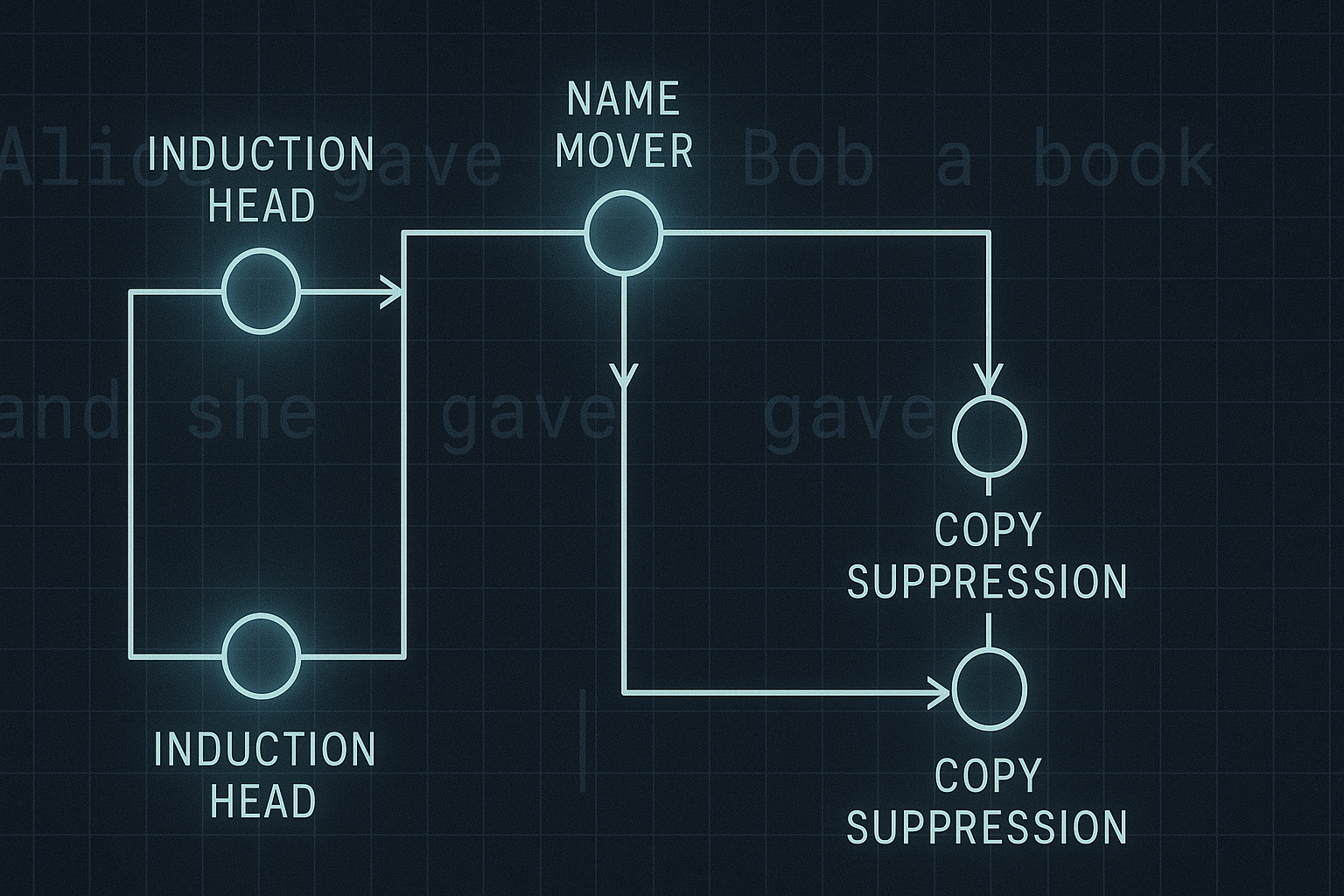
When Attention Learns to Breathe: Sparse Transformers for Sustainable Medical AI
When Attention Learns to Breathe: Sparse Transformers for Sustainable Medical AI Hospital AI does not fail only because models are inaccurate. It also fails because the input is messy, the compute budget is limited, the deployment environment is not a research lab, and the missing field in the patient record is somehow always the one the model wanted most. Elegant, really. ...