TL;DR for operators
The paper’s useful message is not “symbolic planners can teach LLM agents to reason socially.” That would be tidy, flattering, and mostly wrong.
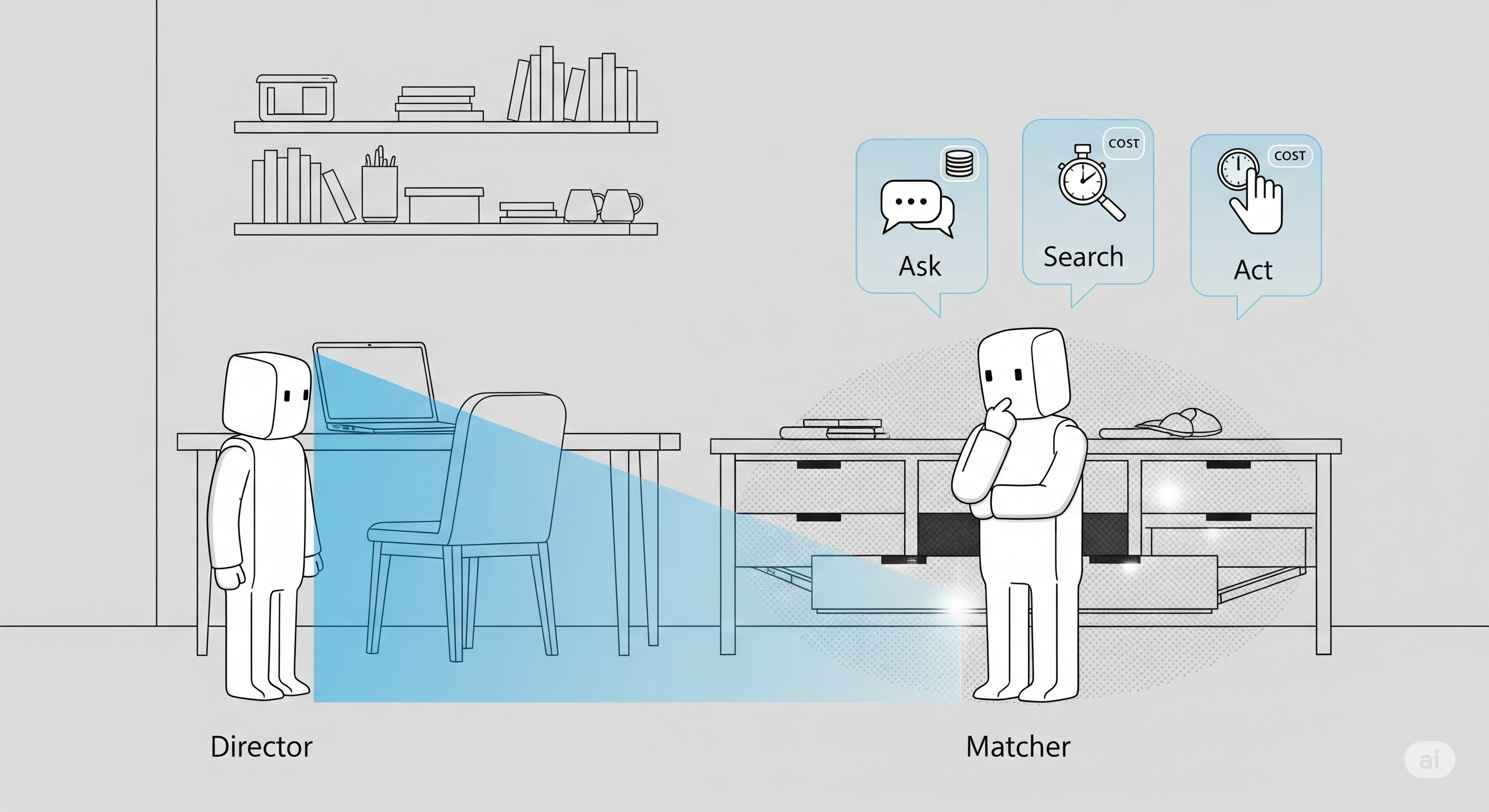
The useful message is narrower and more operational: planner-derived thought-action examples can scaffold some agent behaviour, especially local decision discipline, but they do not automatically create robust perspective-taking. In the tested Director–Matcher environment, agents do well when the task is basically “ignore what the other party cannot see.” They struggle when they must imagine what exists in another agent’s private view, or decide whether it is worth asking, moving, opening, or acting under uncertainty.1
For business agents, this matters because many failures do not look like “the model cannot reason.” They look like bad information accounting. A support agent asks too many questions because questions feel free. A compliance agent proceeds because a missing field is treated as absent rather than unknown. A trading assistant acts on visible signals while ignoring the cost of checking the hidden ones. Very sophisticated stupidity, now available at scale.
