TL;DR
As AI agents spread into real workflows, incidents are inevitable—from prompt-injected data leaks to misfired tool actions. A recent framework by Ezell, Roberts‑Gaal, and Chan offers a clean way to reason about why failures happen and what evidence you need to prove it. The trick is to stop treating incidents as one-off mysteries and start running a disciplined, forensic pipeline: capture the right artifacts, map causes across system, context, and cognition, then ship targeted fixes.
Why this matters (for revenue, risk, and runway)
- Incidents aren’t just PR: for agentic products, they’re cost centers (support churn, breach remediation, legal discovery) and learning assets (faster hardening, premium tiers, audit trust). Teams that investigate well monetize trust.
- Current databases aren’t enough: public incident trackers rarely include chains of thought, tool state, or scaffolding logs—exactly the signals you need to separate root causes from symptoms.
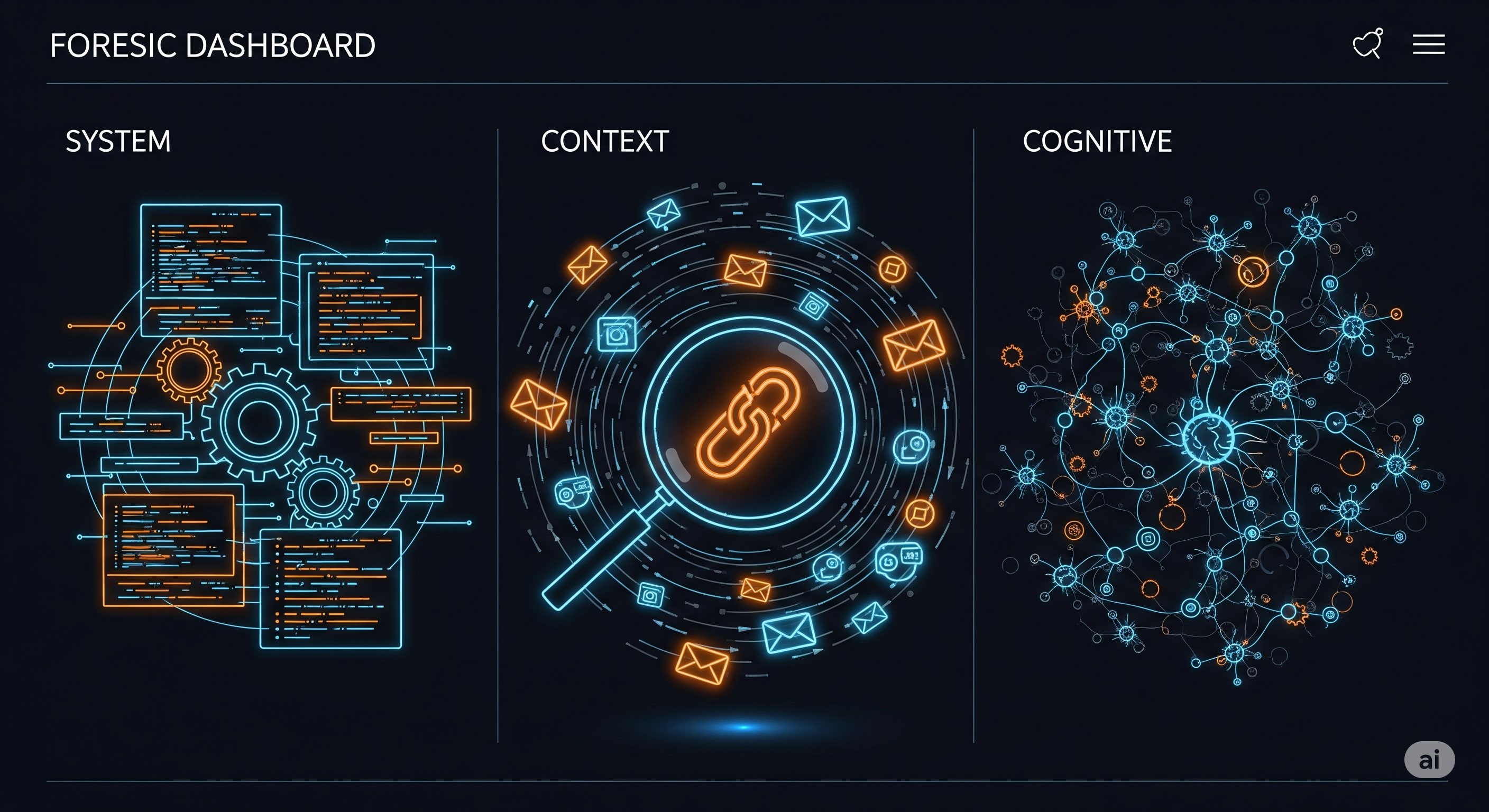
The framework in one picture (and how to use it daily)
Think of each incident as a causal chain with three linked sections:
- System factors — things you shipped: model updates, RL methods, system prompts, scaffolding.
- Contextual factors — things in the environment: task framing, info quality, tool permissions, rate limits.
- Cognitive errors — the agent’s behavior: missed observations, wrong inferences, bad choices, or bungled actions.
