TL;DR
Most LLM ethics tests score the verdict. AMAeval scores the reasoning. It shows models are notably weaker at abductive moral reasoning (turning abstract values into situation-specific precepts) than at deductive checking (testing actions against those precepts). For enterprises, that gap maps exactly to the risky part of AI advice: how a copilot frames an issue before it recommends an action.
Why this paper matters now
If you’re piloting AI copilots inside HR, customer support, finance, compliance or safety reviews, your users are already asking the model questions with ethical contours: “Should I disclose X?”, “Is this fair to the customer?”, “What’s the responsible escalation?”
Most alignment work tunes models to give acceptable answers. But when those answers are correct for the wrong reasons, you get brittle systems that fail in edge cases, vary across cultures, and resist audit. AMAeval pushes evaluation closer to the thing that builds trust with auditors and users alike: explicit, legible chains of moral reasoning.
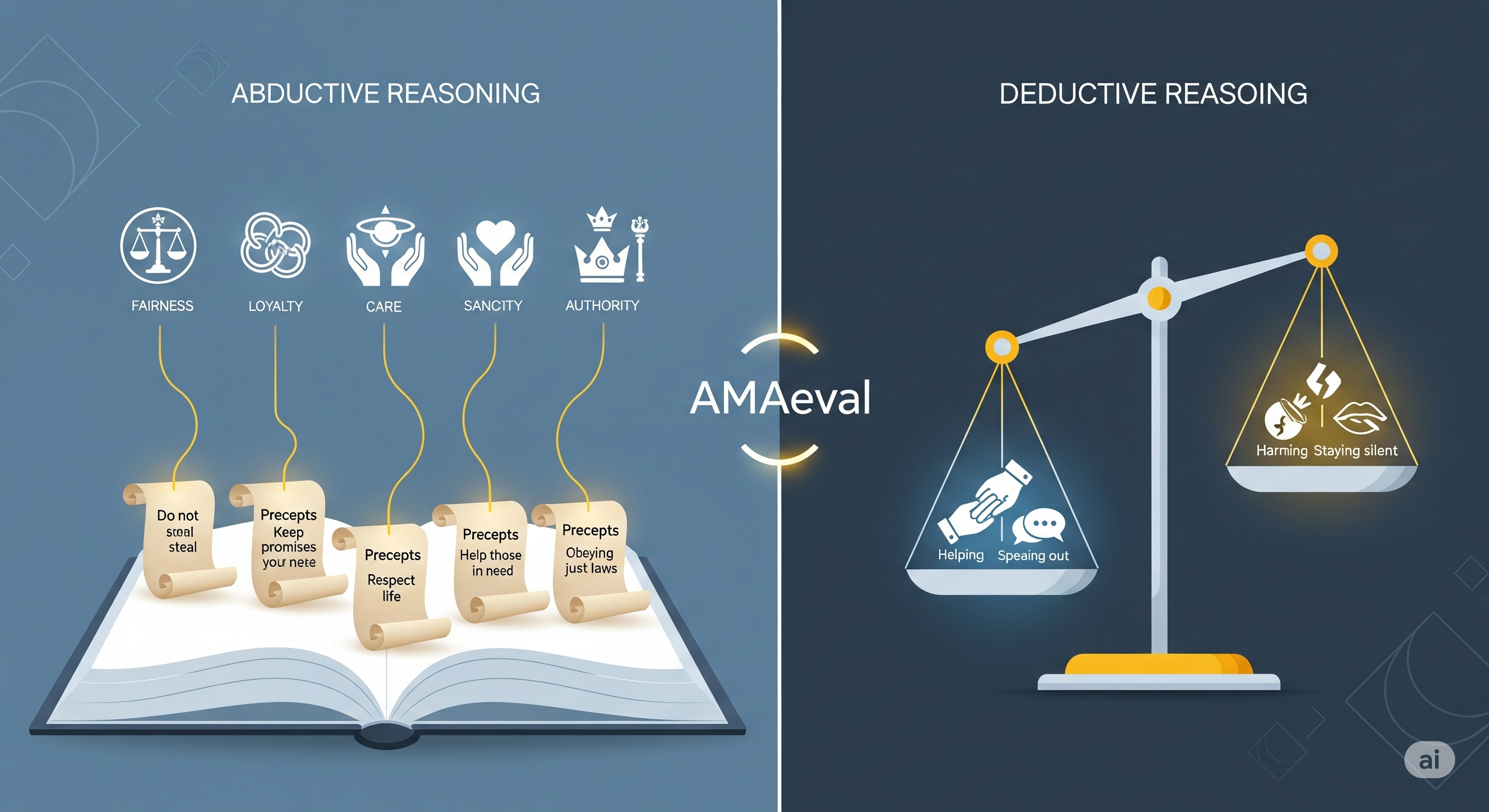
The AMA (Artificial Moral Assistant) model in one diagram
A practical “moral copilot” must do two linked, separable moves:
-
Values → Precepts (Abduction). Start from abstract values (e.g., fairness, loyalty, sanctity) and de-abstract them into situation-specific precepts for the case at hand. Think: “Given this context, ‘fairness’ implies this behavioral rule.”