The design lesson is therefore simple but not cheap:
- keep an explicit record of who can see or know what;
- represent hidden or unobserved state as a first-class object, not as blank space;
- price epistemic actions such as asking, searching, opening, waiting, escalating, or moving;
- treat planner traces as scaffolding, not as a substitute for runtime belief tracking.
The paper’s strongest contribution is its failure taxonomy: F1 common-ground filtering, F2 imagining Director-privileged space, and F3 metacognitive cost-benefit evaluation. That taxonomy is more valuable for operators than the modest performance gains themselves.
A service agent, a missing drawer, and the cost of asking
Imagine a customer-service agent handling a refund request. The customer says, “Return the blue order.” The agent can see two blue items in the CRM: one delivered yesterday, one still in fulfilment. The customer can only see the delivered item in their app. A good agent should ignore the internal-only item and process the visible one. That is common-ground filtering.
Now make the case harder. The agent cannot see whether the customer received an attachment because it sits in a different system. It must decide whether to search the document store, ask the customer, escalate to a human, or proceed. This is no longer just “what can the user see?” It is “what might be hidden, who knows it, and is it worth paying to find out?”
That is the terrain of Annese and colleagues’ paper. The authors adapt the classic Director–Matcher task into a PDDL-based simulated environment. A Director knows the target item. A Matcher must retrieve it. The catch is that the two agents do not share the same field of view. Some objects are visible to both, some only to one, and some may be hidden inside containers. The Matcher can move, open containers, take objects, or ask the Director for clarification.
This sounds like a toy world because it is one. But the toy has teeth. It isolates a problem that enterprise agents regularly mishandle: coordination under asymmetric information.
The mechanism: three different jobs hiding under “perspective-taking”
The paper’s best move is to stop treating perspective-taking as one vague competence. It separates the behaviour into three functional demands:
| Mechanism | What the agent must do | Where it appears in business systems | Typical failure |
|---|---|---|---|
| F1: Common-ground filtering | Exclude objects or facts the other party cannot see | Customer-facing recommendations, app-state-aware support, role-based access workflows | Recommending, citing, or acting on information unavailable to the user |
| F2: Imagining Director-privileged space | Reason about what might exist in another agent’s hidden view | Missing documents, off-screen customer context, private team notes, undisclosed constraints | Treating “I do not see it” as “it does not exist” |
| F3: Metacognitive cost-benefit evaluation | Decide whether to ask, explore, wait, or act | Triage, compliance checks, trading, underwriting, incident response | Asking too much, checking too little, or acting before uncertainty is worth accepting |
This split matters because agents can appear socially competent on F1 while still being poor collaborators. Common-ground filtering is partly an attentional task: suppress the distractor that the other party cannot see. F2 is more demanding: imagine a hidden state that is not in the agent’s immediate observation. F3 is different again: compute whether more information is worth the delay, cost, annoyance, or risk.
Most AI demos blur these together under “Theory of Mind.” Convenient, yes. Diagnostic, no.
In the paper’s experiments, GPT o3-mini agents behave as though F1 is largely manageable in the simplified setting. Base, Perspective-Taking, and Near-style scenarios show perfect first-take performance across the reported example types. The harder cases are not hard in the same way. Far imposes cost pressure: the agent may need to ask or move despite no deep hidden-object mentalising. Distractor and Not That punish egocentric shortcuts: the visible or nearby object may be the wrong one. Hidden is especially interesting because its reported first-take accuracy is high, but the agent still requires a sequence of actions and does not match the planner’s efficiency. So the issue is not always final correctness. Sometimes the issue is the price paid to get there.
That distinction is exactly where enterprise AI tends to hide its failures: “the answer was eventually right” quietly excludes the three unnecessary escalations, the irritated customer, and the workflow that now takes twice as long. Other than that, splendid.
What the authors actually built
The method has three moving parts.
