TL;DR for operators
Debugging. That is the useful mental entry point, not “AI transparency,” which has become a conference badge phrase with slightly better lighting.
The paper at the centre of this article, Interpretability in the Wild: a Circuit for Indirect Object Identification in GPT-2 small, shows that a real linguistic behaviour in a transformer can be decomposed into a circuit of internal components, then tested using causal interventions rather than admired through colourful attention maps.1 The task is indirect object identification: given a sentence where two names appear and one is repeated, the model predicts the other name. Small grammar problem, large interpretability bill.
What the paper directly shows is that GPT-2 small’s IOI behaviour can be explained by a circuit involving 26 attention heads grouped into seven functional classes. The explanation is not merely descriptive. The authors test it with criteria such as faithfulness, completeness, and minimality, asking whether the proposed circuit preserves the model’s behaviour, whether important components are missing, and whether included components are actually necessary.
What Cognaptus infers for business use is narrower, but more useful: mechanistic interpretability is best understood as a diagnostic discipline. It is not a dashboard that says “the model is safe.” It is a way to identify which internal pathways support a behaviour, which pathways compensate when others fail, and where an apparently simple output depends on surprisingly baroque internal plumbing. Enterprise AI teams should care because many operational failures do not come from the model “not knowing” something. They come from the model using the wrong internal route to get to a superficially acceptable answer.
What remains uncertain is scale. The result is compelling because it is concrete, but it is not a universal recipe for auditing large reasoning models, agentic systems, or multimodal workflows. GPT-2 small is not a regulated loan-underwriting stack. Shocking, yes.
Attention maps were never the proof
A familiar scene: an AI product fails in production, someone opens the logs, and the system’s explanation looks perfectly reasonable. The answer was wrong, but the explanation has posture. It contains steps, labels, and a confident little bridge from premise to conclusion. Everyone briefly feels better. They should not.
Most interpretability tools give us traces of influence: highlighted tokens, saliency scores, attention weights, attribution bars. These are useful, but they are not the same as a mechanism. They tell us where to look. They do not prove what computation was performed.
The IOI circuit paper matters because it pushes interpretability toward a stricter standard. Instead of asking, “Which tokens did the model attend to?” it asks something closer to: “Which components carry which information, through which route, and what happens if we remove or substitute them?” That is a much less glamorous question, which is usually a sign that engineering is about to begin.
The paper’s key move is not that it names attention heads. Naming parts is easy. Medieval medicine had names for things too. The value is that the authors combine circuit hypotheses with causal interventions: patching activations, ablating components, and checking whether the proposed internal machinery actually accounts for the model’s prediction.
The IOI task is small because the mechanism is the subject
Indirect object identification is a tidy linguistic benchmark. A typical prompt looks like:
When John and Mary went to the store, John gave a drink to
A competent model should predict “Mary,” not “John.” The repeated name is the subject; the non-repeated name is the indirect object. The model must track names, distinguish their grammatical roles, and output the right one.
Nobody should confuse this with full language understanding. The task is deliberately narrow. That narrowness is the point. Mechanistic interpretability needs cases where the behaviour is constrained enough that internal computations can be inspected without drowning in the model’s entire linguistic repertoire.
