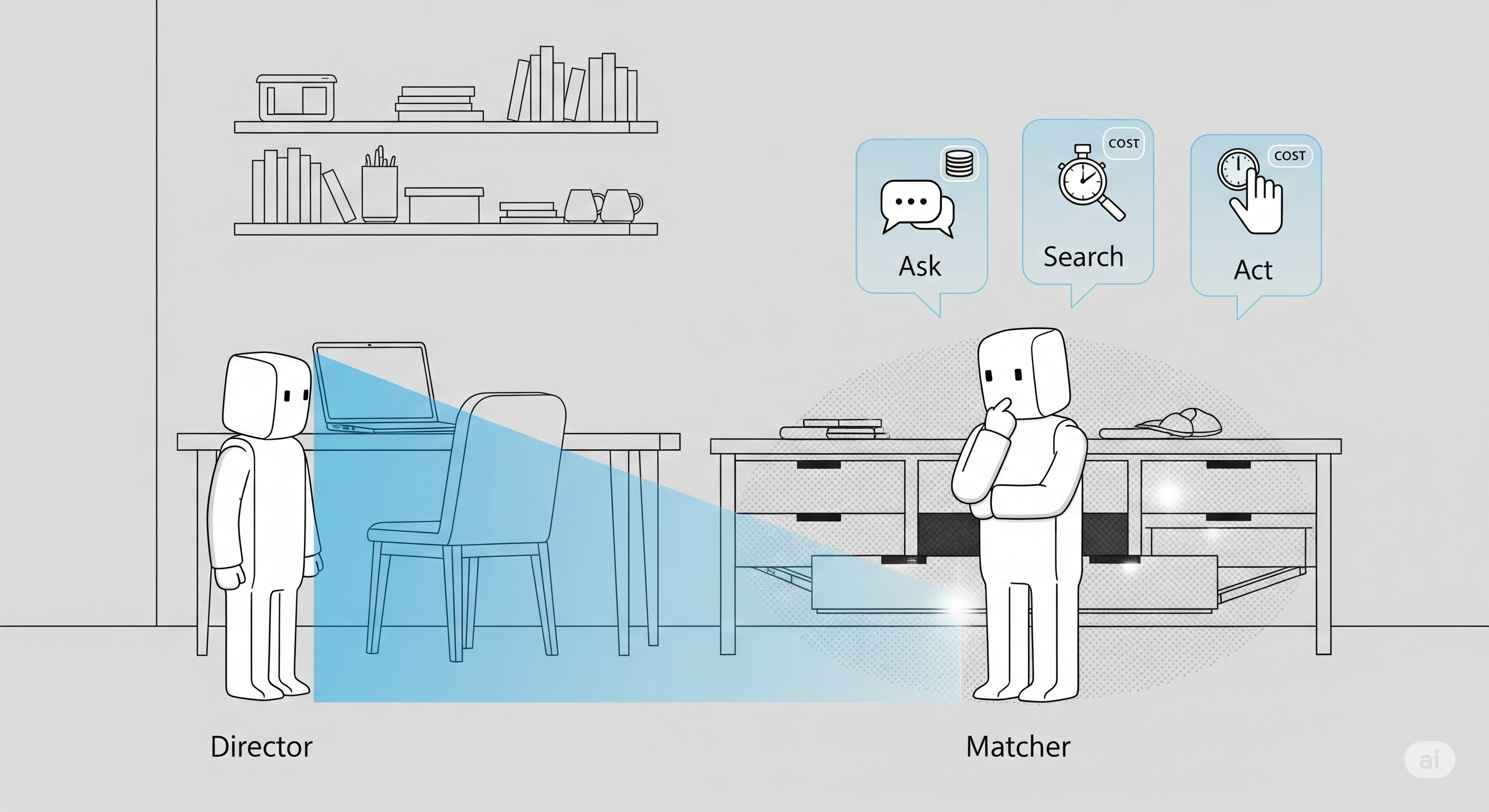
TL;DR for operators The paper’s useful message is not “symbolic planners can teach LLM agents to reason socially.” That would be tidy, flattering, and mostly wrong.
The useful message is narrower and more operational: planner-derived thought-action examples can scaffold some agent behaviour, especially local decision discipline, but they do not automatically create robust perspective-taking. In the tested Director–Matcher environment, agents do well when the task is basically “ignore what the other party cannot see.” They struggle when they must imagine what exists in another agent’s private view, or decide whether it is worth asking, moving, opening, or acting under uncertainty.1
...