TL;DR
A new study probes whether you can teach perspective‑taking to ReAct‑style LLM agents by feeding them structured examples distilled from a symbolic planner: optimal goal paths (G‑type), information‑seeking paths (E‑type), and local contrastive decisions (L‑type). The punchline: agents became decent at common‑ground filtering (what the other party can see) but remained brittle at imagining occluded space and pricing the cost of asking vs. exploring. In business terms, they’re good at “don’t recommend what the customer can’t see,” but still bad at “should I go find out more before I act—and is it worth it?”
The Setup: Teaching Perspective by Plan
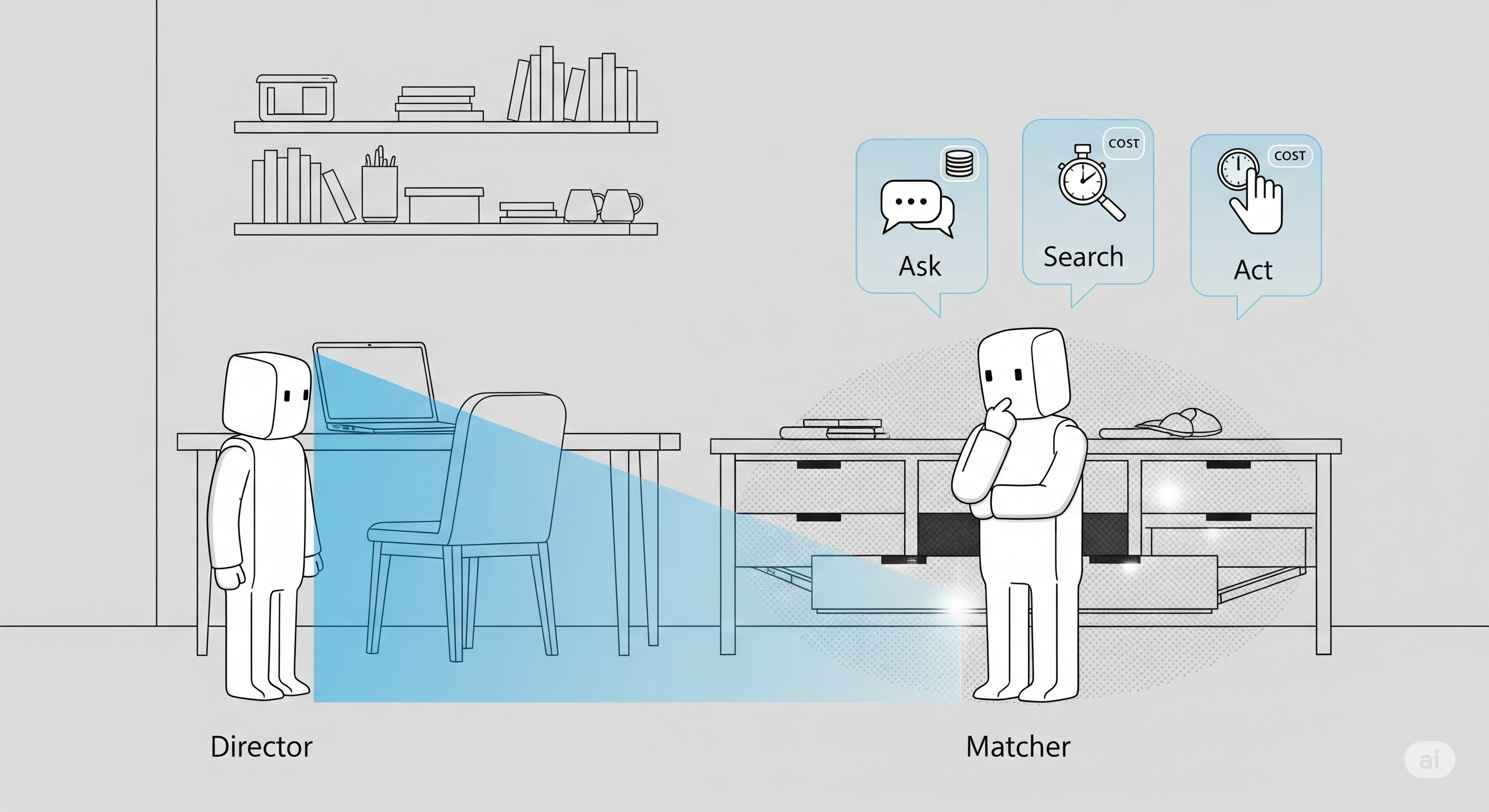
The authors embed a classic Director–Matcher task in a PDDL world: a Director knows the true item; a Matcher must fetch it under partial visibility and clutter. They then run a Fast Downward planner to produce reasoning trees, from which they distill three families of examples and re‑write each step as thought→action snippets for a ReAct agent:
| Example Type | Intuition | What it Trains | Business Analogue |
|---|---|---|---|
| G‑type (goal path) | Shortest path to success | Efficiency under full info | Minimal‑steps order routing when all fields are complete |
| E‑type (epistemic path) | Moves that gain information | When/where to look, open, check | KYC/doc hunt, log dives, screen-pop checks before a trade |
| L‑type (local contrastive) | “Why A, not B, now?” | Micro‑choice justification | Next best action ranker in CX/CRM |
The agents train on six layouts and are tested on a held‑out seventh—escalating from easy “everything visible” to hard “something is hidden or misleading.”
