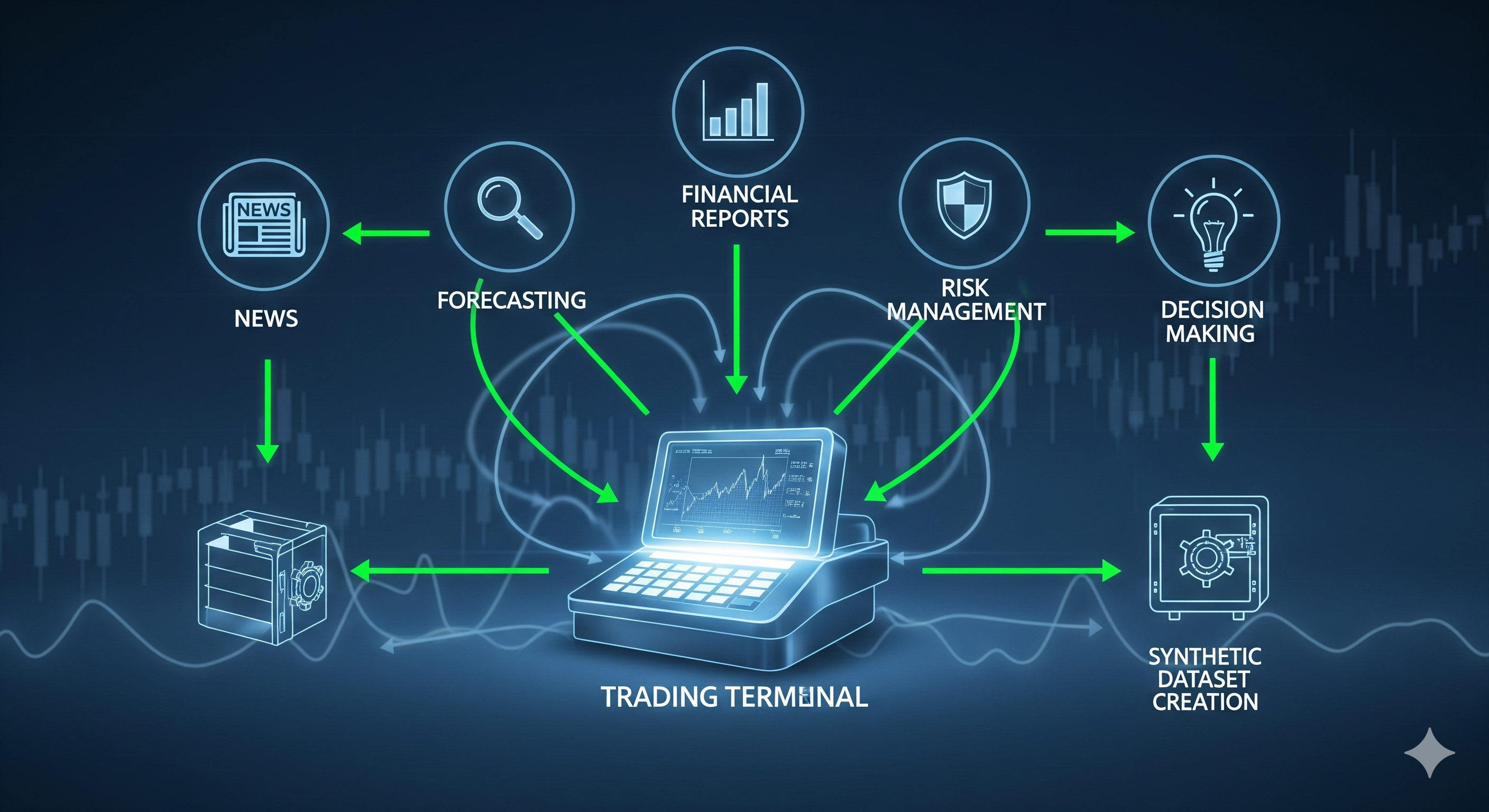
TL;DR for operators
TradingGroup is best read as an operating design for financial agents, not as a permission slip to hand the treasury account to a chatbot with a brokerage API. The paper proposes a five-agent trading system that combines news sentiment, financial-report retrieval, technical forecasting, trading-style selection, and final trade decisions. Around that agent team, it adds two mechanisms that matter more than the agent labels themselves: self-reflection from logged outcomes, and dynamic risk management through stop-loss, take-profit, and position-sizing rules.1
The headline result is that TradingGroup performs strongly in FINSABER backtests across five stocks: TSLA, NFLX, AMZN, MSFT, and COIN. With GPT-4o-mini as the core model, it beats existing LLM-agent baselines on four of the five stocks and achieves particularly strong results on AMZN and COIN. Its AMZN cumulative return reaches 40.458%, with a maximum drawdown of only -2.118%. That is not a small cosmetic improvement; it changes the risk-return profile of the backtest.
