Green Lights, Smarter Cities: How Multi‑Agent Reinforcement Learning Is Rewiring Urban Traffic
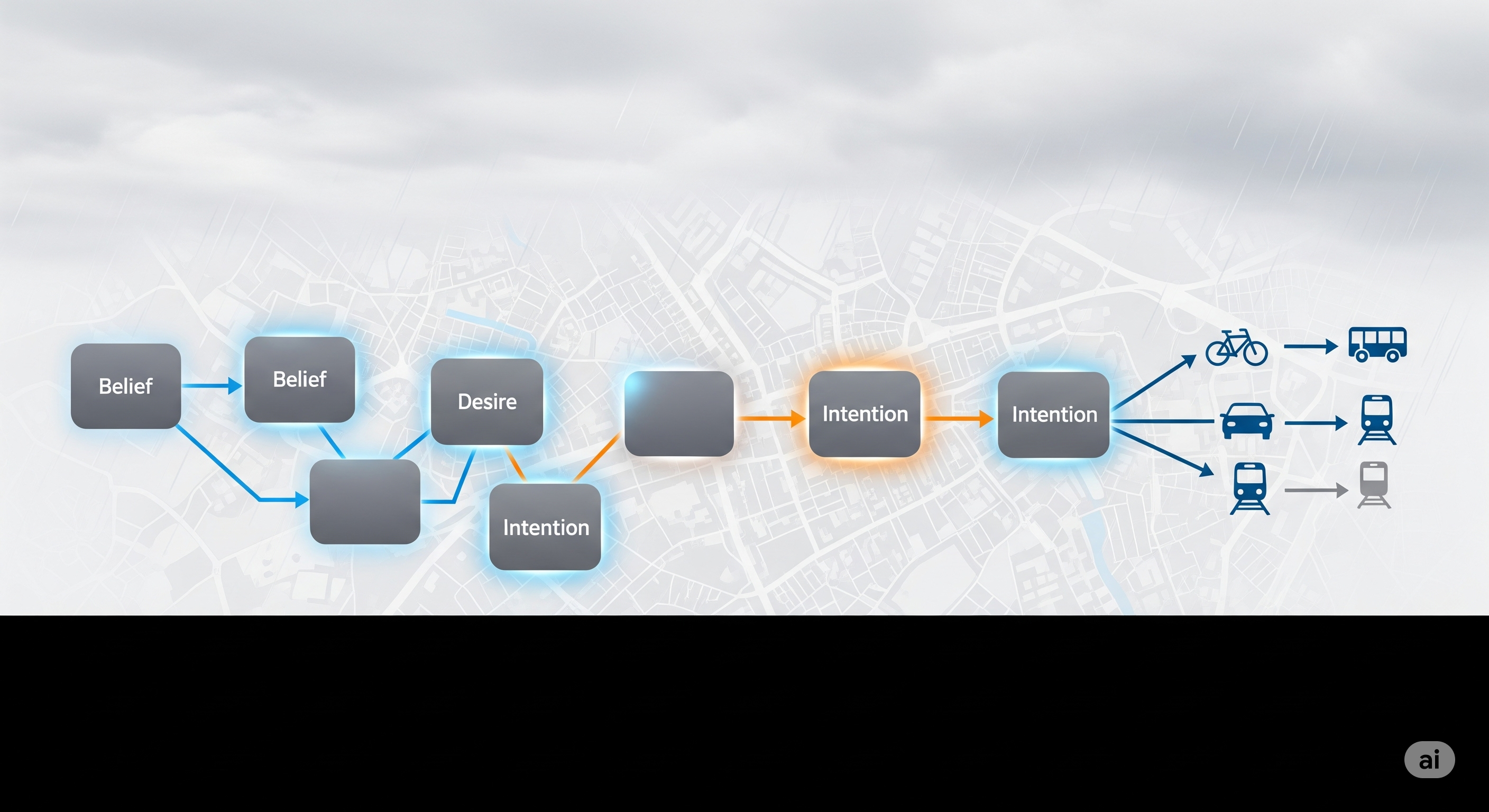
Traffic lights are not stupid. They are obedient. That is the problem. A fixed-time signal does exactly what it was told to do: hold this green for this long, clear the junction, move to the next phase, repeat. It does not care that one lane is empty, another is spilling backward, and a third has just received a platoon of vehicles from the previous intersection. It is not being malicious. It is merely following a plan designed for a world that stopped changing five minutes ago. ...