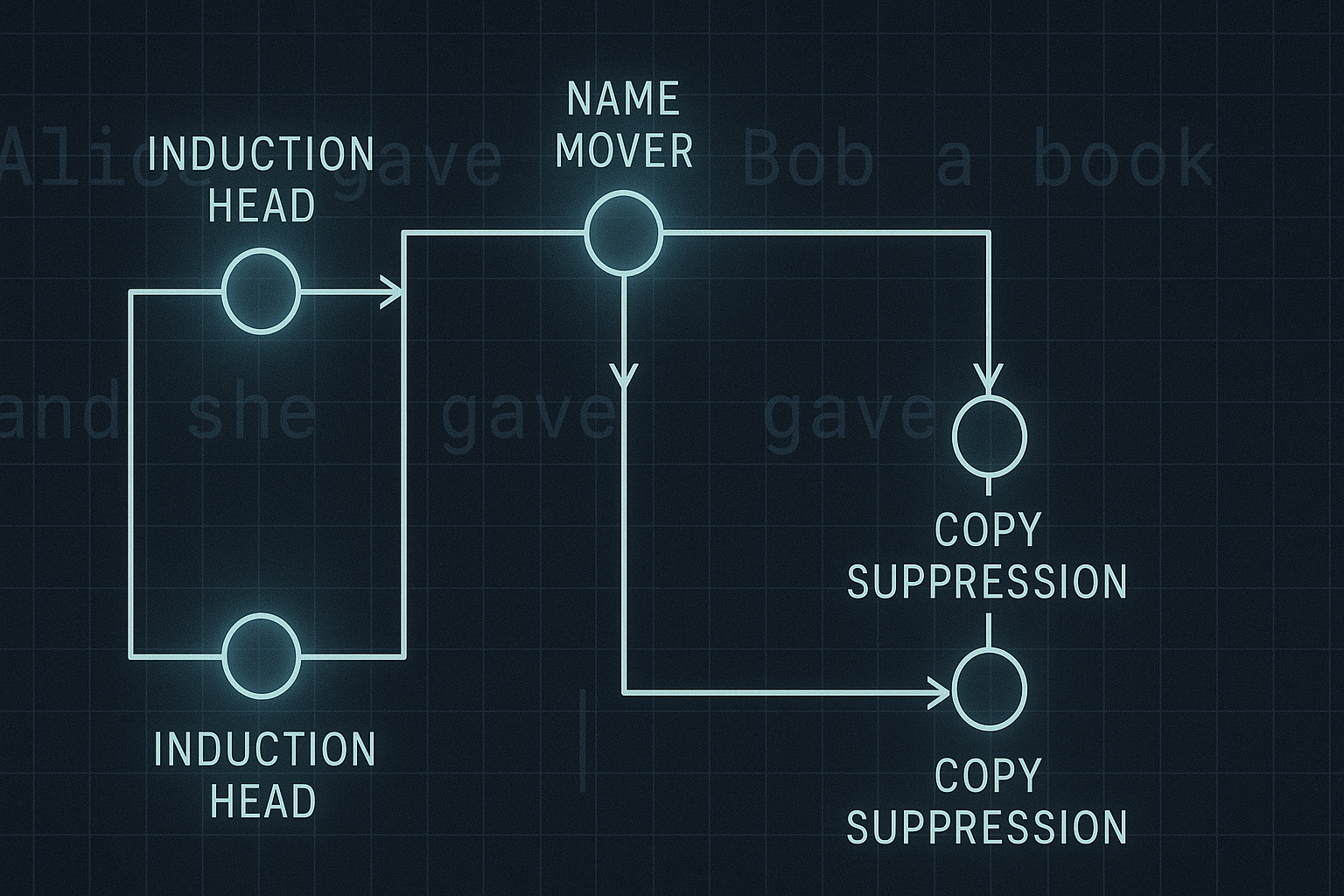
The paper studies GPT-2 small, a 12-layer transformer with 12 attention heads per layer. Out of this larger architecture, the authors identify a circuit of 26 attention heads grouped into seven main classes. In other words, the behaviour is not “the model” in some mystical holistic sense. It is implemented by a smaller, structured set of components interacting through the residual stream and attention pathways.
That is already an important correction to a common misconception. Mechanistic interpretability does not assume every parameter contributes equally to every answer. It looks for task-specific computational subgraphs: smaller mechanisms that explain specific behaviours. This circuit view builds on earlier transformer-circuits work, which treats transformer computations as compositions of attention heads, MLPs, residual streams, and logit-writing pathways rather than an undifferentiated neural fog.2
The circuit is a workflow, not a cast list
The easiest way to misunderstand the paper is to treat the seven head classes as a taxonomy chart. That is neat, but not sufficient. The circuit is not valuable because the heads have names. It is valuable because the names describe roles in an information-processing sequence.