The more durable contribution is the data loop. TradingGroup records agent inputs, outputs, account state, trading style, position data, reasoning traces when available, and realised outcomes. It then converts selected decision and forecasting traces into 1,080 labelled trajectories. Using those trajectories, the authors fine-tune Qwen3-8B with LoRA and int8 quantisation, training only 0.5301% of parameters on a single V100 GPU for about six hours. The resulting Qwen3-Trader-8B-PEFT outperforms the base Qwen3-8B on cumulative return and Sharpe ratio across all five tested stocks.
For business readers, the lesson is sober and useful: the competitive edge is not “LLM intuition.” It is instrumentation. Capture decisions, context, risk state, and outcomes. Label them. Feed them back into prompts and training. Then audit whether the loop improves decisions under controlled conditions. Less oracle, more accounting system with opinions.
The boundary is equally important. This is a short historical backtest, not live trading. The evaluation covers five stocks over 127 trading days in the test window. Some stocks have sparse or no news data during that period. Execution quality, liquidity, slippage, market impact, compliance approval, and regime shift behaviour remain outside the demonstrated result. A grown-up trading desk would call this promising research infrastructure, not production P&L. Annoying, perhaps. Also correct.
The trading agent is not the product; the feedback loop is
Most “AI trading agent” narratives start with the final action: buy, hold, or sell. That is the dramatic bit. It is also the least useful place to begin.
TradingGroup is more interesting when viewed backwards. The final trading decision is only the visible endpoint of a machine that collects signals, stores traces, evaluates outcomes, retrieves past successes and failures, and turns selected episodes into training data. The trade is the invoice. The real product is the ledger.
The system has five specialised agents. The News-Sentiment Agent retrieves, filters, deduplicates, reranks, and summarises financial news into a market sentiment score. The Financial-Report Agent uses retrieval-augmented generation over annual and quarterly reports to surface relevant fundamentals. The Stock-Forecasting Agent combines technical indicators, sentiment, and fundamentals to classify likely price movement. The Style-Preference Agent decides whether the current posture should be aggressive, balanced, or conservative. The Trading-Decision Agent integrates all of that into the daily action.
That chain matters because it gives the system places to inspect and correct itself. A single monolithic model can say “buy” and then write an elegant explanation after the fact, because language models are very good at making hindsight sound like governance. TradingGroup instead separates the decision into roles and records the intermediate products. The architecture creates audit points before the trade, not just excuses after it.
The paper’s mechanism-first story is therefore simple:
| Layer | What it does | Why it matters operationally |
|---|---|---|
| Signal agents | Process news, reports, and price indicators | Separates raw market inputs from final trade action |
| Reflection mechanism | Retrieves past successful and failed cases | Gives agents a memory of outcome-labelled experience |
| Risk module | Applies dynamic stop-loss, take-profit, and sizing rules | Stops model confidence from becoming portfolio policy |
| Data-synthesis pipeline | Logs and labels agent traces | Converts operations into post-training data |
| PEFT stage | Fine-tunes Qwen3-8B on selected trajectories | Tests whether the operating loop can improve the model itself |
That is the proper unit of analysis. Not “Did the LLM predict stocks?” but “Did a structured agent workflow create better decision data than an uninstrumented model?” The paper’s answer is: in this backtest, yes.
Reflection works only because the system knows what happened next
Self-reflection is an overused phrase in agent papers. Often it means the model is prompted to critique itself, which is charmingly introspective and occasionally about as reliable as asking a sales intern to grade their own pipeline.