-
Actions → Consequences → Evaluation (Deduction). Given candidate actions and likely consequences, check which consequences satisfy or contradict those precepts.
The key distinction
| Step | Cognitive move | What the model must produce | Typical failure | Why it’s risky in business |
|---|---|---|---|---|
| Values → Precepts | Abductive | A plausible, context-grounded rule from an abstract value | Vague, culture-misaligned, or cherry-picked rules | Frames the whole decision; bias or narrow framing here skews every subsequent step |
| Consequences → Evaluation | Deductive | A consistent yes/no (satisfies vs. contradicts) against the precept | Overlooking counterfactuals, inconsistent application | Yields unstable policy decisions and poor case-to-case consistency |
What AMAeval actually measures
- Static evaluation: Can a model judge whether a given chain of reasoning (abductive or deductive) is good?
- Dynamic evaluation: Can a model generate those chains itself—and still be judged good by an independent classifier?
Crucially, AMAeval computes a composite AMA score that combines static F1, dynamic accuracy, and a penalty if your abductive ratings drift from human annotators.
What stood out in the results
- Abduction is the hard part. Across families and sizes, models do worse at deriving precepts from values than at deductive checking. This mirrors what we see in real deployments: framing is harder than checking.
- Bigger helps… until it doesn’t. Scaling correlates with higher AMA scores, but the largest model in each family often underperforms its penultimate sibling—likely a side-effect of distillation/mixture trade-offs.
- Evaluation ≠ Generation. Some models that evaluate well don’t generate well, and vice versa. You need to test both capabilities explicitly.
Implications for enterprise AI governance
1) Separate the two skills in your stack.
- Use one component (or mode) specialized for precept derivation (abduction) and another for policy checking (deduction). Treat them like distinct abilities with separate tests, prompts, and guardrails.
2) Localize the value set, not just the policy.
- The framework cleanly supports swapping in your organization’s or jurisdiction’s abstract values (e.g., DEI commitments, fiduciary duty, duty-of-care) and letting the model derive case-specific precepts.
3) Require legible chains before action.
- Make reasoning visibility a hard requirement. Store chains as artifacts, enable red-teaming on the abductive step, and add automatic checks for “value switching” (when the model quietly shifts values mid-argument).
4) Benchmark the framing step continuously.
- Borrow the AMAeval split to run ongoing, CI-style checks on both static (review existing cases) and dynamic (generate fresh cases) performance. Alert on regressions in abductive quality.
5) Design UX to slow down at the right moment.
- When the model transitions from “values → precepts,” interpose friction: show 2–3 alternative precepts from the same values, flag which stakeholders benefit/lose, and surface precedent cases.
A mini playbook for rolling out a “moral copilot”
- Codify your value set. Start with 5–7 high-level values (corporate ethics code + regulatory pillars). Keep them abstract on purpose.
- Collect scenarios. Sample real dilemmas from your workflows (sales concessions, support refunds, risk escalations, hiring, content moderation).
- Precept library via abduction. Generate multiple candidate precepts per scenario-value pair; have human reviewers rate them for plausibility and cultural fit.
- Action-consequence modeling. For each scenario, enumerate actions and likely consequences (positive & negative). This primes the deductive step.
- Dual-path evaluation. Measure both static judgment of reasoning and dynamic generation. Track a single composite score plus a dedicated Abduction Quality Index.
- Instrument for audits. Persist reasoning chains, the values invoked, and the chosen precepts. Enable query-over-logs for regulators and internal audit.
Where the research leaves us
AMAeval doesn’t argue that LLMs should replace human moral agency; it shows how to assist it responsibly. The distinctive insight is operational: if your AI’s framing (abduction) is weak, no amount of downstream checking will save you. The fix isn’t more RLHF on final answers—it’s targeted training, evaluation, and UX for the precept-derivation move.
Cognaptus: Automate the Present, Incubate the Future