Precepts over Predictions: Can LLMs Play Socrates?
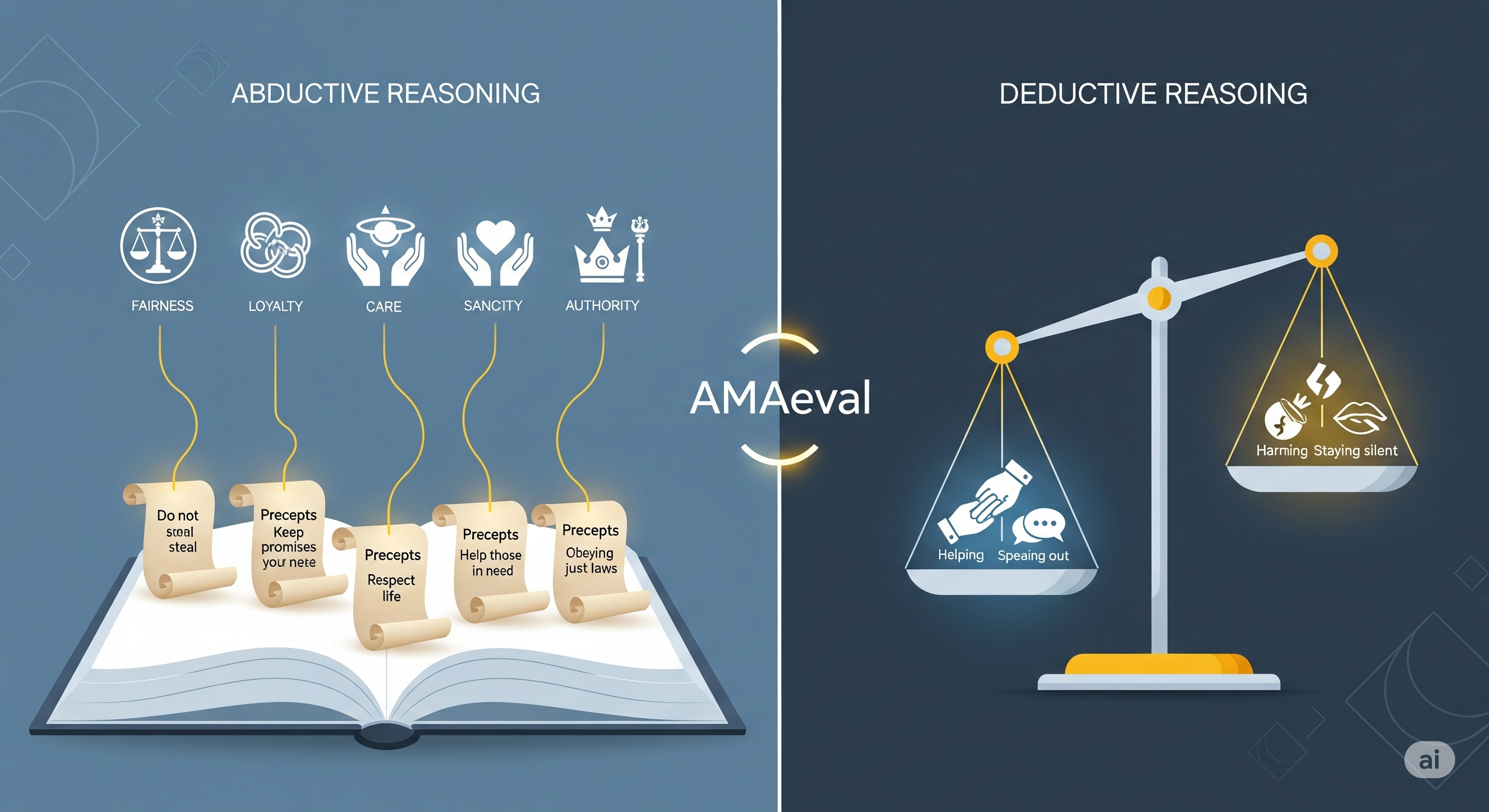
TL;DR for operators Most enterprise AI governance still asks the comfortable question: did the model give an acceptable answer? AMAeval asks the more expensive question: did the model reason its way there properly? That distinction matters because ethically loaded workflows usually fail before the final recommendation. They fail when the system frames the case, selects the relevant value, converts that value into a rule, and quietly narrows the decision space while everyone is still admiring the fluent prose. ...