TradingGroup’s version is more concrete. The system does not merely ask the model to “think harder.” It labels past decisions and predictions using realised outcomes, then retrieves relevant successful and failed cases for future decisions.
The Stock-Forecasting Agent uses recent prediction cases to identify patterns and root causes. If prior forecasts failed under similar market conditions, the agent receives that history in context and is prompted to adjust. The Trading-Decision Agent labels each decision from the past 20 trading days with its market outcome, selects both good and bad examples, and compiles an experience summary before making the next action. The Style-Preference Agent reviews historical trading records, including the styles used and their profit-and-loss outcomes, then adjusts its preferred style based on account status and recent performance.
This is where the paper becomes more useful than a conventional trading-bot demo. The authors are not relying solely on model reasoning. They are building a loop in which the agent’s own operational data becomes an input to future reasoning.
That distinction matters for enterprise finance. In production, the question is rarely whether an AI system can produce one plausible recommendation. It can. Congratulations, the demo has passed 2023. The harder question is whether the system can explain which conditions led to better or worse decisions, preserve those traces, and improve without quietly learning nonsense.
TradingGroup’s reflection loop offers one answer: make experience structured enough to retrieve.
Risk management is the guardrail that changes the interpretation
The paper’s strongest practical move is pairing agent reflection with hard risk controls. This is not decorative caution; it materially changes the results.
TradingGroup’s risk-management module computes recent historical volatility, applies style-dependent coefficients, and sets adaptive take-profit and stop-loss thresholds. It also changes execution size by style. A conservative buying style uses only half of available cash, while aggressive and balanced styles deploy all available cash. On selling, aggressive style halves the position, while balanced and conservative styles fully liquidate.
This means TradingGroup is not simply an LLM making trades. It is an LLM-led decision chain constrained by explicit portfolio rules. That should calm one group of readers and disappoint another.
The calm group will notice that risk rules make the architecture closer to something a financial operator might inspect. The disappointed group may have wanted pure model magic. Tough. Pure model magic is a poor risk policy.
The ablation results show why the distinction matters. The authors test configurations with modules removed or restored. These tests are not a second thesis; they are there to identify which components are carrying the backtest.
| Test | Likely purpose | What it supports | What it does not prove |
|---|---|---|---|
| Full framework comparison | Main evidence | TradingGroup performs strongly against rule-based, predictor-based, RL, and LLM-agent baselines in the FINSABER test setup | General live-market profitability |
| Qwen3-PEFT comparison | Main evidence for data synthesis | Labelled trajectories from TradingGroup improve Qwen3-8B performance in the same framework | That the fine-tuned model generalises to new assets, regimes, or live execution |
| Module ablation | Ablation | Risk management, reflection, retrieval, and style/current-state inputs each affect risk-return behaviour | That one component alone explains all gains |
| Risk-management-off comparison | Sensitivity test | Removing risk controls can increase returns in some cases but destabilise others | That risk controls should always be fixed at the tested settings |
The risk-management-off result is especially revealing. On NFLX, disabling risk management raises cumulative return to 53.244% and Sharpe ratio to 2.726, outperforming the full version for that stock. But the same removal hurts the other four datasets, including a TSLA cumulative return drop to -14.38%. So the risk module is not a universal return booster. It is a stability mechanism.
That is the operational reading. Risk controls may sacrifice upside in one asset while protecting against larger failures elsewhere. Anyone who has ever sat through an investment committee meeting will recognise the trade-off. The paper, to its credit, does not hide it.
The backtest is impressive, but the ranking is not the whole story
The main performance table compares TradingGroup using GPT-4o-mini with rule-based strategies, predictor-based strategies, reinforcement-learning methods, and LLM-agent baselines. The metrics are cumulative return, Sharpe ratio, maximum drawdown, and annualised volatility.
The results are uneven in the way real backtests usually are. TradingGroup is not best on every metric for every stock. That makes the table more believable, not less.
On TSLA, TradingGroup reaches a Sharpe ratio of 1.398 and cumulative return of 25.662%, with maximum drawdown of -15.305%. WMA Cross produces a higher cumulative return of 32.924%, but with a slightly lower Sharpe ratio and lower annualised volatility than TradingGroup. So TSLA is not a clean “highest return wins” case. TradingGroup’s claim there is more about overall risk-adjusted competitiveness than absolute return dominance.