First, the authors construct a simulated household-like world in PDDL. The Director and Matcher occupy locations such as desks, shelves, and drawers. Each agent sees its own location and adjacent areas. Objects can be visible, occluded, or inside containers. The Director knows the target; the Matcher must infer or discover it.
Second, the authors use a modified Fast Downward planner to generate reasoning trees. These trees expose not only the successful action path but also the decision space explored by the planner. From these trees, they extract three kinds of examples:
| Example type | What it extracts | Likely purpose in the experiment | What it should teach, in principle |
|---|---|---|---|
| G-type | Optimal goal-directed paths from initial state to success | Main method variant | Efficient completion when the route to success is known |
| E-type | Paths that reach informative states | Main method variant focused on epistemic action | When to gather information through looking, moving, or opening |
| L-type | Locally optimal actions contrasted with alternatives | Main method variant focused on local choice | Why one action is better than nearby alternatives at a decision point |
Third, these planner-derived sequences are converted into natural-language thought-action examples using GPT o3-mini. The generated examples are then fed into a ReAct-style Matcher agent, which alternates between reasoning and grounded actions.
The authors test generalisation across seven task types. In each evaluation, the agent sees examples from six environments and is tested on the held-out seventh. Each test scenario is repeated five times. Metrics include first-take correctness, average number of steps, clarification questions, and epistemic actions.
This is not a large benchmark. It is a controlled probe. That is both its weakness and its value. The small setup cannot prove production readiness, but it can reveal which cognitive joint bends and which one snaps.
The figures and tables are doing different jobs
Not every figure or table in the paper should be read as evidence of the same kind. The article’s argument depends on keeping that straight.
| Paper component | Likely purpose | What it supports | What it does not prove |
|---|---|---|---|
| Figure 1: environment schematic | Implementation detail | Shows how visibility asymmetry and target/distractor placement are created | Does not establish model capability |
| Table 1: seven environment types | Experimental design taxonomy | Defines the increasing perspective-taking demands | Does not by itself show which mechanisms fail |
| Figure 2: example generation pipeline | Implementation detail | Explains how planner reasoning trees become G/E/L examples | Does not show transfer success |
| Table 2: prompting templates | Implementation detail | Shows how action sequences are verbalised into thought-action traces | Does not prove the traces encode the right latent variables |
| Tables 3–5: correctness, steps, asks | Main evidence | Shows behavioural effects of example type and task condition | Does not establish robust deployment performance |
| +ask / -ask variants | Robustness or sensitivity probe | Tests whether planner-optimal clarification examples change behaviour | Does not prove that asking is optimally priced by the LLM |
This distinction prevents a common over-reading. The pipeline is clever. The evidence is more modest. The paper is not saying “planner traces solve social reasoning.” It is saying something closer to “planner traces expose where few-shot social reasoning does not transfer.”
That is a less glamorous result. Naturally, it is also more useful.
The headline result: L-type helps a little, but the planner does not become a conscience
The strongest behavioural improvement comes from L-type examples without the additional ask-enriched planner traces. In Table 4, L-type-ask produces the lowest reported average number of steps among the example conditions: 2.97 steps on average, compared with 3.11 for no examples and 3.19 across all example variants. Table 5 shows the same direction for clarification behaviour: L-type-ask averages 0.83 ask actions, compared with 0.91 for no examples and 0.98 across example variants.
That is a real signal, but it is not a dramatic one. It says local contrastive examples may help the agent behave less ditheringly. They teach something like: given this state, here is why action A beats action B.
That makes sense. L-type examples are closer to the ReAct agent’s runtime decision format. The agent is not executing an entire planner path from scratch. It is repeatedly choosing the next move under partial observation. A local contrastive rationale is therefore better aligned with the policy decision the model actually faces.
G-type examples are elegant but brittle. They show an optimal route, yet a route is not a policy. E-type examples are more epistemically relevant, but “go until you learn something” still does not tell the agent how to price learning against acting. L-type examples are less grand and more useful: they train the decision boundary.
The planner baseline also matters. The planner averages 2.14 steps and 0.43 ask actions, much lower than the LLM-agent conditions. That gap is the paper in miniature. The symbolic planner can encode an invariant such as “act only when the target is uniquely identifiable under the relevant perspective.” The LLM can read traces of that invariant without reliably internalising it as a runtime control policy.
In business language: giving an agent five perfect examples of good judgement is not the same as installing judgement into the workflow.