A simplified version looks like this:
| Circuit role | What it contributes | Why it matters |
|---|---|---|
| Duplicate-token, previous-token, and induction heads | Detect repeated names and local token relationships | They help identify that one name has appeared again and should be treated differently from the non-repeated name |
| S-inhibition heads | Influence whether later heads attend to the repeated subject or the indirect object | They help suppress the wrong name as a copy target |
| Name mover heads | Copy the correct name toward the output logits | They are the direct route by which the indirect object becomes the predicted next token |
| Backup name mover heads | Provide alternative copying pathways when primary heads are disrupted | They reveal redundancy; ablating one path may not break the behaviour because the model has spare wiring |
| Negative name mover heads | Push in the opposite direction of ordinary name copying | They complicate simple “more attention means more contribution” stories |
This is where the paper becomes more interesting than the original elevator pitch. The model does not simply “look at Mary.” It performs a sequence of internal operations that identify repeated-token structure, route information through intermediate heads, suppress the subject, and copy the remaining name into the output direction.
For an operator, the backup and negative heads are the most instructive. Backup heads show why naive ablation can be misleading: remove one component and another may compensate, making the original component look less important than it really is. Negative heads show that internal components can contribute by subtraction, suppression, or countervailing effects. A model can be right because one component pushes toward the correct answer and another prevents the wrong answer from winning. That is not a slogan-friendly mechanism, but reality rarely is.
The evidence tests the explanation against damage
The paper’s important contribution is the evaluation logic. It does not merely propose a circuit. It asks whether the circuit survives tests designed to make bad explanations fail.
Three criteria carry the argument:
| Criterion | Question it asks | Operator translation |
|---|---|---|
| Faithfulness | Does the proposed circuit reproduce the relevant behaviour of the full model? | If we keep this circuit, do we preserve what matters? |
| Completeness | Are important causal components missing? | Are we ignoring a pathway that materially affects the behaviour? |
| Minimality | Are included components actually necessary? | Are we paying attention to decorative internals that do not earn their keep? |
These criteria matter because interpretability is vulnerable to pleasing stories. A circuit diagram can look persuasive while explaining the wrong thing, or explaining only the easiest part of the behaviour. Formal validation work in mechanistic interpretability makes the same point more generally: an interpretation should not merely match input-output behaviour, but should capture the computation in a compositional way across internal steps.3
The distinction is subtle and expensive. Suppose an explanation predicts the right final answer. That does not prove it used the same internal route as the model. Two mechanisms can be extensionally equivalent at the output while differing internally. For business use, that difference matters. If you are debugging a compliance model, a fraud-screening model, or an agentic workflow, a post-hoc explanation that lands on the right answer for the wrong reason is operationally close to decorative upholstery.
The IOI paper’s intervention methods are therefore central, not supplementary. Activation patching and ablation are attempts to answer causal questions: what changes when a component’s activation is replaced, removed, or routed differently? Later work on activation patching emphasizes why these details matter: choices of metric, corruption method, and patching setup can materially change the interpretability conclusion.4 The method is powerful, but it is not a vending machine. Insert activations, receive truth. If only.
Magnitude: 26 heads is both small and not small
The phrase “26 attention heads” can mislead in both directions.
On one hand, 26 heads out of GPT-2 small’s 144 attention heads is a compact mechanism. The paper shows that a nontrivial natural-language behaviour can be localized to a structured subset of the model. This is the optimistic reading: transformer computation is not entirely amorphous; there are discoverable circuits with interpretable roles.
On the other hand, 26 heads is not exactly pocket-sized. The task is narrow, the model is small by modern standards, and the circuit still requires multiple functional classes, path dependencies, compensation effects, and negative contributors. This is the sober reading: even a toy-adjacent grammar behaviour is already complicated enough to embarrass anyone promising push-button transparency.
The useful conclusion sits between those extremes. Mechanistic interpretability is feasible enough to be worth building around, but hard enough that most enterprise “explainability” wrappers are not doing it. A token attribution bar is not a circuit. A chain-of-thought explanation is not a mechanism. A model saying “because” is not evidence that it actually used the reason it just narrated. We have all met humans with the same defect; machines merely industrialized it.