On NFLX, TradingGroup produces 20.458% cumulative return and a Sharpe ratio of 1.282. That is behind Buy and Hold on cumulative return and behind ARIMA and FinMem on Sharpe ratio. The authors interpret this as a case where risk management made the system conservative. The ablation backs that up: removing risk management sharply improves NFLX returns, though it worsens the broader portfolio of tests.
AMZN is the standout. TradingGroup reaches 40.458% cumulative return, a Sharpe ratio of 3.859, maximum drawdown of -2.118%, and annualised volatility of 17.228%. The paper highlights that this is far above the best reported baseline return on AMZN. More importantly, the drawdown is materially lower. That is the result most aligned with the paper’s mechanism: combining reflection, retrieval, and risk controls can improve both return and downside behaviour in a favourable setting.
MSFT is strong but less theatrical. TradingGroup returns 20.273%, with a Sharpe ratio of 1.655, maximum drawdown of -9.887%, and annualised volatility of 21.952%. It beats LLM baselines in the reported setup and shows a cleaner risk profile than many alternatives.
COIN is high-return and high-volatility. TradingGroup reaches 70.601% cumulative return and a Sharpe ratio of 2.051, but annualised volatility is 58.427%. The result is impressive, though not calm. COIN is exactly the kind of asset where a backtest can look heroic while still demanding a very adult discussion about volatility and execution.
A sensible reading is not “TradingGroup wins everywhere.” It is this: the architecture frequently improves the balance between return, drawdown, and agent interpretability, and its strongest results appear when risk control and reflection reinforce each other rather than fight the market.
The PEFT result is the quieter business story
The most commercially useful result may be the Qwen3-Trader-8B-PEFT experiment.
The authors run TradingGroup with DeepSeek-R1 over two historical training windows: 16 June 2020 to 16 August 2021, and 17 August 2021 to 5 October 2022. They test both risk-management-off and risk-management-on modes, then use the pipeline to log agent inputs, outputs, reasoning traces where available, account state, positions, trading style, and daily evaluation metrics. From this, they select 1,080 labelled trajectories for distillation.
They then fine-tune Qwen3-8B using PEFT. The setup is deliberately lightweight: LoRA with int8 quantisation, 0.5301% trainable parameters, one epoch, AdamW8bit, and roughly six hours of training on a single V100 32G GPU.
That matters because it shifts the economics. If agent operation produces useful training data, then the firm does not need to treat every improvement as a frontier-model procurement exercise. It can improve a smaller model by curating workflow-specific traces.
The results are directionally consistent across the five tested stocks:
| Stock | Base Qwen3-8B CR | Qwen3-Trader-8B-PEFT CR | Main interpretation |
|---|---|---|---|
| TSLA | 0.073% | 28.666% | Large improvement in return and Sharpe, though drawdown and volatility rise |
| NFLX | -14.49% | 29.11% | Strong reversal from negative to positive performance |
| AMZN | 3.214% | 10.427% | Better return and Sharpe, with higher drawdown and volatility |
| MSFT | 0.353% | 13.818% | Better return, Sharpe, drawdown, and volatility |
| COIN | -17.931% | 20.078% | Large return improvement, with worse drawdown and higher volatility |
The paper reports that Qwen3-Trader-8B-PEFT improves over the base Qwen3-8B on both cumulative return and Sharpe ratio across all five stocks. That is the cleanest evidence for the data-synthesis pipeline.
But the table also says something more nuanced. Fine-tuning improves return metrics, not every risk metric. TSLA, AMZN, and COIN see higher volatility after PEFT. COIN’s drawdown worsens from -27.39% to -31.102%. This is not a pure Pareto improvement. It is a return-seeking fine-tune whose risk properties still need active management.
That is why the paper’s own future-work direction—risk-sensitive annotation—is important. If the labels optimise mostly for return, the model may learn return-seeking behaviour faster than risk discipline. In finance, that is not a minor detail. It is how “promising strategy” becomes “interesting post-mortem.”