The +ask result is the useful disappointment
The authors also enrich planner trajectories with epistemic ASK actions where clarification is required. This is an important sensitivity test. If the problem were merely that the agent had not seen enough examples of asking, +ask traces should help.
They do not help consistently.
For instance, L-type+ask loses the step advantage of L-type-ask, rising to 3.26 average steps in Table 4. It also produces more asking, with 1.06 ask actions on average in Table 5. G-type+ask and E-type+ask similarly fail to produce a stable success improvement. In Table 3, first-take correctness remains stubbornly poor in Far and Not That across almost all variants, and Distractor performance remains low or mixed.
This is the paper’s quiet punchline. Adding explicit ASK examples does not automatically teach the model when asking is worthwhile.
Why? Because asking is not one behaviour. It is an action with a cost, a benefit, and an alternative. In the environment, asking may reduce ambiguity. In production, asking may consume time, annoy a customer, expose uncertainty, interrupt a human, or breach an SLA. If the prompt shows asking as a good move but the agent has no cost model, it may learn “ask when unsure.” That is not collaboration. That is bureaucracy with a chatbot interface.
The paper’s discussion points in this direction: GPT o3-mini appears to treat questions as nearly free, while the linear examples do not make the underlying cost rationale explicit. The result is predictable. The agent plays safe by asking too often in some cases, yet still grabs or pursues the wrong object in others. It has examples of behaviour, not an accounting system for uncertainty.
F1 is where prompts look smarter than they are
The easy win is common-ground filtering. In scenarios where the agent only needs to suppress objects outside the Director’s perceptual access, performance looks strong. This is encouraging, but it should not be mistaken for full Theory-of-Mind competence.
F1 can be solved with a relatively shallow rule:
Prefer what is mutually visible; ignore what only I can see if the Director could not have meant it.
That is powerful in many business settings. A customer-facing agent should not refer to internal-only fields. A sales copilot should not suggest a package that is unavailable in the buyer’s region. A workflow assistant should not ask a user to click a button the user cannot see because their permissions differ.
F1 is therefore operationally valuable. It is also the part most likely to be over-celebrated. If an agent passes F1 tasks, it may look socially aware because it respects the user’s viewpoint. But the agent may simply be applying a visibility filter.
That is not an insult. Filters are excellent. Many companies would benefit from more of them. But a filter is not a theory of mind, in the same way that a “wet floor” sign is not a civil engineering degree.
F2 is where unseen state becomes real work
F2 requires a different move: the agent must represent a space it cannot currently observe but that may matter to another agent. In the paper’s environment, this can mean reasoning about objects hidden in containers or areas visible only to the Director. In business systems, it means missing attachments, undocumented exceptions, private dashboards, stale data feeds, incomplete KYC files, or side-channel context held by another team.
The common failure is not hallucination in the usual sense. It is anti-hypothesis. The agent fails to treat the unobserved as a meaningful possibility.
This is dangerous because many workflows encode absence ambiguously. A blank field may mean the document was never submitted. It may mean the connector failed. It may mean the user lacks permission. It may mean the item exists in a separate system. An LLM operating over a flattened prompt often has no durable representation of that difference.
The paper’s prompt-design discussion highlights this issue. Some failures may arise because the prompts do not sufficiently foreground unexplored but accessible regions. If the agent is not induced to represent hidden areas as plausible information sources, it will not explore them. It will behave as though the visible state is the world.
That is a deeply familiar enterprise failure. Dashboards do it. Analysts do it. Agents, being trained on us, do it at machine speed.
F3 is the missing price tag
F3 is the part that turns a reasoning problem into an operating problem. The agent must decide whether the value of new information exceeds the cost of obtaining it.
The study’s Far condition is especially useful here. According to the authors, Far creates pressure even when no full hidden-space mentalising is required. The target and distractor are both visible to both agents, but their positions change the cost of acting versus clarifying. First-take accuracy in Far is poor across nearly all example types: most variants report 0%, while the no-example condition reaches only 20%. The model does not reliably choose the right information strategy.
This matters more than the absolute percentages, because the task is small. The pattern says the agent has trouble with costed epistemic control. It may know asking exists. It may know movement exists. It may have seen planner traces. But it does not robustly compute:
In production, that inequality is everywhere.