The IOI work also clarifies why interpretability has to be causal. Attention patterns alone can show where information might move. They cannot prove which pathway is necessary for the final prediction. The paper’s circuit gains credibility because the authors test interventions along the path from early duplicate-token recognition to later name moving. The interpretation is progressively constrained by evidence.
Formalization turns interpretability into an engineering discipline
The broader field has been moving from hand-inspected circuits toward more systematic methods. That progression is important for anyone hoping to use interpretability outside a research lab.
At the foundation, transformer-circuits work gives analysts a vocabulary for describing computation: attention heads read from and write to residual streams; QK circuits decide where information is read from; OV circuits decide what is written forward; induction heads implement recognizable sequence-copying behaviours.2 This vocabulary is not enough by itself, but without it the discussion collapses into “the model attended to X,” which is how serious analysis goes to die quietly.
The IOI paper then supplies a concrete end-to-end case: a real pretrained model, a real language task, and a proposed circuit evaluated through causal interventions.1 It demonstrates that circuit-level explanations can be more than toy demonstrations.
Formal validation work adds a stricter layer. If an interpretation claims to be a simplified algorithm implemented by a neural network, then it should satisfy constraints about how each part of that interpretation corresponds to the model’s internal computation.3 This is the beginning of interpretability as specification, not storytelling.
Automated circuit discovery pushes the same agenda from another angle. Manual circuit work is expensive and researcher-intensive. Automated methods try to identify relevant subgraphs by pruning or searching through the model’s computational graph while preserving task behaviour.5 They are not a replacement for judgement, but they are a response to the obvious scaling problem: humans cannot lovingly hand-label every pathway in frontier models unless civilization has decided to become very boring.
What the paper shows, what operators can infer, and what remains open
The business interpretation should be disciplined. The paper is not a compliance framework. It is not a model-risk checklist. It is not a certificate saying transformers are now understood. It is a research demonstration with operational implications.
| Layer | Claim | Confidence |
|---|---|---|
| Direct paper result | GPT-2 small’s IOI behaviour can be explained by a 26-head circuit grouped into functional classes and tested with causal interventions | Strong within the studied task and model |
| Cognaptus inference | Circuit-level interpretability can support deeper debugging than output-level explanations or token attribution | Reasonable, especially for narrow, repeatable behaviours |
| Business implication | High-risk AI workflows should distinguish explanation aesthetics from causal diagnosis | Strong as a governance principle |
| Remaining uncertainty | Whether comparable circuit-level understanding can scale to frontier models, long-horizon agent behaviour, and messy enterprise tasks | Open |
This separation matters because AI vendors have a charming habit of turning research direction into product capability before the ink dries. The IOI paper does not say, “Deploy mechanistic interpretability across your enterprise stack by Tuesday.” It says something more useful: if you want to understand a model behaviour, you need a falsifiable circuit hypothesis and interventions that can break or preserve that behaviour in predicted ways.
For business teams, this reframes the role of interpretability in three ways.
First, it is a diagnostic tool for failure analysis. When an AI system produces a harmful output, the operational question is not only what prompt caused it, but which internal features and pathways supported it. That matters for remediation. Prompt changes are surface edits; circuit diagnosis can reveal whether the behaviour is localized, redundant, or deeply entangled.
Second, it is a way to evaluate robustness of control. Backup pathways matter. A system may appear fixed after one behaviour is suppressed, while another internal route can recreate it under slightly different conditions. This is the model equivalent of painting over mould. Very clean, until it returns.
Third, it provides a better standard for audit language. “The model explanation said X” is weak evidence. “A causal intervention on the identified pathway changed the relevant output in the predicted direction” is stronger. Still not magical, but at least it is the beginning of adult supervision.
The limits are not footnotes; they define the use case
The IOI result is impressive because it is narrow. The same property limits its immediate business translation.
The task is highly specific. Indirect object identification is a clean linguistic pattern, not a multi-document legal review, a procurement negotiation, or an autonomous workflow spanning APIs and human approvals. Circuit methods work best when the behaviour can be elicited reliably and measured with a clear metric. Many enterprise tasks are messier: the success criterion is ambiguous, the input distribution shifts, and the model may use different strategies across contexts.