What the paper directly shows, and what Cognaptus infers
The paper directly shows that, in the reported FINSABER backtest setting, TradingGroup can outperform several baselines on important metrics across five stocks. It also directly shows that labelled trajectories generated by the system can improve Qwen3-8B performance after PEFT in the same evaluation framework.
The paper does not directly show that TradingGroup can trade profitably in live markets. It does not directly show robustness across asset classes, macro regimes, execution venues, transaction-cost models, intraday liquidity conditions, or compliance constraints. It does not demonstrate that the same fine-tuned model will generalise outside the tested environment.
The business inference is more restrained and more valuable: TradingGroup sketches a template for operational learning in finance agents.
A firm building robo-advisory, portfolio-assistant, research-copilot, or risk-monitoring systems can borrow the architecture without copying the trade engine. The transferable idea is to design every agent workflow as a data generator. Every recommendation should leave behind a record: what signals were considered, what the model concluded, what action was taken or rejected, what risk state existed at the time, what happened afterwards, and whether that outcome should count as a useful training example.
That turns AI deployment from a sequence of prompts into a compounding data asset.
| Design choice | Business translation |
|---|---|
| Multi-agent decomposition | Split decision support into auditable functions rather than one opaque answer |
| Outcome-labelled reflection | Use realised results to improve future recommendations |
| Risk module | Keep model suggestions subordinate to explicit policy controls |
| Data-synthesis pipeline | Convert daily operations into training and evaluation material |
| PEFT on selected traces | Improve smaller models using firm-specific decision records |
The important word is “selected.” Logging everything is not enough. Bad traces are easy to produce at scale. The paper filters samples using reward parameters tied to directional accuracy, confidence, signal clarity, and trading action quality. That is the part many enterprise AI programmes quietly skip. They collect the exhaust, call it a lake, and then wonder why the model learned sludge.
The limitations are not boilerplate; they define the use case
The test window runs from 6 October 2022 to 10 April 2023 and covers 127 trading days. That is a useful backtest slice, but still a narrow one. A strategy that behaves well over six months can fail when rates, volatility, liquidity, or sector rotation change. Finance has a rich tradition of backtests that looked clever until the market noticed.
The asset universe is also limited: AMZN, NFLX, TSLA, MSFT, and COIN. These are liquid, high-profile names, but they are not a representative market. They are also information-rich in uneven ways. The paper notes that TSLA and MSFT have daily news in the test window, AMZN has news on only 22 trading days, and COIN and NFLX have no news in that window. That matters because one agent’s value depends on the availability and quality of its input stream.
Backtesting itself creates another boundary. The authors disable online modules during backtesting to avoid look-ahead bias, which is good practice. Still, live trading introduces latency, slippage, order-book dynamics, transaction-cost variation, outages, corporate-action surprises, and psychological pressure from real capital. None of those are resolved by a clean framework diagram.
There is also an organisational boundary. A deployable financial agent needs compliance review, risk policy integration, audit logs, human override, model-risk governance, and clear suitability constraints. TradingGroup’s architecture creates many of the records such governance would want, but it does not replace the governance itself. A ledger is not a licence.
The real takeaway: make agents remember responsibly
TradingGroup’s contribution is not that five agents are inherently better than one. Agent counting is not strategy. A committee of confused models is still a committee.
The contribution is that the system connects three loops that are usually treated separately: signal interpretation, risk-controlled action, and outcome-based learning. The agents produce decisions. The risk module constrains them. The data pipeline records and labels them. Reflection uses those labels during future decisions. Fine-tuning tests whether those traces can improve a smaller model.
That is the pattern worth carrying into business practice. Not “let the AI trade,” but “make the AI workflow observable enough to learn from itself.”
For finance, this is a serious shift. Many AI pilots are judged by whether the model gives an impressive answer today. TradingGroup points toward a better question: does today’s answer become tomorrow’s training signal, and can the organisation prove that the loop improves behaviour without quietly increasing risk?
That question is less glamorous than a trading bot. It is also more likely to survive contact with an investment committee.
Cognaptus: Automate the Present, Incubate the Future.
-
Feng Tian, Flora D. Salim, and Hao Xue, “TradingGroup: A Multi-Agent Trading System with Self-Reflection and Data-Synthesis,” arXiv:2508.17565, 2025, https://arxiv.org/abs/2508.17565. ↩︎