What Improved (and What Didn’t)
- Slight win for L‑type: Contrastive, step‑wise examples trimmed excess clarification questions and shaved a few steps—suggesting that teaching choices in context nudges agents toward more grounded actions.
- No durable jump in success across tricky cases: even when the planner’s traces explicitly included when to ask or look inside, few‑shot exposure didn’t transfer to robust behaviour.
Why? Because two missing ingredients dominate hard settings:
-
Belief tracking: Agents need an explicit representation of “what I think you can see/know,” not just a textual reminder.
-
Cost models: If asking a question is “free” in the agent’s head, it will spam queries instead of exploring—or grab the nearest look‑alike when it should pay to check.
Three Cognitive Jobs Your Agents Must Learn
Let’s reframe the paper’s insights as a checklist for agentic systems you might deploy (sales copilot, fraud triage, trading assistant):
| Cognitive Job | Description | Typical Failure Mode | Example in Business Ops |
|---|---|---|---|
| F1: Common‑ground filtering | Exclude anything the counterpart can’t see/know | Offers irrelevant to the user’s view/context | Recommender shows out‑of‑stock or not‑in‑region items |
| F2: Imagined occluded space | Hypothesise what’s behind the metaphorical “closed drawer” | Premature action without checking hidden constraints | Approving a loan without retrieving a missing statement |
| F3: Epistemic cost‑benefit | Decide whether to ask, search, or act now | Over‑asking, under‑exploring, or knee‑jerk execution | Helpdesk bot loops with clarifying questions; trader acts without a needed feed |
The study shows we can already make F1 pretty reliable with structured examples. F2 and F3 remain the frontier.
Design Playbook: From Demo‑Smart to Production‑Ready
If you’re building agent workflows (support, underwriting, ops, trading), treat these as product requirements, not just prompts:
-
Belief‑state ledger (lightweight ToM): Maintain per‑actor visibility/knowledge sets (what was seen, when, by whom). Require actions to update this ledger.
- Implementation hint: store
seen_by[actor]andknown_factskeyed by objects/fields; all tool calls write deltas.
- Implementation hint: store
-
Epistemic cost schedule: Put a numeric price on ASK, SEARCH, WAIT, MOVE, OPEN. Penalise question spam, reward decisive information gain.
- Heuristic: time cost × risk reduction. Use live metrics (latency, SLA, human annoyance) as feedback.
-
Contrastive policies at decision points: Keep the L‑type spirit—always score why action A over B. Log the top‑2 deltas so you can audit “reason to proceed.”
-
Planner‑in‑the‑loop, not planner‑as‑dataset: Instead of static G/E/L exemplars, call a planner at runtime on a simplified state sketch to output next epistemic move (open, peek, ask). The planner provides structure; the LLM provides language & glue.
-
UI to visualise occlusion: In customer or analyst tools, render “known/unknown” zones. Agents and humans aligned on the same map will ask less and act better.
Minimal Architecture You Can Ship Next Sprint
- State store: JSON doc with
facts,beliefs,uncertainties,visibility,costs. - Policy step: (a) LLM drafts options; (b) planner scores epistemic value vs. cost; (c) choose.
- Guardrails: Hard rules like “don’t execute if target not uniquely identified” unless a risk override is signed.
- Learning loop: Every decision writes
(state, options, choice, cost, outcome)to a counterfactual dataset. Fine‑tune a small scorer to approximate planner judgements over time.
Why This Matters for Cognaptus Clients
- Contact centers: Reduce “Sorry, may I ask another question?” loops by charging the bot a token budget for each ask and rewarding first‑time resolution.
- FinOps / Trading: Make “peek into hidden drawers” (missing market feed, stale fundamentals, off‑chain signals) an explicit epistemic action with cost and payoff. Don’t let the agent swing without price‑checking the information.
- Risk & Compliance: Force “unique identification of the target” before actions like PII access or money movement—mirroring the planner invariant.
Our Take
Structured thought–action examples are a useful scaffold—especially the contrastive L‑type that trims dithering. But the leap from demo‑smart to ops‑reliable requires two upgrades outside the language model:
-
an explicit belief model; and
-
an accounting system for information cost.
Do those, and your agents will stop playing 20 Questions and start acting like teammates.
Cognaptus: Automate the Present, Incubate the Future