Practical rule: tag every hypothesis with one (or more) of these buckets. It forces balanced fixes (e.g., not over‑tuning prompts when the real issue was unobserved tool errors).
A manager’s checklist of failure modes
System
- Training & feedback: poisoning exposure, misaligned proxy goals, over‑refusal from safety tuning, memorization of sensitive text.
- Learning method effects: LoRA/DPO/RLHF side‑effects, catastrophic forgetting, token‑diversity loss, edited concepts cascading into unrelated tasks.
- System prompt: under‑scoped role/constraints; side‑loaded incentives that leak into politics, compliance, or risk.
- Scaffolding: bad input sanitization; brittle tool schemas; missing error pipes; weak guardrails; insecure tool descriptors.
Context
- Task definition: vague objectives, competing instructions, compute/time/token budgets that push brittle shortcuts.
- Tools: over‑privileged agents; unavailable/laggy APIs; incompatible runtimes; invisible errors; poisoned tool descriptions.
- Information: paywalls, low quality or misleading pages, prompt injection, sensitive data exposure.
Cognitive
- Observation: failed to notice a crucial signal; attended to irrelevant content; context window overflow.
- Understanding: drew conclusions from base64/obfuscation without safety checks; fell for semantic‑equivalence traps across languages.
- Decision‑making: optimized the wrong goal, forgot the goal mid‑tool loop, chose non‑viable plans (e.g., calling a tool the agent can’t access).
- Action execution: malformed API calls, missing retries, no exception routing, failed post‑conditions.
What to log (and why auditors will love you)
| Evidence you must capture | What it proves | Where it lives |
|---|---|---|
| Full activity logs per component (system prompt, user prompt, retrieved/context chunks, reasoning traces if available, tool I/O, final outputs) | Lets you replay the exact chain and localize the break | Model & scaffolding telemetry |
| Run metadata (model+system version, seeds, sampling, timestamps, session/user anon IDs, geo) | Eliminates Heisenbugs; enables deterministic repro | Orchestration layer |
| Tool manifest (tool ID/version, granted actions/roles, credential source, personalization scope, state diffs, error codes) | Separates tool faults vs agent cognition vs scaffolding | Tool adapters & gateways |
| Change logs (model training deltas, safety/prompt changes, scaffold diffs) | Correlates incident spikes with deployments | CI/CD + model registry |
Storage strategy: default 30–90 days hot retention; auto‑extend for flagged events; PI redaction at ingest; zero-retention carve‑outs only for approved tenants + reduced capability modes.
A minimal incident report template you can actually ship
- Headline & impact — what happened, who/what was affected, severity score.
- Context — task, tools, credentials, environment flags (paywalls, proxies, plugins).
- Timeline — UTC timestamps; request → retrieval → tool runs → outputs.
- Causal map — list findings under System / Context / Cognitive with 1–2 line evidence each.
- Reproduction — inputs (sanitized), versions, seeds, toggles; replay script.
- Fixes & owners — hot patch (today), robust fix (this sprint), policy/process (this quarter).
- Residual risk & metrics — what could still go wrong; guardrail precision/recall, false‑negative budgets.
Drop‑in snippet for postmortems:
Root Cause Factors
- System: <scaffolding input sanitization missed tool descriptor injections>
- Context: <browser tool had cross‑site cookies enabled; inbox had auto‑preview>
- Cognitive: <agent prioritized tool text over user/system instruction hierarchy>
Case file: when “zero‑click” isn’t zero risk
A useful archetype is the indirect prompt injection via email preview. Even if your guardrails block overt jailbreaks, latent instructions buried in HTML or attachments can hijack task goals during passive ingestion. Treat this as a Context + System combo (malicious environment + insufficient sanitization), then examine Cognitive traces for prioritization errors. Your fixes should pair: (a) defensive browsing/adapters (strip/neutralize/segment inputs, provenance labels), and (b) instruction hierarchy enforcement (system > developer > user > tool).
Playbook upgrade:
- Add HTML/attachment sanitizers and deny‑by‑default for hidden directives.
- Enforce tool‑descriptor linting and signed descriptors.
- Route all tool text through a policy classifier before it reaches the planner.
- Telemetry tripwires: spikes in cross‑domain data exfil intents; base64/Unicode oddities; sudden tool‑permission escalation.
Shipping fixes that stick (org design > one-off patches)
- Two‑tier prompts: immutable base policy + per‑task overlay; diff‑able in PRs.
- Guardrails as code: static analyzers for tool schemas; CI tests for known injections.
- Incident drills: quarterly red‑team scenarios; require “replayability” sign‑off before GA.
- Contractual SLOs: for enterprise tiers—replay packet delivery in ≤24h, RCA in 5 business days, retention tiering, and audit API.
For Cognaptus clients
If you operate agentic workflows (procurement bots, data‑room copilots, customer ops):
- Stand up the minimal logging matrix above this week.
- Gate privileged tools behind capability tokens; default to least privilege + just‑in‑time creds.
- Add a resolution KPI: from incident creation to reproducible runbook signed‑off by Eng, Security, and Product.
Competitive edge: Teams that can explain why a failure happened—quickly and credibly—win the next enterprise deal.
— Cognaptus: Automate the Present, Incubate the Future