Should a procurement agent ask the vendor for clarification or infer from the quote history? Should a fraud agent block a transaction now or run one more check? Should a trading assistant query an expensive data feed before acting? Should a compliance copilot escalate to legal or continue with standard policy?
A model that treats every question as free becomes a polite nuisance. A model that treats every search as free becomes a latency problem. A model that treats missing information as irrelevant becomes a risk event wearing a productivity badge.
What the paper directly shows
The direct evidence is compact.
The authors test GPT o3-mini agents in a controlled PDDL Director–Matcher world with seven task types. They generate planner-derived examples using Fast Downward and convert them into ReAct-style thought-action traces. They compare G-type, E-type, and L-type examples, including variants with and without epistemic ASK actions.
The reported results show:
| Finding | Evidence in the paper | Interpretation |
|---|---|---|
| Simple shared-visibility tasks are handled well | Base, Perspective-Taking, and Near show 100% first-take correctness across variants | F1 common-ground filtering appears reliable in this simplified setting |
| L-type local examples modestly improve efficiency | L-type-ask has the lowest example-condition average steps at 2.97 | Contrastive next-action reasoning aligns better with ReAct decisions than full path examples |
| L-type-ask also reduces asking | L-type-ask averages 0.83 ask actions, below no examples at 0.91 and the condition average at 0.98 | Local decision examples can trim some clarification behaviour |
| Ask-enriched examples do not reliably improve behaviour | +ask variants do not consistently improve success, steps, or ask counts | Showing when to ask is not the same as learning the cost of asking |
| The planner remains much more efficient | Planner average steps are 2.14 and ask actions 0.43 | Symbolic structure encodes constraints the LLM does not reliably absorb from examples |
The cleanest reading is not that examples fail. They help slightly in the form most aligned with the agent’s runtime choice. But the hard part of perspective-taking is not producing nicer rationales. It is maintaining the right latent variables while acting.
What Cognaptus infers for business systems
The business inference is architectural.
Planner-derived examples are useful as scaffolds for agents. They can improve decision discipline, generate training data, and make behaviour more auditable. But the paper suggests that examples alone are a weak mechanism for production reliability when the task requires belief tracking or costed information gathering.
A more robust enterprise agent should separate four layers:
| Layer | Role | Practical implementation |
|---|---|---|
| Visibility model | Records who can see which objects, facts, screens, documents, or fields | visible_to(actor, item), role permissions, UI state, document access logs |
| Belief model | Represents what each actor likely knows or does not know | Per-actor knowledge ledger with timestamps and evidence sources |
| Hidden-state model | Keeps unobserved but plausible states alive | Unknown fields, inaccessible systems, pending attachments, unopened containers |
| Epistemic cost model | Prices asking, searching, waiting, escalating, or acting | SLA cost, user-friction cost, API cost, risk reduction, latency budget |
The LLM can still be useful. It can phrase questions, propose hypotheses, summarise evidence, and explain decisions. But it should not be left to improvise the entire epistemic economy from a few examples. That is how you get agents that sound thoughtful while doing the wrong accounting.
For enterprise design, the invariant should be explicit:
Do not act on a target unless the system can explain why that target is uniquely identified under the relevant actor’s perspective, or why the residual uncertainty is acceptable.
This is the business version of the planner’s discipline. It is also much easier to audit than a paragraph of chain-of-thought theatre.
A practical pattern: planner-in-the-loop beats planner-as-storyteller
The paper uses the planner to generate examples. That is valuable for experimentation. For deployment, a stronger pattern is to keep the planner or a lightweight decision scorer in the loop at runtime.
The difference is important.
Planner-as-storyteller says: “Here are good examples. Model, please behave accordingly.”
Planner-in-the-loop says: “Here is the current state. Generate candidate actions, score their epistemic value and cost, then choose under constraints.”
A minimal production loop might look like this:
- The LLM parses the task and proposes candidate actions: answer, ask, search, open, escalate, wait, or execute.
- A state layer checks visibility and belief constraints.
- A cost model estimates the price and value of each epistemic action.
- A planner or policy scorer rejects actions that violate uniqueness or risk thresholds.
- The LLM explains the selected action to the user or operator.
This does not require a heavyweight symbolic planner for every workflow. In many business processes, a rules-plus-scoring layer is enough. The key is not PDDL purity. The key is refusing to let the language model pretend that uncertainty is free.
