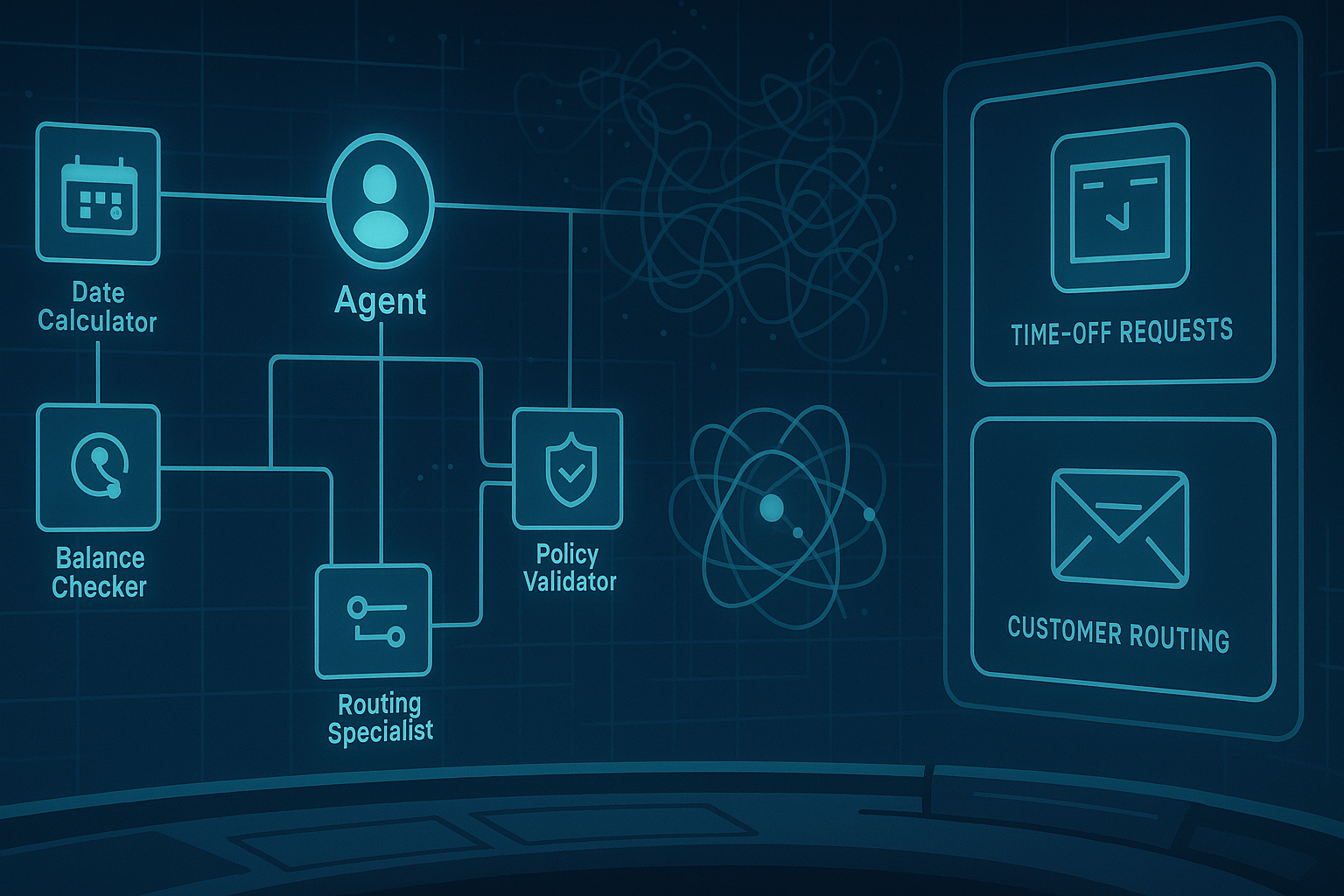
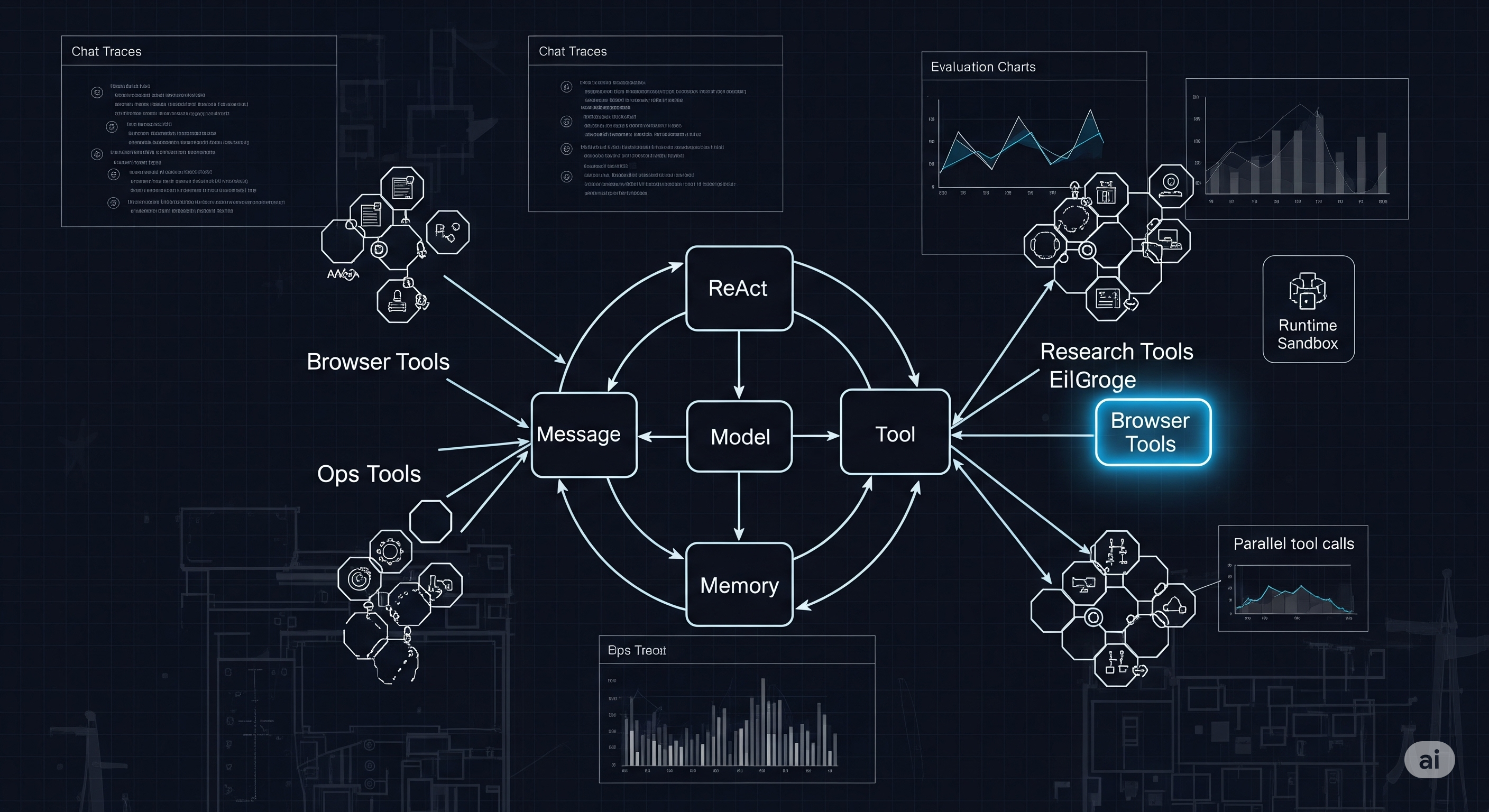
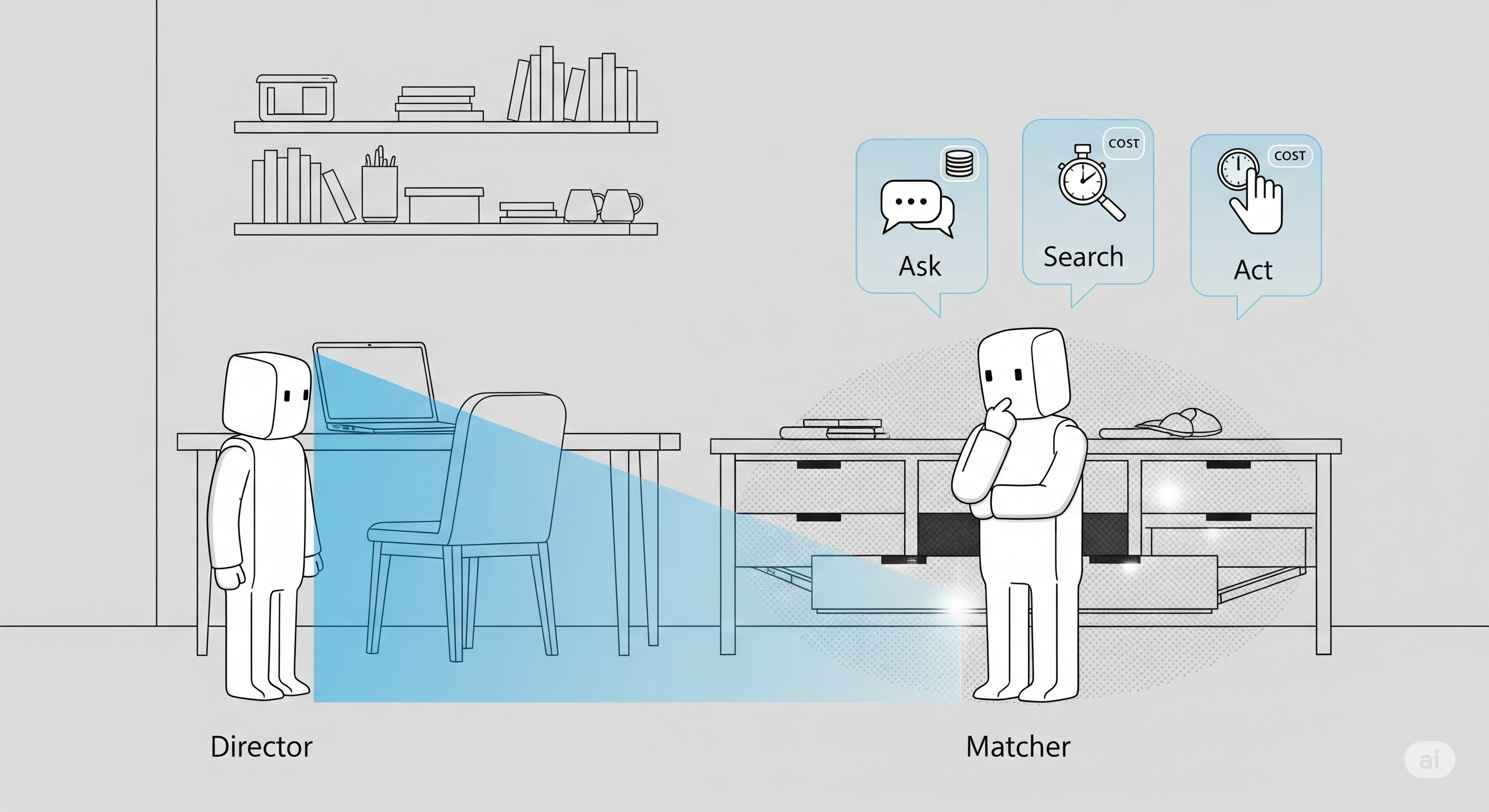
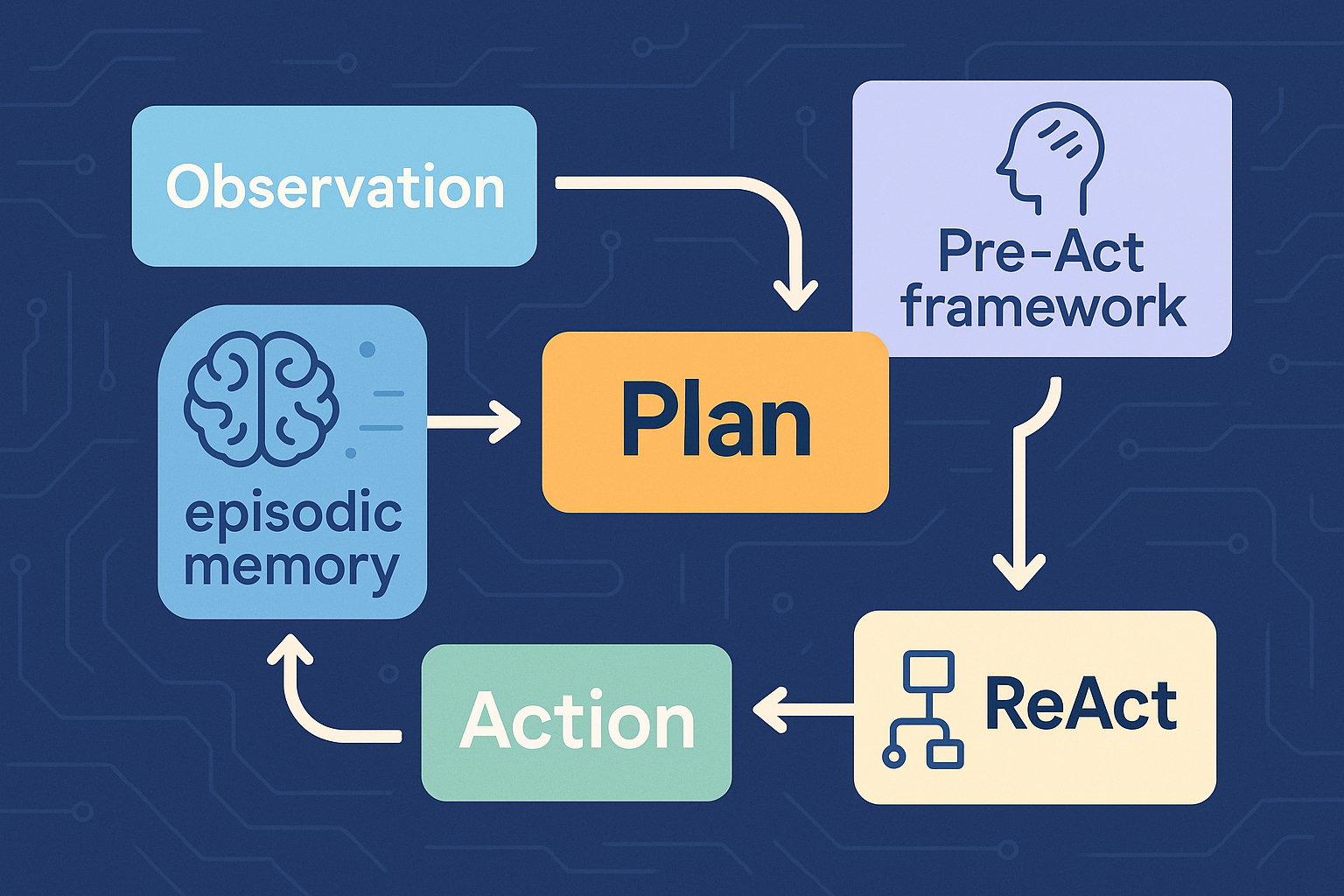
Think, Then Do: Why ReAct Turned LLMs into Real Agents
A chatbot answers. An agent checks. That distinction sounds small until a workflow fails at 2:17 p.m. because the model confidently invented a policy clause, skipped the database lookup, and then explained itself with the serene authority of a consultant who has already left the building. The 2022 paper ReAct: Synergizing Reasoning and Acting in Language Models matters because it made that failure mode harder to ignore.1 It did not simply ask language models to “think step by step.” Chain-of-thought prompting already did that. It did not simply attach a search box to a model. Retrieval-augmented systems were already moving in that direction. The paper’s real contribution was more architectural: it showed that a language model could alternate between reasoning, acting, observing, and revising its next move. ...