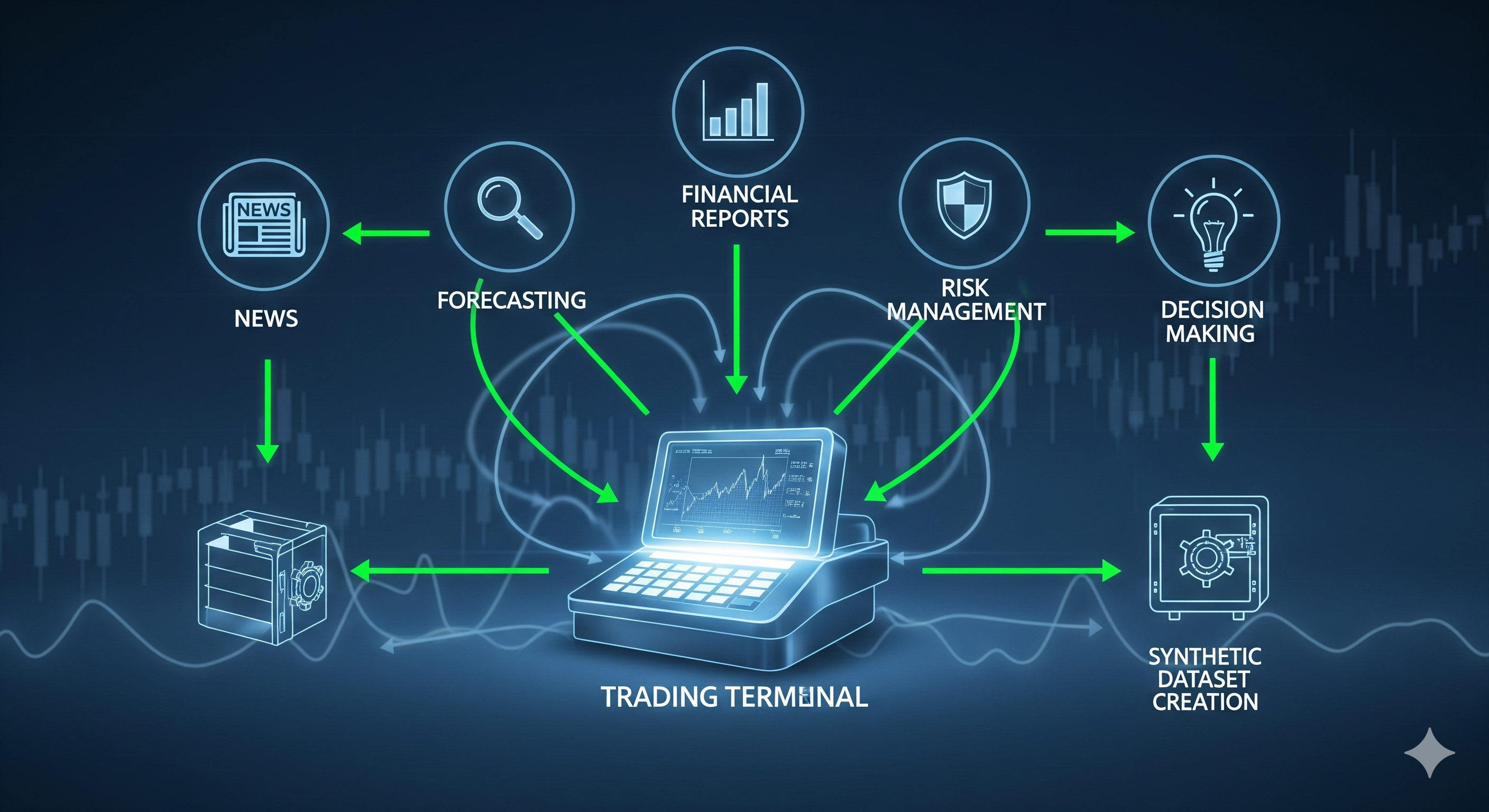
LoRA Was Supposed to Fit on the Edge. The Activations Disagreed.
TL;DR for operators LoRA does not magically make LLM fine-tuning fit on phones, laptops, or small edge boxes. It reduces the number of trainable parameters. The paper’s useful contribution is showing that this is only the opening move. The real memory bill arrives from activations, checkpoint boundaries, vocabulary-sized output computations, and tokens that are being processed even though they do not contribute to the loss. Apparently the memory allocator did not attend the product strategy meeting. ...