Where this applies
The paper’s environment is household-like, but the mechanism generalises to workflows where actors have asymmetric information.
In customer support, F1 prevents the agent from referencing internal-only state. F2 reminds the agent that missing user-visible context may exist outside the current ticket. F3 prices whether another question is worth asking before resolution.
In compliance and onboarding, F1 separates what the applicant submitted from what internal systems know. F2 keeps missing documents and hidden beneficial-owner facts alive as hypotheses. F3 decides whether to request more information, proceed with conditional approval, or escalate.
In financial operations and trading support, F1 separates what the trader sees from what the system sees. F2 represents off-screen feeds, stale data, restricted research, and missing confirmations. F3 prices checks against latency and risk. The wrong choice here is rarely “the model used a bad adjective.” It is usually “the model acted before uncertainty was priced.”
In multi-agent automation, the same logic applies between agents. One agent may know a contract clause; another may only know the invoice. One may see the live system; another may see a cached report. If their shared state is implicit, coordination fails politely.
Boundaries: useful diagnostic, not deployment proof
The study’s limitations matter because they constrain how far the business inference can go.
First, the environment is small and symbolic. Visibility is binary. Real enterprise settings have graded salience, partial permissions, noisy interfaces, stale records, contradictory systems, and humans who do not answer questions like clean API endpoints. Very inconsiderate of them.
Second, the evaluation uses seven task types and five trials per held-out scenario. That is enough to reveal patterns but not enough to estimate reliable production effect sizes.
Third, the model tested is GPT o3-mini in a simulated ReAct setup. Results may differ across models, prompts, modalities, and agent frameworks. The mechanism is the more transferable part, not the exact metric.
Fourth, the thought-action examples are generated from planner traces by an LLM. That creates a translation layer: the planner’s state discipline becomes natural-language rationale. Some structure is inevitably lost. A plan can encode constraints; a rationale may merely describe them.
Finally, the Director is only indirectly modelled through task configuration. A richer social environment would require modelling intent, gaze, conversational goals, trust, user patience, and competing incentives. That would make F2 and F3 harder, not easier.
These boundaries do not weaken the paper’s operational value. They define it. The paper is best read as a diagnostic stress test for a class of agent failures, not as a benchmark leaderboard.
The uncomfortable lesson: reasoning traces are not the reasoning system
The seductive idea is that if we show an LLM enough examples of good thought-action behaviour, it will acquire the underlying competence. Sometimes that works well enough. This paper shows where the seduction starts to wobble.
Planner traces can show the path. L-type examples can sharpen local choices. Ask-enriched traces can demonstrate clarification. But none of that guarantees the agent has learned the hidden machinery: who knows what, what may exist off-screen, and what it costs to find out.
For Cognaptus-style agent design, the implication is direct. Do not build “perspective-taking” as a personality trait in the prompt. Build it as infrastructure:
- visibility ledgers;
- actor-specific knowledge states;
- explicit unknowns;
- costed epistemic actions;
- audit rules for unique identification;
- runtime scoring rather than static demonstration alone.
The polite way to say this is that social reasoning in agents needs grounded state. The less polite way is that prompts do not magically become a balance sheet.
Conclusion: teach the agent to look, but also teach it what looking costs
“Who sees what?” is only the first question. “Who pays the cost of finding out?” is the operational question.
Annese and colleagues show that structured thought-action examples can help ReAct-style agents behave somewhat better, especially when examples are local and contrastive. But the core result is a boundary: agents can filter shared visibility more easily than they can imagine hidden worlds or price information-gathering actions.
That boundary is where serious agent engineering begins.
If an enterprise agent must coordinate with humans, tools, or other agents, do not merely give it better examples. Give it a state model. Give it a belief ledger. Give it a cost schedule. Then let the language model do what it is good at: interpreting messy inputs, proposing options, and explaining decisions.
The agent does not need to be mystical. It needs to know what it knows, what others know, what might be hidden, and whether finding out is worth the bill.
Cognaptus: Automate the Present, Incubate the Future.
-
Luca Annese, Sabrina Patania, Silvia Serino, Tom Foulsham, Silvia Rossi, Azzurra Ruggeri, and Dimitri Ognibene, “Who Sees What? Structured Thought-Action Sequences for Epistemic Reasoning in LLMs,” arXiv:2508.14564, submitted 20 August 2025, https://arxiv.org/abs/2508.14564. ↩︎