The model is also small by contemporary standards. GPT-2 small is useful as an interpretability laboratory, not because it resembles the systems most companies now deploy. Larger models may contain analogous mechanisms, but they may also use more distributed representations, more redundancy, and more task-dependent routing. The field’s practical review literature is clear that mechanistic interpretability has produced valuable insights while still facing major challenges in scalability, evaluation, and generalization.6
The analysis also focuses heavily on attention heads. That makes sense for IOI, where attention-mediated copying is central. But modern transformer behaviour often depends on MLPs, residual-stream features, learned representations, and interactions that are harder to map with head-level taxonomies alone. Sparse feature methods and causal abstraction approaches help, but they bring their own assumptions and failure modes.
Finally, a validated circuit for one behaviour is not a global model explanation. It does not tell us everything GPT-2 small knows, believes, or might do under adversarial prompting. It tells us something precise about one behaviour under one distribution. That precision is the strength. Overextending it would be the usual human contribution to the error budget.
The practical lesson is cheaper diagnosis, not instant trust
The most valuable lesson from the IOI circuit work is not that transformers can be made transparent in some broad philosophical sense. The valuable lesson is more concrete: understanding should be treated as an engineering claim that can be tested.
A good circuit explanation should identify components, describe their roles, predict how interventions will affect behaviour, and survive attempts to falsify it. If it cannot do those things, it may still be a useful visualization. It is not yet understanding.
For companies building with AI, this changes the interpretability conversation. The question is not whether a model can generate a plausible explanation for its answer. It is whether the organization has any way to inspect the causal machinery behind behaviours that matter: unsafe refusals, policy violations, hallucinated citations, brittle tool use, hidden shortcuts, or compliance-sensitive classifications.
Mechanistic interpretability will not replace monitoring, evaluation, red teaming, or governance. It will sit underneath them as a deeper diagnostic layer for cases where surface behaviour is not enough. That is less glamorous than “glass-box AI,” but more useful. Glass boxes shatter. Circuits can at least be tested.
The paper gives us a formal path in the modest, important sense: move from observation to hypothesis, from hypothesis to circuit, from circuit to intervention, and from intervention to quantified evidence. Not omniscience. Not trust on demand. Just a better way to stop pretending that a model’s explanation and a model’s mechanism are the same thing.
Cognaptus: Automate the Present, Incubate the Future.
-
Kevin Wang, Alexandre Variengien, Arthur Conmy, Buck Shlegeris, and Jacob Steinhardt, “Interpretability in the Wild: a Circuit for Indirect Object Identification in GPT-2 small,” arXiv:2211.00593, 2022, https://arxiv.org/abs/2211.00593. ↩︎ ↩︎
-
Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, et al., “A Mathematical Framework for Transformer Circuits,” Transformer Circuits Thread, 2021, https://transformer-circuits.pub/2021/framework/index.html. ↩︎ ↩︎
-
Nils Palumbo, Ravi Mangal, Zifan Wang, Saranya Vijayakumar, Corina S. Pasareanu, and Somesh Jha, “Validating Mechanistic Interpretations: An Axiomatic Approach,” arXiv:2407.13594, 2024/2025, https://arxiv.org/abs/2407.13594. ↩︎ ↩︎
-
Fred Zhang and Neel Nanda, “Towards Best Practices of Activation Patching in Language Models: Metrics and Methods,” arXiv:2309.16042, 2023, https://arxiv.org/abs/2309.16042. ↩︎
-
Arthur Conmy, Augustine N. Mavor-Parker, Aengus Lynch, Stefan Heimersheim, and Adrià Garriga-Alonso, “Towards Automated Circuit Discovery for Mechanistic Interpretability,” arXiv:2304.14997, 2023, https://arxiv.org/abs/2304.14997. ↩︎
-
Daking Rai, Yilun Zhou, Shi Feng, Abulhair Saparov, and Ziyu Yao, “A Practical Review of Mechanistic Interpretability for Transformer-Based Language Models,” arXiv:2407.02646, 2024, https://arxiv.org/abs/2407.02646. ↩︎